This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The SEER model by Facebook AI aims at maximizing the capabilities of self-supervised learning in the field of computervision. The Need for Self-Supervised Learning in ComputerVision Data annotation or data labeling is a pre-processing stage in the development of machine learning & artificial intelligence models.
Image recognition neuralnetworks are only as good as the data they’re trained on. But a set of training data released today by machine learning benchmarking organization MLCommons makes the image recognition neuralnetwork ResNet more than 50 percent more accurate. You can see the problem below. It’s terrible.
As an Edge AI implementation, TensorFlow Lite greatly reduces the barriers to introducing large-scale computervision with on-device machine learning, making it possible to run machine learning everywhere. About us: At viso.ai, we power the most comprehensive computervision platform Viso Suite. What is TensorFlow?
Companies also take advantage of ML in smartphone cameras to analyze and enhance photos using image classifiers, detect objects (or faces) in the images, and even use artificial neuralnetworks to enhance or expand a photo by predicting what lies beyond its borders. Computervision guides self-driving cars.
Artificial Intelligence is a very vast branch in itself with numerous subfields including deep learning, computervision , natural language processing , and more. The neuralnetwork consists of three types of layers including the hidden layer, the input payer, and the output layer.
In recent years, there have been exceptional advancements in Artificial Intelligence, with many new advanced models being introduced, especially in NLP and ComputerVision. CLIP is a neuralnetwork developed by OpenAI trained on a massive dataset of text and image pairs.
Participants learn to build metadata for documents containing text and images, retrieve relevant text chunks, and print citations using Multimodal RAG with Gemini. It covers how to develop NLP projects using neuralnetworks with Vertex AI and TensorFlow.
Table of Contents OAK-D: Understanding and Running NeuralNetwork Inference with DepthAI API Introduction Configuring Your Development Environment Having Problems Configuring Your Development Environment? Its goal is to combine and optimize five key attributes: Deep Learning, ComputerVision, Depth perception, Performance (e.g.,
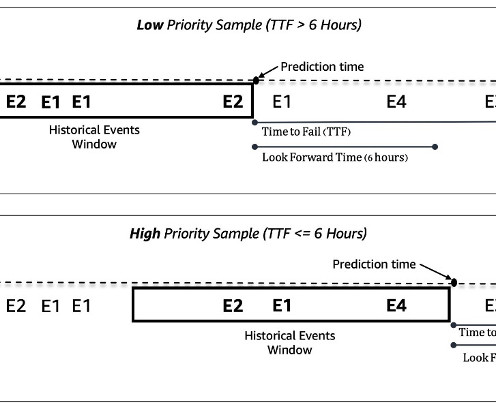
The final ML model combines CNN and Transformer, which are the state-of-the-art neuralnetwork architectures for modeling sequential machine log data. The ML model takes in the historical sequence of machine events and other metadata and predicts whether a machine will encounter a failure in a 6-hour future time window.
Jump Right To The Downloads Section People Counter on OAK Introduction People counting is a cutting-edge application within computervision, focusing on accurately determining the number of individuals in a particular area or moving in specific directions, such as “entering” or “exiting.” Looking for the source code to this post?
The primary challenge lies in developing a single neuralnetwork capable of handling a broad spectrum of tasks and modalities while maintaining high performance across all domains. The approach incorporates over 20 modalities, including SAM segments, 3D human poses, Canny edges, color palettes, and various metadata and embeddings.
This is especially the case when thinking about the robustness and fairness of deep neuralnetwork models, both of which are essential for models used in practical settings in addition to their sheer accuracy. Most publicly available image databases are difficult to edit beyond crude image augmentations and lack fine-grained metadata.
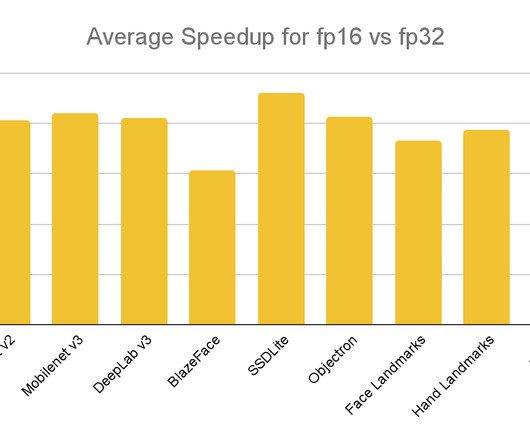
Performance Improvements Half-precision inference has already been battle-tested in production across Google Assistant, Google Meet, YouTube, and ML Kit, and demonstrated close to 2X speedups across a wide range of neuralnetwork architectures and mobile devices. target_spec. supported_types = [tf. float16] converter. target_spec.
In this post, we illustrate how to handle OOC by utilizing the power of the IMDb dataset (the premier source of global entertainment metadata) and knowledge graphs. Creates a Lambda function to process and load movie metadata and embeddings to OpenSearch Service indexes ( **-ReadFromOpenSearchLambda-** ).
Noise: The metadata associated with the content doesn’t have a well-defined ontology. The overall system ( Figure 2 ) consists of two neuralnetworks for candidate generation and ranking. Do you think learning computervision and deep learning has to be time-consuming, overwhelming, and complicated? RecSys’16 ).
Each encoder generates embeddings capturing semantic features of their respective modalities Modality fusion – The embeddings from the uni-modal encoders are combined using additional neuralnetwork layers. Load the publicly available Amazon Berkeley Objects Dataset and metadata in a pandas data frame.
These works along with those developed by others in the field have showcased how deep neuralnetworks can potentially transform end user experiences and the interaction design practice. This metadata has given previous models advantages over their vision-only counterparts. their types, text content and positions).
Two-Tower Model Design The core technical innovation lies in a dual neuralnetwork architecture, which is also the industry standard: User Tower : Processes user-specific features including long-term engagement history(captured through sequence modeling), demographic/profile data, and real-time context (device type, location, etc.).
This includes various products related to different aspects of AI, including but not limited to tools and platforms for deep learning, computervision, natural language processing, machine learning, cloud computing, and edge AI. Viso Suite enables organizations to solve the challenges of scaling computervision.
By combining the accelerated LSTM deep neuralnetwork with its existing methods, American Express has improved fraud detection accuracy by up to 6% in specific segments. Financial companies can also use accelerated computing to reduce data processing costs. Initially running on CPUs, processing took more than 24 hours.
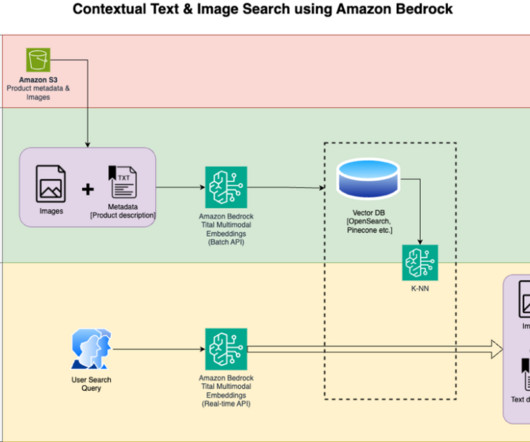
Images can often be searched using supplemented metadata such as keywords. However, it takes a lot of manual effort to add detailed metadata to potentially thousands of images. Generative AI (GenAI) can be helpful in generating the metadata automatically. This helps us build more refined searches in the image search process.
To help with this, Google Maps launched Immersive View , which uses advances in machine learning (ML) and computervision to fuse billions of Street View and aerial images to create a rich, digital model of the world. Beyond that, it layers helpful information on top, like the weather, traffic, and how busy a place is.
The capability of AI to execute complex tasks efficiently is determined by image annotation, which is a key determinant of its success and is defined as the process of labeling images with descriptive metadata. The 1950s saw the development of neuralnetworks that were trained by using hand-labeled images.
Thus, LinkedIn leverages neuralnetworks that can handle complex queries and capture the non-linear relationship between the query and the candidates. A member network embeds a given member to a fixed dimensional latent space. A cross-network that takes a query and member embeddings and computes their relevance score.
When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. Can you compare images?
An Introduction to Image Segmentation Image segmentation is a massively popular computervision task that deals with the pixel-level classification of images. dropout ratio) and other relevant metadata (e.g., Do you think learning computervision and deep learning has to be time-consuming, overwhelming, and complicated?
They can include model parameters, configuration files, pre-processing components, as well as metadata, such as version details, authorship, and any notes related to its performance. Her primary areas of interest encompass Deep Learning, with a focus on GenAI, ComputerVision, NLP, and time series data prediction.
A neuralnetwork design with numerous layers and a set of labeled data are used to train deep learning models. These models have two major components, Weights and Network architecture, that you need to save to restore them for future use. You can find all of this information in the model metadata tab of a Neptune project.
However, in the realm of unsupervised learning, generative models like Generative Adversarial Networks (GANs) have gained prominence for their ability to produce synthetic yet realistic images. Before the rise of GANs, there were other foundational neuralnetwork architectures for generative modeling. The config.py The torch.nn
Table of Contents Automatic Differentiation Part 2: Implementation Using Micrograd Introduction What Is a NeuralNetwork? Automatic Differentiation Part 2: Implementation Using Micrograd Introduction What Is a NeuralNetwork? Or requires a degree in computer science? _prev : The children of the current node.
PyTorch is a machine learning (ML) framework based on the Torch library, used for applications such as computervision and natural language processing. PyTorch supports dynamic computational graphs, enabling network behavior to be changed at runtime. Triton uses TorchScript for improved performance and flexibility.
The Amazon Product Reviews Dataset provides over 142 million Amazon product reviews with their associated metadata, allowing machine learning practitioners to train sentiment models using product ratings as a proxy for the sentiment label. Because these networks are recurrent, they are ideal for working with sequential data such as text.
A typical multimodal LLM has three primary modules: The input module comprises specialized neuralnetworks for each specific data type that output intermediate embeddings. combining video with text metadata may reveal sensitive information).) How do multimodal LLMs work?
It serves as a versatile resource for various computervision tasks, including face recognition, detection, landmark localization, and even advanced applications like face editing and synthesis. The ConvBlock class is defined on Line 10 , inheriting from nn.Module , which is the base class for all neuralnetwork modules in PyTorch.
Computation Function We consider a neuralnetwork $f_theta$ as a composition of functions $f_{theta_1} odot f_{theta_2} odot ldots odot f_{theta_l}$, each with their own set of parameters $theta_i$. d) Hypernetwork: A small separate neuralnetwork generates modular parameters conditioned on metadata.
script sets up the autoencoder model hyperparameters and creates an output directory for storing training progress metadata, model weights, and post-training analysis plots. torchvision : This is a part of PyTorch, consisting of popular datasets, model architectures, and common image transformations for computervision.
Large language models (LLMs) are neuralnetwork-based language models with hundreds of millions ( BERT ) to over a trillion parameters ( MiCS ), and whose size makes single-GPU training impractical. Regarding the scope of this post, note the following: We don’t cover neuralnetwork scientific design and associated optimizations.
In addition to the model weights, a model registry also stores metadata about the data and models. This will enable you to version, review, and access your models and associated metadata in a single place. ONNX has support for both Deep NeuralNetworks and Classical Machine Learning models.
Keras Python’s Keras is a high-level API for neuralnetworks that may be used with either TensorFlow, CNTK, or Theano. PyTorch For tasks like computervision and natural language processing, Using the Torch library as its foundation, PyTorch is a free and open-source machine learning framework that comes in handy.
Typical NeuralNetwork architectures take relatively small images (for example, EfficientNetB0 224x224 pixels) as input. Since StainNet produces coloring consistent across multiple tiles of the same image, we could apply the pre-trained StainNet NeuralNetwork on batches of random tiles.
Could you speak to the use of maybe data cards or other techniques for capturing metadata such as the definitions of features, how the data was sourced, assumptions implicit in the distribution, etc? What we do in TFX is we use ML metadata as a tool to capture all those steps and it preserves the lineage of all those artifacts.
Could you speak to the use of maybe data cards or other techniques for capturing metadata such as the definitions of features, how the data was sourced, assumptions implicit in the distribution, etc? What we do in TFX is we use ML metadata as a tool to capture all those steps and it preserves the lineage of all those artifacts.
Could you speak to the use of maybe data cards or other techniques for capturing metadata such as the definitions of features, how the data was sourced, assumptions implicit in the distribution, etc? What we do in TFX is we use ML metadata as a tool to capture all those steps and it preserves the lineage of all those artifacts.
The code is set up to track all experiment metadata in Neptune. Architectural methods like Progressive NeuralNetworks could be a good choice if you prioritize preserving past data over learning new concepts. It is designed for PyTorch and can be used in various domains like ComputerVision and Natural Language Processing.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content