This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
You can also supply a custom metadata file (each up to 10 KB) for each document in the knowledge base. You can apply filters to your retrievals, instructing the vector store to pre-filter based on document metadata and then search for relevant documents. Reranking allows GraphRAG to refine and optimize search results.
For this demo, weve implemented metadata filtering to retrieve only the appropriate level of documents based on the users access level, further enhancing efficiency and security. The role information is also used to configure metadata filtering in the knowledge bases to generate relevant responses.
It stores models, organizes model versions, captures essential metadata and artifacts such as container images, and governs the approval status of each model. About the Authors Alston Chan is a SoftwareDevelopment Engineer at Amazon Ads. Outside of work, he enjoys game development and rock climbing.
Every episode is focused on one specific ML topic, and during this one, we talked to Michal Tadeusiak about managing computervision projects. I’m joined by my co-host, Stephen, and with us today, we have Michal Tadeusiak , who will be answering questions about managing computervision projects.
By using accelerated data processing, autonomous vehicle softwaredevelopers ensure they can reach a high-performance standard to avoid traffic accidents, lower transportation costs and improve mobility for users. However, the value of this imagery can be limited if it lacks specific location metadata.
Voxel51 is the company behind FiftyOne, the open-source toolkit for building high-quality datasets and computervision models. FiftyOne by Voxel51 is an open-source toolkit for curating, visualizing, and evaluating computervision datasets so that you can train and analyze better models by accelerating your use cases.
You can use state-of-the-art model architecturessuch as language models, computervision models, and morewithout having to build them from scratch. Repository Information**: Not shown in the provided excerpt, but likely contains metadata about the repository.
a softwaredeveloper with a machine learning background ready to join in California), the candidates are ranked based on their experience with machine learning and expertise as a softwaredeveloper, similarity of their work, living in California, and likelihood that they will respond to the job description.
The examples focus on questions on chunk-wise business knowledge while ignoring irrelevant metadata that might be contained in a chunk. He has touched on most aspects of these projects, from infrastructure and DevOps to softwaredevelopment and AI/ML. You can customize the prompt examples to fit your ground truth use case.
He previously worked in the semiconductor industry developing large computervision (CV) and natural language processing (NLP) models to improve semiconductor processes. SoftwareDevelopment Engineer with Amazon Stores. In his free time, he enjoys playing chess and traveling. Nishant Krishnamoorthy is a Sr.
As an example, smart venue solutions can use near-real-time computervision for crowd analytics over 5G networks, all while minimizing investment in on-premises hardware networking equipment. JumpStart provides access to hundreds of built-in algorithms with pre-trained models that can be seamlessly deployed to SageMaker endpoints.
Start by using the following code to download the PDF documents from the provided URLs and create a list of metadata for each downloaded document. !mkdir She has over 15 years of IT experience in softwaredevelopment, design and architecture. She is passionate about data-driven AI and the area of depth in ML and generative AI.
The coefficients for correcting to at-sensor reflectance are provided in the scene metadata, which further improves the consistency between images taken at different times. Access Planet data To help users get accurate and actionable data faster, Planet has also developed the Planet SoftwareDevelopment Kit (SDK) for Python.
It stores models, organizes model versions, captures essential metadata and artifacts such as container images, and governs the approval status of each model. Alston Chan is a SoftwareDevelopment Engineer at Amazon Ads. Outside of work, he enjoys game development and rock climbing.
We will unravel the magic inside DepthAI API that allows various computervision and deep learning applications to run on the OAK device. Finally, we will run a few computervision and deep learning examples on the OAK-D device using the pre-trained public models from the OpenVino model zoo.
When the automated content processing steps are complete, you can use the output for downstream tasks, such as to invoke different components in a customer service backend application, or to insert the generated tags into metadata of each document for product recommendation.
Given the right context, metadata, and instructions, a well-selected general purpose LLM can produce good-quality SQL as long as it has access to the right domain-specific context. She leads machine learning (ML) projects in various domains such as computervision, natural language processing and generative AI.
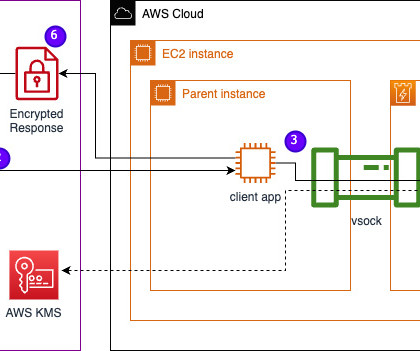
Clone the GitHub project: cd ~/ && git clone [link] Navigate to the project folder to build the enclave_base Docker image that contains the Nitro Enclaves SoftwareDevelopment Kit (SDK) for cryptographic attestation documents from the Nitro Hypervisor (this step can take up to 15 minutes): cd /nitro_llm/enclave_base docker build./ -t
In this blog post, we explore a comprehensive approach to time series forecasting using the Amazon SageMaker AutoMLV2 SoftwareDevelopment Kit (SDK). All other columns in the dataset are optional and can be used to include additional time-series related information or metadata about each item.
The more detailed AI ToolSuite requirements were driven by three example use cases: Develop a computervision application aimed at object detection at the edge. He has over 12 years of work experience as a data scientist, machine learning practitioner, and softwaredeveloper.
Building on years of experience in deploying ML and computervision to address complex challenges, Syngenta introduced applications like NemaDigital, Moth Counter, and Productivity Zones. Efficient metadata storage with Amazon DynamoDB – To support quick and efficient data retrieval, document metadata is stored in Amazon DynamoDB.
This emergent ability in LLMs has compelled softwaredevelopers to use LLMs as an automation and UX enhancement tool that transforms natural language to a domain-specific language (DSL): system instructions, API requests, code artifacts, and more. In his spare time, Clay enjoys skiing, solving Rubik’s cubes, reading, and cooking.
To make that possible, your data scientists would need to store enough details about the environment the model was created in and the related metadata so that the model could be recreated with the same or similar outcomes. Version control for code is common in softwaredevelopment, and the problem is mostly solved.
format that SageMaker Inference is expecting: model.joblib – For this implementation, we directly push the model metadata into the tarball. James’s work covers a wide range of ML use cases, with a primary interest in computervision, deep learning, and scaling ML across the enterprise.
For example, input images for an object detection use case might need to be resized or cropped before being served to a computervision model, or tokenization of text inputs before being used in an LLM. However, in addition to model invocation, those DL application often entail preprocessing or postprocessing in an inference pipeline.
Fine-tuning process and human validation The fine-tuning and validation process consisted of the following steps: Gathering a malware dataset To cover the breadth of malware techniques, families, and threat types, we collected a large dataset of malware samples, each with technical metadata.
Common patterns for filtering data include: Filtering on metadata such as the document name or URL. Name: Bill GatesnBorn: October 28, 1955 (age 66)nEducation: Harvard University (dropped out)nOccupation: Softwaredeveloper, investor, entrepreneurnSource: WikipedianTime: August 2022 Question: What is Bill Gatess occupation?
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content