This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
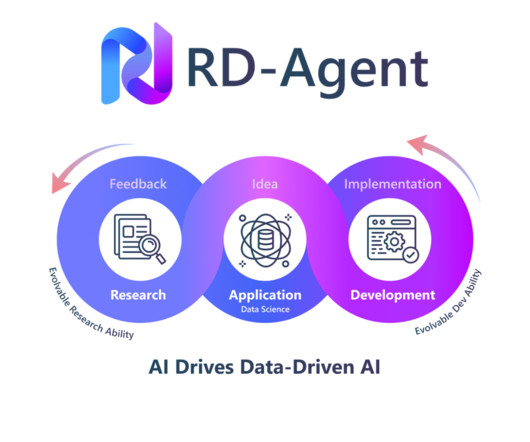
The system continuously improves through iterative refinement. RD-Agent functions as both a research assistant and a data-mining agent, automating tasks like reading papers, identifying financial and healthcare data patterns, and optimizing feature engineering.
This cutting-edge tool eliminates repetitive manual tasks, allowing researchers, data scientists, and engineers to streamline workflows, propose new ideas, and implement complex models more efficiently. Like most AI-driven initiatives, the system continually improves through feedback, increasing its utility and relevance.
The Cyber Assistant learns from analyst decisions, then retains the intellectual capital and learned behaviors to make recommendations and help reduce false positives. QRadar EDR’s Cyber Assistant has helped reduce the number of false positives by 90%, on average. [1]
The Future of ARM: ContinuousLearning and Evolving Applications As the data deluge continues unabated, association rule mining (ARM) stands poised to play an even more pivotal role in the future. Frequently Asked Questions What is the Difference Between Association Rule Mining and Other DataMining Techniques?
This is NLP in action, continuouslylearning from your typing habits to make real-time predictions and enhance your typing experience. DataMining & Analysis The digital world generates colossal amounts of data daily. Can businesses benefit from NLP? Absolutely! What are some NLP examples in daily life?
Synergy Between Artificial Intelligence and Data Science AI and Data Science complement each other through their unique but interconnected roles in data processing and analysis. Data Science involves extracting insights from structured and unstructured data using statistical methods, datamining, and visualisation techniques.
In the context of NLP and Machine Learning, this means identifying sentence structures, recurring phrases, or even the sentiment behind texts. ContinuousLearning : As ML models are exposed to more data, they refine their understanding, making them proficient at handling nuances and exceptions in language processing.
Thus, it focuses on providing all the fundamental concepts of Data Science and light concepts of Machine Learning, Artificial Intelligence, programming languages and others. Usually, a Data Science course comprises topics on statistical analysis, data visualization, datamining and data preprocessing.
The primary goal of an IR system is to bridge the gap between the user’s information needs and the available data by providing timely and accurate results. ContinuousLearning and Adaptation Update the index and ranking algorithms as new documents are added to the collection.
Unlike traditional CI tools that require manual input and analysis, Agentic Systems automate these processes, allowing businesses to access real-time insights without the need for continuous human oversight.
This includes tracking performance metrics and detecting potential instances of concept and data drift. On the other hand, Scikit-multiflow is a multi-output/multi-label and stream datamining library for Python. It provides tools and algorithms for data stream processing, which can help in drift detection.
Key subjects often encompass: Statistics and Probability: Students learn statistical techniques for Data Analysis, including hypothesis testing and regression analysis, which are crucial for making data-driven decisions. Students must commit to continuouslearning to stay relevant and competitive.
Incremental Learning It supports incremental learning, where it can continuouslylearn from new data without losing the knowledge of previously learned patterns. It only requires a memory search during prediction, making it faster for inference.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content