This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
I got the chance to apply those techniques to ConversationalAI products across multiple domains. Artificial intelligence solutions are transforming businesses across all industries, and we at LXT are honored to provide the high-qualitydata to train the machine learning algorithms that power them.
It requires careful curation of knowledge representations in database, decomposition of data matrices to reduce dimensionality, and pre-processing of datasets to mitigate the confounding effects of missing, redundant and outlier data. But insurers should contribute their insurance domain expertise to AI technologies development.
For example, AI can analyse past purchases and browsing history to recommend products or services which are most likely to interest the customer. This tailored approach increases the likelihood of engagement and conversion. AI-driven personalisation can be particularly powerful in B2B sales.
Every episode is focused on one specific ML topic, and during this one, we talked to Jason Falks about deploying conversationalAI products to production. Today, we have Jason Flaks with us, and we’ll be talking about deploying conversationalAI products to production. What is conversationalAI?
The exploding popularity of conversationalAI tools has also raised serious concerns about AI safety. The advent of RLHF fine-tuning has arguably revolutionized conversationalAI. Unraveling the exact scaling laws that govern the balance between demonstration data and RLHF or similar techniques (e.g.
The evaluation of BARE focuses on diversity, dataquality, and downstream performance across the same domains and baselines discussed earlier. 70B-Instruct for refinement, BARE maintains data diversity while improving generation quality. Implementing Llama-3.1-70B-Base 70B-Base for initial generation and Llama-3.1-70B-Instruct
Code generation models have made remarkable progress through increased computational power and improved training dataquality. These models undergo pre-training and supervised fine-tuning (SFT) using extensive coding data from web sources. State-of-the-art models like Code-Llama, Qwen2.5-Coder,
Legacy systems often lack comprehensive documentation, hindering the ability of AI to grasp their interdependencies effectively. DataQuality and Bias: The quality and representativeness of data used to train the AI model have a significant impact on its output.
AI Chatbots The banking sector has started to use AI and ML (machine learning) significantly, with chatbots being one of the most popular applications. Chatbots, along with conversationalAI , can provide customer support, handle customer queries, and even process transactions.
Among AI technologies, search engines, speech & voice recognition, and computer vision lead in deployment across industries, illustrating the diverse applications of AI in enhancing user interaction, processing information, and interpreting visual data.
These difficulties often arise due to limitations in dataquality, model architecture, and the scalability of training processes. The need for open-data reasoning models that perform at a high level is increasingly important, especially as proprietary models continue to lead the field.
Machine learning to identify emerging patterns in complaint data and solve widespread issues faster. However, banks may encounter roadblocks when integrating AI into their complaint-handling process. Banks cannot send their sensitive customer data to crowd labelers or to third-party models without compromising security.
You’ll see a demonstration of how to use an effective control layer to help you train LLMs using a suite of open-source solutions, and scale these to true enterprise production levels while controlling costs and improving dataquality.
Machine learning to identify emerging patterns in complaint data and solve widespread issues faster. However, banks may encounter roadblocks when integrating AI into their complaint-handling process. Banks cannot send their sensitive customer data to crowd labelers or to third-party models without compromising security.
Machine learning to identify emerging patterns in complaint data and solve widespread issues faster. However, banks may encounter roadblocks when integrating AI into their complaint-handling process. Banks cannot send their sensitive customer data to crowd labelers or to third-party models without compromising security.
Machine learning to identify emerging patterns in complaint data and solve widespread issues faster. However, banks may encounter roadblocks when integrating AI into their complaint-handling process. Banks cannot send their sensitive customer data to crowd labelers or to third-party models without compromising security.
Artificial intelligence (AI) is accelerating at an astonishing pace, quickly moving from emerging technologies to impacting how businesses run. From building AI agents to interacting with technology in ways that feel more like a natural conversation, AI technologies are poised to transform how we work.
People rely on conversationalAI and virtual assistants to do anything from purchasing a trip to scheduling a doctor’s appointment in the present digital environment. AI chatbots replace first-level support agents at the modern service desk. Automation rules today’s world.
Don’t rush AI implementations driven by hype and without market-side validation. User value : Define, quantify, and communicate the value of AI products in terms of efficiency, personalization, convenience, and other dimensions of value. Dataquality : Focus on dataquality and relevance to train AI models effectively.
Instead of treating all responses as either correct or wrong, Lora Aroyo introduced “truth by disagreement”, an approach of distributional truth for assessing reliability of data by harnessing rater disagreement. Dataquality is difficult even with experts because experts disagree as much as crowd labers.
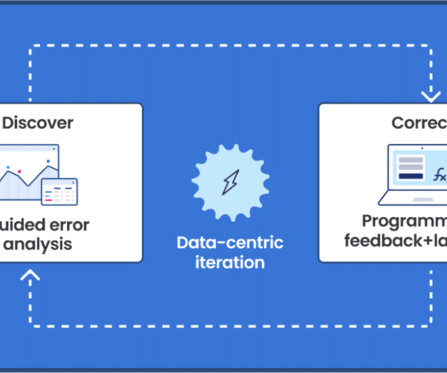
Kishore will then double click into some of the opportunities we find here at Capital One, and Bayan will finish us off with a lean into one of our open-source solutions that really is an important contribution to our data-centric AI community. The same applies for buying a car with Capital One.
Kishore will then double click into some of the opportunities we find here at Capital One, and Bayan will finish us off with a lean into one of our open-source solutions that really is an important contribution to our data-centric AI community. The same applies for buying a car with Capital One.
The Llama 2-Chat used a binary comparison protocol to collect human preference data, marking a notable trend towards more qualitative approaches. This mechanism informed the Reward Models, which are then used to fine-tune the conversationalAI model. Dataquality and diversity are just as pivotal as volume in these scenarios.
Existing open-source alternatives often lag behind in performance due to limitations in dataquality, training techniques, and computational efficiency. However, these models are closed-source, limiting accessibility and customization for researchers and developers.
Those pillars are 1) benchmarks—ways of measuring everything from speed to accuracy, to dataquality, to efficiency, 2) best practices—standard processes and means of inter-operating various tools, and most importantly to this discussion, 3) data. In order to do this, we need to get better at measuring dataquality.
Those pillars are 1) benchmarks—ways of measuring everything from speed to accuracy, to dataquality, to efficiency, 2) best practices—standard processes and means of inter-operating various tools, and most importantly to this discussion, 3) data. In order to do this, we need to get better at measuring dataquality.
AI has made significant strides in developing large language models (LLMs) that excel in complex tasks such as text generation, summarization, and conversationalAI. Models like LaPM 540B and Llama-3.1
Less training data : dataquality scales better than data size [3] — the more focussed and curated your training data, the less of it is needed to optimise performance. Email Address * Name * First Last Company * What areas of AI research are you interested in?
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














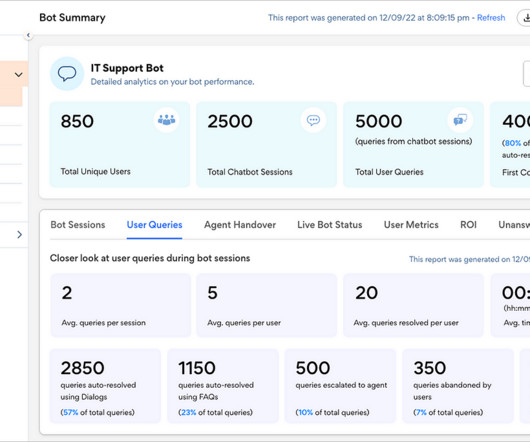
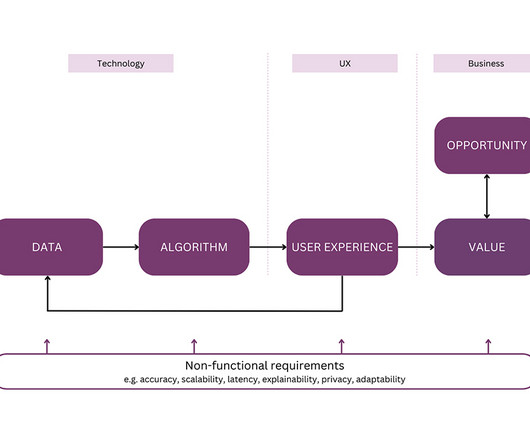
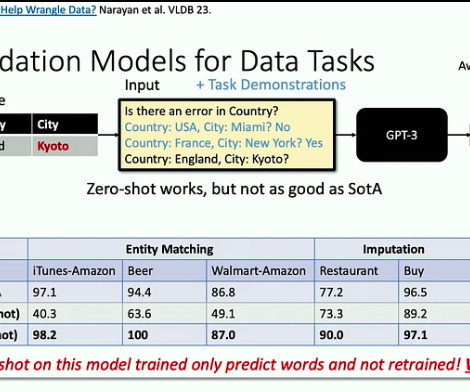







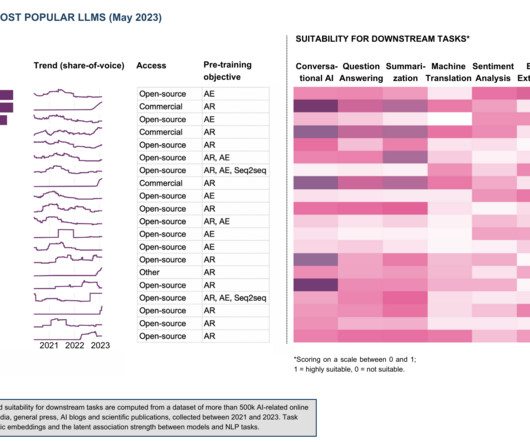






Let's personalize your content