This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
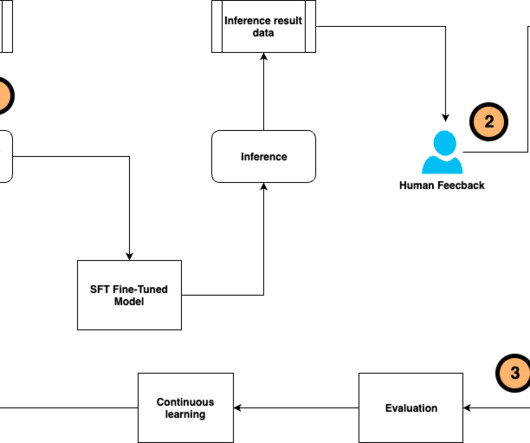
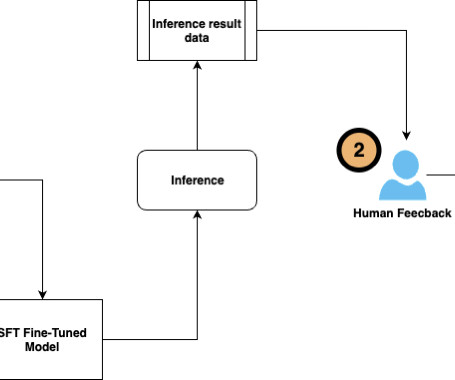
Fine-tuning a pre-trained large language model (LLM) allows users to customize the model to perform better on domain-specific tasks or align more closely with human preferences. Continuous fine-tuning also enables models to integrate human feedback, address errors, and tailor to real-world applications.
” He notes it’s powered by “a compound AI system that continuouslylearns from usage across an organisation’s entire data stack, including ETL pipelines, lineage, and other queries.”
To increase training samples for better learning, we also used another LLM to generate feedback scores. We present the reinforcement learning process and the benchmarking results to demonstrate the LLM performance improvement. of overall responses) can be addressed by user education and promptengineering.
Synthetic Data Generation: Prompt the LLM with the designed prompts to generate hundreds of thousands of (query, document) pairs covering a wide variety of semantic tasks across 93 languages. Model Training: Fine-tune a powerful open-source LLM such as Mistral on the synthetic data using contrastive loss.
We discuss the potential and limitations of continuouslearning in foundation models. The engineering section dives into another awesome framework and we discuss large action models in our research edition. By continual pre-training on Hephaestus-Forge, the resulting model, Hephaestus, shows improved agentic capabilities.
LLM & Agents : At the core, the LLM processes these inputs, collaborating with specialized agents like Auto-GPT for thought chaining, AgentGPT for web-specific tasks, BabyAGI for task-specific actions, and HuggingGPT for team-based processing. ” BabyAGI responded with a well-thought-out plan.
How Reinforcement Learning Enhances Reasoning in LLMs How Reinforcement Learning Works in LLMs Reinforcement Learning is a machine learning paradigm in which an agent (in this case, an LLM) interacts with an environment (for instance, a complex problem) to maximize a cumulative reward.
Generative AI & LLM Applications: A new category focused on leveraging pre-built AI models for automation and augmentation. While these technologies are changing how organizations approach problem-solving, he cautions that they dont replace traditional machine learning or data science workflows.
It’s built on diverse data sources and a robust infrastructure layer for data retrieval, prompting, and LLM management. The following diagram illustrates the prompting framework for Account Summaries, which begins by gathering data from various sources. Role context – Start each prompt with a clear role definition.
While traditional roles like data scientists and machine learningengineers remain essential, new positions like large language model (LLM) engineers and promptengineers have gained traction. Machine learning and LLM modeling have joined this list as foundational skills.
TL;DR In 2023, the tech industry saw waves of layoffs, which will likely continue into 2024. Due to the rise of LLMs and the shift towards pre-trained models and promptengineering, specialists in traditional NLP approaches are particularly at risk.
ContinuedLearning and Adaptability The model is designed to learn and adapt from its interactions, which means it can continuously improve and refine its responses over time. The next opportunity is provided by the web platform Ora.sh, which facilitates the quick development of LLM apps within a shareable chat interface.
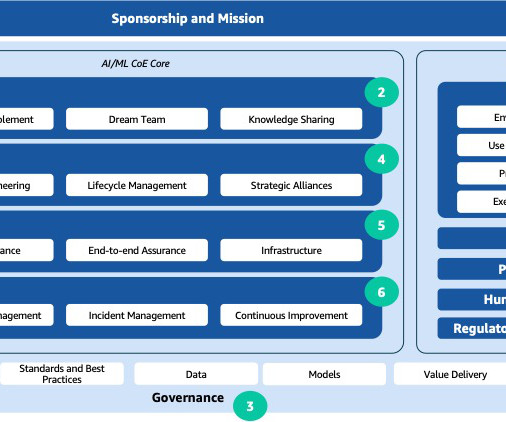
This includes implementation of industry best practice measures and industry frameworks, such as NIST , OWASP-LLM , OWASP-ML , MITRE Atlas. Stay tuned as we continue to explore the AI/ML CoE topics in our upcoming posts in this series. If you need help establishing an AI/ML Center of Excellence, please reach out to a specialist.
These agents can break down complicated, multi-step tasks into branched solutions, and are capable of evaluating the generated solutions dynamically while continuallylearning from past experiences. Examples include our Deep Researcher, Deep Coder, and Advisor models.
This post is meant to walk through some of the steps of how to take your LLMs to the next level, focusing on critical aspects like LLMOps, advanced promptengineering, and cloud-based deployments. I always start by creating a Docker image of my LLM service. All are welcome.
The key to their success lay in the innovative application of promptengineering techniques—a set of strategies designed to coax the best performance out of LLMs, especially important for cost effective models. By carefully crafting prompts, we can provide context and structure that helps mitigate this variability.
Generating improved instructions for each question-and-answer pair using an automatic promptengineering technique based on the Auto-Instruct Repository. Their AI vision is to provide their customers with an active system that continuouslylearns from customer behaviors and optimizes engagement in real time.
ICAL outperforms state-of-the-art models in tasks like instruction following, web navigation, and action forecasting, demonstrating its ability to improve performance without heavy manual promptengineering. Is Your LiDAR Placement Optimized for 3D Scene Understanding?
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content