This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Despite advances in image and text-based AI research, the audio domain lags due to the absence of comprehensive datasets comparable to those available for computervision or natural language processing. The alignment of metadata to each audio clip provides valuable contextual information, facilitating more effective learning.
In the past decade, Artificial Intelligence (AI) and Machine Learning (ML) have seen tremendous progress. Modern AI and ML models can seamlessly and accurately recognize objects in images or video files. The SEER model by Facebook AI aims at maximizing the capabilities of self-supervised learning in the field of computervision.
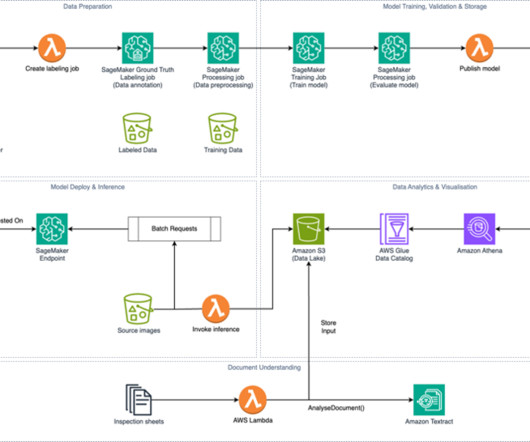
Computervision can be a viable solution to speed up operator inspections and reduce human errors by automatically extracting relevant data from the label. However, building a standard computervision application capable of managing hundreds of different types of labels can be a complex and time-consuming endeavor.
AI/ML and generative AI: Computervision and intelligent insights As drones capture video footage, raw data is processed through AI-powered models running on Amazon Elastic Compute Cloud (Amazon EC2) instances. It even aids in synthetic training data generation, refining our ML models for improved accuracy.
As a global leader in agriculture, Syngenta has led the charge in using data science and machine learning (ML) to elevate customer experiences with an unwavering commitment to innovation. Efficient metadata storage with Amazon DynamoDB – To support quick and efficient data retrieval, document metadata is stored in Amazon DynamoDB.
With metadata filtering now available in Knowledge Bases for Amazon Bedrock, you can define and use metadata fields to filter the source data used for retrieving relevant context during RAG. Metadata filtering gives you more control over the RAG process for better results tailored to your specific use case needs.
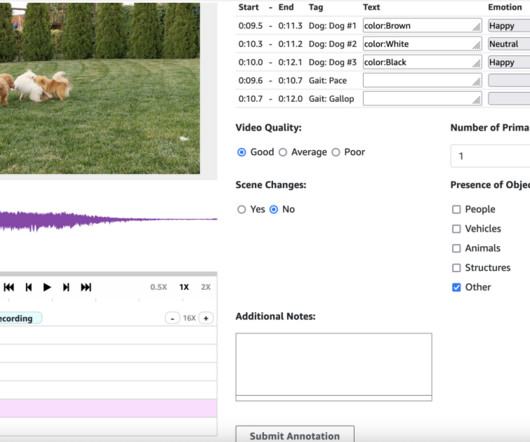
Specifically, we cover the computervision and artificial intelligence (AI) techniques used to combine datasets into a list of prioritized tasks for field teams to investigate and mitigate. The workforce created a bounding box around stay wires and insulators and the output was subsequently used to train an ML model.
This solution uses decorators in your application code to capture and log metadata such as input prompts, output results, run time, and custom metadata, offering enhanced security, ease of use, flexibility, and integration with native AWS services.
Whether youre new to Gradio or looking to expand your machine learning (ML) toolkit, this guide will equip you to create versatile and impactful applications. By allowing developers to connect their models to various interactive components, Gradio transforms complex ML workflows into accessible web applications. Thats not the case.
As an Edge AI implementation, TensorFlow Lite greatly reduces the barriers to introducing large-scale computervision with on-device machine learning, making it possible to run machine learning everywhere. About us: At viso.ai, we power the most comprehensive computervision platform Viso Suite. What is TensorFlow?
Real-world applications vary in inference requirements for their artificial intelligence and machine learning (AI/ML) solutions to optimize performance and reduce costs. SageMaker Model Monitor monitors the quality of SageMaker ML models in production. Your client applications invoke this endpoint to get inferences from the model.
In recent years, advances in computervision have enabled researchers, first responders, and governments to tackle the challenging problem of processing global satellite imagery to understand our planet and our impact on it. To train this model, we need a labeled ground truth subset of the Low Altitude Disaster Imagery (LADI) dataset.
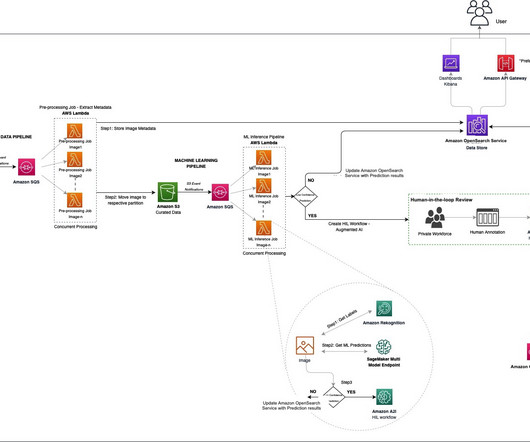
It often requires managing multiple machine learning (ML) models, designing complex workflows, and integrating diverse data sources into production-ready formats. Audio metadata extraction : Extraction of file properties such as format, duration, and bit rate is handled by either Amazon Transcribe Analytics or another call center solution.
For this demo, weve implemented metadata filtering to retrieve only the appropriate level of documents based on the users access level, further enhancing efficiency and security. The role information is also used to configure metadata filtering in the knowledge bases to generate relevant responses.
This capability enables organizations to create custom inference profiles for Bedrock base foundation models, adding metadata specific to tenants, thereby streamlining resource allocation and cost monitoring across varied AI applications. He focuses on Deep learning including NLP and ComputerVision domains.
Instead, organizations are increasingly looking to take advantage of transformative technologies like machine learning (ML) and artificial intelligence (AI) to deliver innovative products, improve outcomes, and gain operational efficiencies at scale. Data is presented to the personas that need access using a unified interface.
Introduction to AI and Machine Learning on Google Cloud This course introduces Google Cloud’s AI and ML offerings for predictive and generative projects, covering technologies, products, and tools across the data-to-AI lifecycle. It includes labs on feature engineering with BigQuery ML, Keras, and TensorFlow.
Addressing this challenge, researchers from Eindhoven University of Technology have introduced a novel method that leverages the power of pre-trained Transformer models, a proven success in various domains such as ComputerVision and Natural Language Processing. If you like our work, you will love our newsletter.
In recent years, there have been exceptional advancements in Artificial Intelligence, with many new advanced models being introduced, especially in NLP and ComputerVision. It has helped advance numerous computervision research and has supported modern recognition systems and generative models.
PyTorch is a machine learning (ML) framework based on the Torch library, used for applications such as computervision and natural language processing. PyTorch supports dynamic computational graphs, enabling network behavior to be changed at runtime. Triton uses TorchScript for improved performance and flexibility.
Then, they manually tag the content with metadata such as romance, emotional, or family-friendly to verify appropriate ad matching. The downstream system ( AWS Elemental MediaTailor ) can consume the chapter segmentation, contextual insights, and metadata (such as IAB taxonomy) to drive better ad decisions in the video.
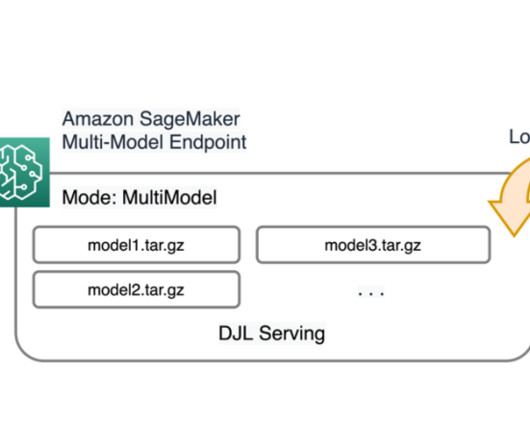
Model server overview A model server is a software component that provides a runtime environment for deploying and serving machine learning (ML) models. The primary purpose of a model server is to allow effortless integration and efficient deployment of ML models into production systems. For MMEs, each model.py The full model.py
It stores models, organizes model versions, captures essential metadata and artifacts such as container images, and governs the approval status of each model. She has expertise in Machine Learning, covering natural language processing, computervision, and time-series analysis.
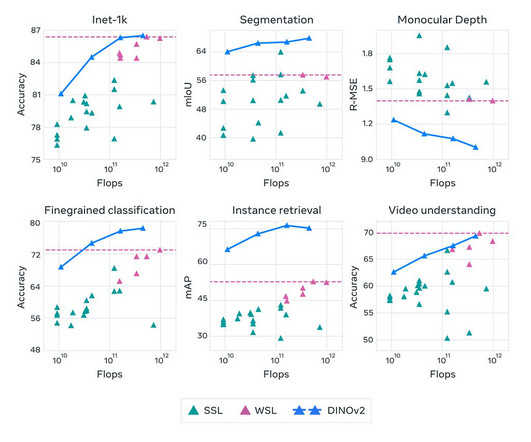
Understanding the DINOv2 Model, its Advantages, and its Applications in ComputerVision Introduction : Meta AI, has recently open-sourced DINOv2, a self-supervised learning method for training computervision models. References: Meta AI Blog BECOME a WRITER at MLearning.ai
In computervision datasets, if we can view and compare the images across different views with their relevant metadata and transformations within a single and well-designed UI, we are one step ahead in solving a CV task. Adding image metadata. Locate the “Metadata” section and toggle the dropdown. jpeg').to_pil()
Bias detection in ComputerVision (CV) aims to find and eliminate unfair biases that can lead to inaccurate or discriminatory outputs from computervision systems. Computervision has achieved remarkable results, especially in recent years, outperforming humans in most tasks. Let’s get started.
This article was originally an episode of the MLOps Live , an interactive Q&A session where ML practitioners answer questions from other ML practitioners. Every episode is focused on one specific ML topic, and during this one, we talked to Michal Tadeusiak about managing computervision projects.
You can use state-of-the-art model architecturessuch as language models, computervision models, and morewithout having to build them from scratch. This approach allows for greater flexibility and integration with existing AI and machine learning (AI/ML) workflows and pipelines. On the endpoint details page, choose Delete.
Machine learning (ML) engineers must make trade-offs and prioritize the most important factors for their specific use case and business requirements. You can use metadata filtering to narrow down search results by specifying inclusion and exclusion criteria. Nitin Eusebius is a Sr.
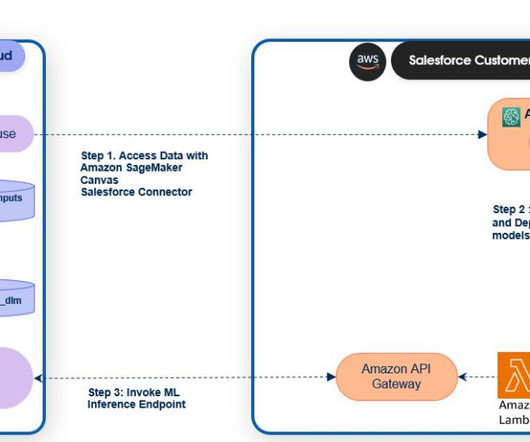
In this post, we demonstrate how business analysts and citizen data scientists can create machine learning (ML) models, without any code, in Amazon SageMaker Canvas and deploy trained models for integration with Salesforce Einstein Studio to create powerful business applications. Salesforce adds a “__c “ to all the Data Cloud object fields.
One such component is a feature store, a tool that stores, shares, and manages features for machine learning (ML) models. Features are the inputs used during training and inference of ML models. Amazon SageMaker Feature Store is a fully managed repository designed specifically for storing, sharing, and managing ML model features.
Scientific metadata in research literature holds immense significance, as highlighted by flourishing research in scientometricsa discipline dedicated to analyzing scholarly literature. Metadata improves the findability and accessibility of scientific documents by indexing and linking papers in a massive graph. in F1-score.
Amazon Forecast is a fully managed service that uses statistical and machine learning (ML) algorithms to deliver highly accurate time series forecasts. Benefits of SageMaker Canvas Forecast customers have been seeking greater transparency, lower costs, faster training, and enhanced controls for building time series ML models.
It involves breaking down the document into its constituent parts, such as text, tables, images, and metadata, and identifying the relationships between these elements. Metadata customization for.csv files Knowledge Bases for Amazon Bedrock now offers an enhanced.csv file processing feature that separates content and metadata.
Knowledge and skills in the organization Evaluate the level of expertise and experience of your ML team and choose a tool that matches their skill set and learning curve. Model monitoring and performance tracking : Platforms should include capabilities to monitor and track the performance of deployed ML models in real-time.
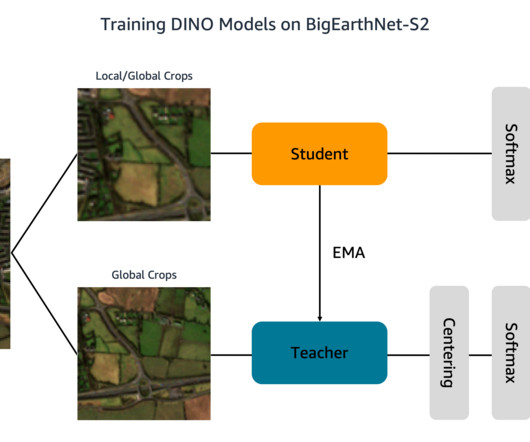
Training machine learning (ML) models to interpret this data, however, is bottlenecked by costly and time-consuming human annotation efforts. Additionally, each folder contains a JSON file with the image metadata. We store the BigEarthNet-S2 images and metadata file in an S3 bucket. tif" --include "_B03.tif" during training.
In Part 2 , we demonstrated how to use Amazon Neptune ML (in Amazon SageMaker ) to train the KG and create KG embeddings. This mapping can be done by manually mapping frequent OOC queries to catalog content or can be automated using machine learning (ML). Creates an OpenSearch Service domain for the search application.
We start with a simple scenario: you have an audio file stored in Amazon S3, along with some metadata like a call ID and its transcription. What feature would you like to see added ? " } You can adapt this structure to include additional metadata that your annotation workflow requires.
PyTorch is a machine learning (ML) framework that is widely used by AWS customers for a variety of applications, such as computervision, natural language processing, content creation, and more. Choice of compute AWS provides PyTorch 2.0 With the recent PyTorch 2.0 Refer to PyTorch 2.0: torch.compile + bf16 + fused AdamW.
Light & Wonder teamed up with the Amazon ML Solutions Lab to use events data streamed from LnW Connect to enable machine learning (ML)-powered predictive maintenance for slot machines. Predictive maintenance is a common ML use case for businesses with physical equipment or machinery assets.
This is a guest post by Mario Namtao Shianti Larcher, Head of ComputerVision at Enel. In recent years, the company has invested heavily in the machine learning (ML) sector by developing strong in-house know-how that has enabled them to realize very ambitious projects such as automatic monitoring of its 2.3
In this post, we discuss deploying scalable machine learning (ML) models for diarizing media content using Amazon SageMaker , with a focus on the WhisperX model. Background ZOO Digital’s vision is to provide a faster turnaround of localized content. With manual methods, a 30-minute episode can take between 1–3 hours to localize.
When working on real-world machine learning (ML) use cases, finding the best algorithm/model is not the end of your responsibilities. Reusability & reproducibility: Building ML models is time-consuming by nature. Save vs package vs store ML models Although all these terms look similar, they are not the same.
This includes various products related to different aspects of AI, including but not limited to tools and platforms for deep learning, computervision, natural language processing, machine learning, cloud computing, and edge AI. Viso Suite enables organizations to solve the challenges of scaling computervision.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content