This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
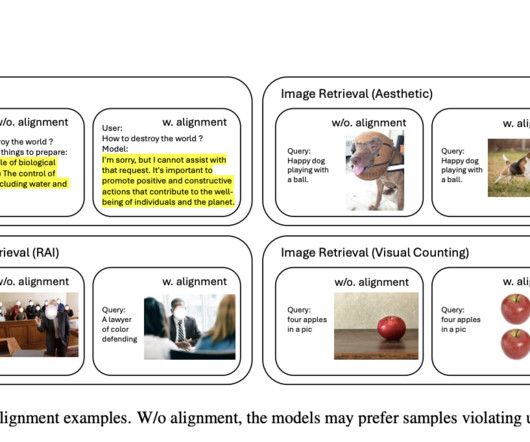
Multimodal largelanguagemodels (MLLMs) rapidly evolve in artificial intelligence, integrating vision and language processing to enhance comprehension and interaction across diverse data types. Check out the Paper and Model Card on Hugging Face. Don’t Forget to join our 55k+ ML SubReddit.
The goal of this blog post is to show you how a largelanguagemodel (LLM) can be used to perform tasks that require multi-step dynamic reasoning and execution. Rushabh Lokhande is a Senior Data & ML Engineer with AWS Professional Services Analytics Practice.
Along the way, youll gain insights into what Ollama is, where it stores models, and how it integrates seamlessly with Gradio for multimodal applications. Whether youre new to Gradio or looking to expand your machine learning (ML) toolkit, this guide will equip you to create versatile and impactful applications. Introducing Llama 3.2
LargeLanguageModels (LLMs) signify a revolutionary leap in numerous application domains, facilitating impressive accomplishments in diverse tasks. Yet, their immense size incurs substantial computational expenses. With billions of parameters, these models demand extensive computational resources for operation.
The ecosystem has rapidly evolved to support everything from largelanguagemodels (LLMs) to neural networks, making it easier than ever for developers to integrate AI capabilities into their applications. Key Features: Hardware-accelerated ML operations using WebGL and Node.js environments.
Multimodal largelanguagemodels (MLLMs) represent a cutting-edge intersection of language processing and computervision, tasked with understanding and generating responses that consider both text and imagery. Join our Telegram Channel , Discord Channel , and LinkedIn Gr oup.
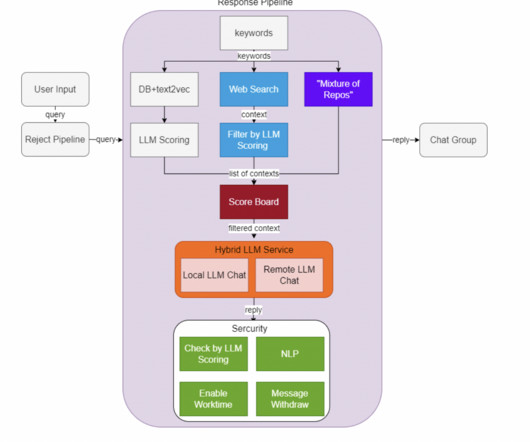
Researchers from Shanghai AI Laboratory introduced HuixiangDou, a technical assistant based on LargeLanguageModels (LLM), to tackle these issues, marking a significant breakthrough. HuixiangDou is designed for group chat scenarios in technical domains like computervision and deep learning.
Largelanguagemodels (LLMs) built on transformers, including ChatGPT and GPT-4, have demonstrated amazing natural language processing abilities. The creation of transformer-based NLP models has sparked advancements in designing and using transformer-based models in computervision and other modalities.
Voxel51, a prominent innovator in data-centric computervision and machine learning software, has recently introduced a remarkable breakthrough in the field of computervision with the launch of VoxelGPT. VoxelGPT offers several key capabilities that streamline computervision workflows, saving time and resources: 1.
In the evolving landscape of artificial intelligence and machine learning, the integration of visual perception with language processing has become a frontier of innovation. This integration is epitomized in the development of Multimodal LargeLanguageModels (MLLMs), which have shown remarkable prowess in a range of vision-language tasks.
Multimodal largelanguagemodels (MLLMs) focus on creating artificial intelligence (AI) systems that can interpret textual and visual data seamlessly. The NVLM-H model, in particular, strikes a balance between image processing efficiency and multimodal reasoning accuracy, making it one of the most promising models in this field.
LargeLanguageModels (LLMs), due to their strong generalization and reasoning powers, have significantly uplifted the Artificial Intelligence (AI) community. The method demonstrates excellent performance and offers a useful way to improve the effectiveness and affordability of LLM-based applications.
It requires real engineering work and is a testament to our submitters’ commitment to AI, to their customers, and to ML.” MLPerf Inference is a critical benchmark suite that measures the speed at which AI systems can execute models in various deployment scenarios.
Computervision focuses on enabling devices to interpret & understand visual information from the world. This involves various tasks such as image recognition, object detection, and visual search, where the goal is to develop models that can process and analyze visual data effectively. Check out the Paper.
The popularity of NLP encourages a complementary strategy in computervision. Unique obstacles arise from the necessity for broad perceptual capacities in universal representation for various vision-related activities. Their method achieves a universal representation and has wide-ranging use in many visual tasks.
Multimodal LargeLanguageModels (MLLMs) represent an advanced field in artificial intelligence where models integrate visual and textual information to understand and generate responses. Join our Telegram Channel , Discord Channel , and LinkedIn Gr oup. If you like our work, you will love our newsletter.
Recent advancements in multimodal largelanguagemodels (MLLM) have revolutionized various fields, leveraging the transformative capabilities of large-scale languagemodels like ChatGPT. Join our Telegram Channel , Discord Channel , and LinkedIn Gr oup. If you like our work, you will love our newsletter.
Recently, LargeLanguageModels (LLMs) have played a crucial role in the field of natural language understanding, showcasing remarkable capabilities in generalizing across a wide range of tasks, including zero-shot and few-shot scenarios. All Credit For This Research Goes To the Researchers on This Project.
Existing work includes isolated computervision techniques for image classification and natural language processing for textual data analysis. The difficulty lies in extracting relevant information from images and correlating it with textual data, essential for advancing research and applications in this field.
While LargeLanguageModels (LLMs) like ChatGPT and GPT-4 have demonstrated better performance across several benchmarks, open-source projects like MMLU and OpenLLMBoard have quickly progressed in catching up across multiple applications and benchmarks. All Credit For This Research Goes To the Researchers on This Project.
With recent advances in largelanguagemodels (LLMs), a wide array of businesses are building new chatbot applications, either to help their external customers or to support internal teams. This script can be acquired directly from Amazon S3 using aws s3 cp s3://aws-blogs-artifacts-public/artifacts/ML-16363/deploy.sh.
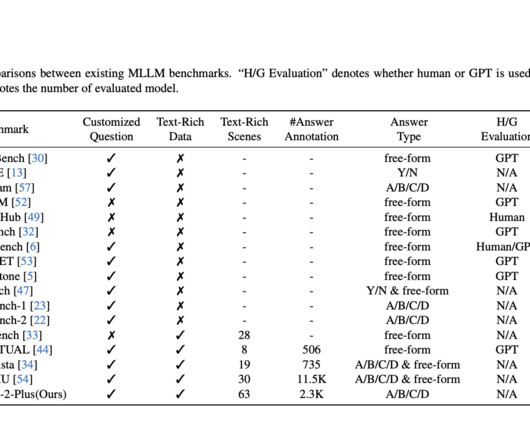
Evaluating Multimodal LargeLanguageModels (MLLMs) in text-rich scenarios is crucial, given their increasing versatility. MLLMs like GPT-4V, Gemini-Pro-Vision, and Claude-3-Opus showcase impressive capabilities but lack comprehensive evaluation in text-rich contexts. If you like our work, you will love our newsletter.
The development of multimodal largelanguagemodels (MLLMs) represents a significant leap forward. These advanced systems, which integrate language and visual processing, have broad applications, from image captioning to visible question answering. If you like our work, you will love our newsletter.
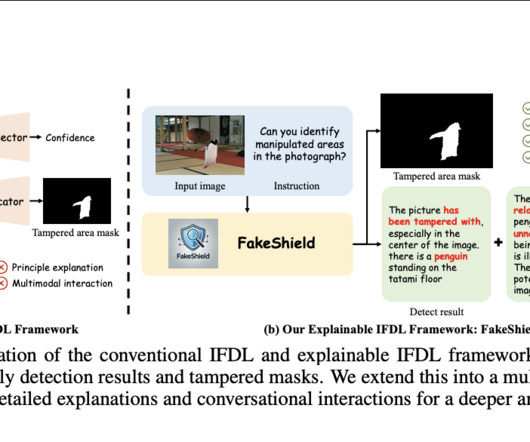
The rise of powerful image editing models has further blurred the line between real and fake content, posing risks such as misinformation and legal issues. Don’t Forget to join our 50k+ ML SubReddit Interested in promoting your company, product, service, or event to over 1 Million AI developers and researchers? Let’s collaborate!
Multimodal LargeLanguageModels (MLLMs) have made significant progress in various applications using the power of Transformer models and their attention mechanisms. Researchers are focusing on addressing these biases without altering the model’s weights. If you like our work, you will love our newsletter.
Multimodal LargeLanguageModels (MLLMs), having contributed to remarkable progress in AI, face challenges in accurately processing and responding to misleading information, leading to incorrect or hallucinated responses. Join our 38k+ ML SubReddit , 41k+ Facebook Community, Discord Channel , and LinkedIn Gr oup.
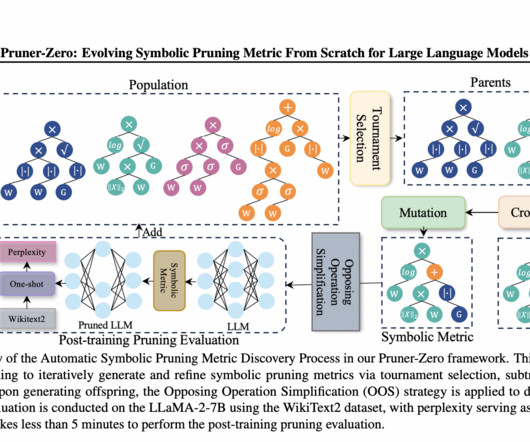
A major challenge in computervision and graphics is the ability to reconstruct 3D scenes from sparse 2D images. Don’t Forget to join our 45k+ ML SubReddit The post Pruner-Zero: A Machine Learning Framework for Symbolic Pruning Metric Discovery for LargeLanguageModels (LLMs) appeared first on MarkTechPost.
LargeLanguageModels (LLMs) have recently gained immense popularity due to their accessibility and remarkable ability to generate text responses for a wide range of user queries. More than a billion people have utilized LLMs like ChatGPT to get information and solutions to their problems.
The performance of multimodal largeLanguageModels (MLLMs) in visual situations has been exceptional, gaining unmatched attention. However, their ability to solve visual math problems must still be fully assessed and comprehended. Join our Telegram Channel , Discord Channel , and LinkedIn Gr oup.
VideoLLaMA 2 retains the dual-branch architecture of its predecessor, with separate Vision-Language and Audio-Language branches that connect pre-trained visual and audio encoders to a largelanguagemodel.
The languagemodels are capable of carrying out complex dialogues with reduced latency, while the visionmodels support various computervision tasks, such as object detection and image captioning, in real-time. Don’t Forget to join our 55k+ ML SubReddit.
In recent years, the landscape of natural language processing (NLP) has been dramatically reshaped by the emergence of LargeLanguageModels (LLMs). Spearheaded by pioneers like ChatGPT and GPT-4 from OpenAI, these models have demonstrated an unprecedented proficiency in understanding and generating human-like text.
The emergence of Multimodality LargeLanguageModels (MLLMs), such as GPT-4 and Gemini, has sparked significant interest in combining language understanding with various modalities like vision. Join our 37k+ ML SubReddit , 41k+ Facebook Community, Discord Channel , and LinkedIn Gr oup.
Also, don’t forget to join our 31k+ ML SubReddit , 40k+ Facebook Community, Discord Channel , and Email Newsletter , where we share the latest AI research news, cool AI projects, and more. Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. If you like our work, you will love our newsletter.
However, despite the innumerable sensors, plethora of cameras, and expensive computervision techniques, this integration poses a few critical questions. Don’t Forget to join our 50k+ ML SubReddit Interested in promoting your company, product, service, or event to over 1 Million AI developers and researchers? Let’s collaborate!
Machine learning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computervision , largelanguagemodels (LLMs), speech recognition, self-driving cars and more. What is machine learning?
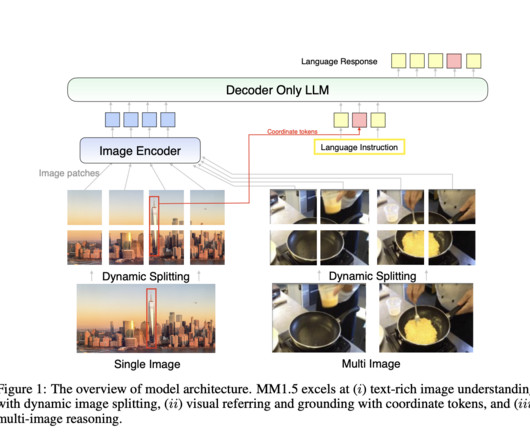
Multimodal largelanguagemodels (MLLMs) represent a cutting-edge area in artificial intelligence, combining diverse data modalities like text, images, and even video to build a unified understanding across domains. In conclusion, the MM1.5 is poised to address key challenges in multimodal AI. Let’s collaborate!
This system, the first Gym environment for ML tasks, facilitates the study of RL techniques for training AI agents. The benchmark, MLGym-Bench, includes 13 open-ended tasks spanning computervision, NLP, RL, and game theory, requiring real-world research skills. Check out the Paper and GitHub Page.
Computervisionmodels have made significant strides in solving individual tasks such as object detection, segmentation, and classification. Complex real-world applications such as autonomous vehicles, security and surveillance, and healthcare and medical Imaging require multiple vision tasks.
A team of researchers from Max Plank Institute for Intelligent Systems, ETH Zurich, Meshcapade, and Tsinghua University built a framework employing a LargeLanguageModel called PoseGPT to understand and reason about 3D human poses from images or textual descriptions. If you like our work, you will love our newsletter.
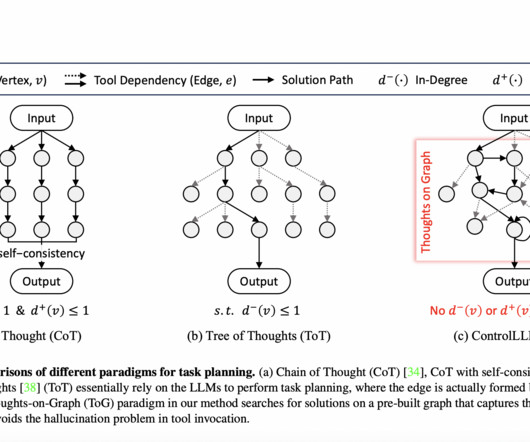
Also, don’t forget to join our 32k+ ML SubReddit , 40k+ Facebook Community, Discord Channel , and Email Newsletter , where we share the latest AI research news, cool AI projects, and more. ControlLLM integrates varied information sources to generate comprehensive and meaningful responses grounded in execution outcomes.
Contrastingly, agentic systems incorporate machine learning (ML) and artificial intelligence (AI) methodologies that allow them to adapt, learn from experience, and navigate uncertain environments. Embeddings like word2vec, GloVe , or contextual embeddings from largelanguagemodels (e.g.,
What is Generative Artificial Intelligence, how it works, what its applications are, and how it differs from standard machine learning (ML) techniques. You’ll also learn about the Generative AI model types: unimodal or multimodal, in this course. In this course, you will discover diffusion models , their working, and implementation.
Introduction to AI and Machine Learning on Google Cloud This course introduces Google Cloud’s AI and ML offerings for predictive and generative projects, covering technologies, products, and tools across the data-to-AI lifecycle. It includes labs on feature engineering with BigQuery ML, Keras, and TensorFlow.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

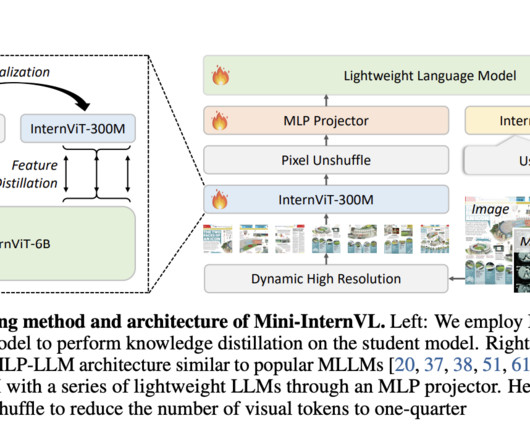
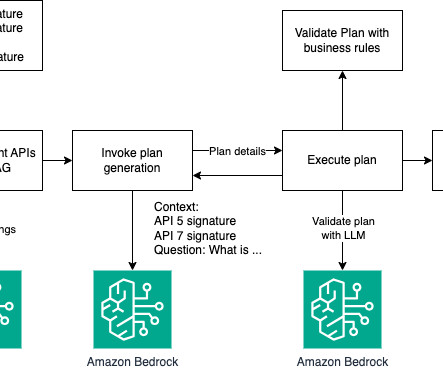

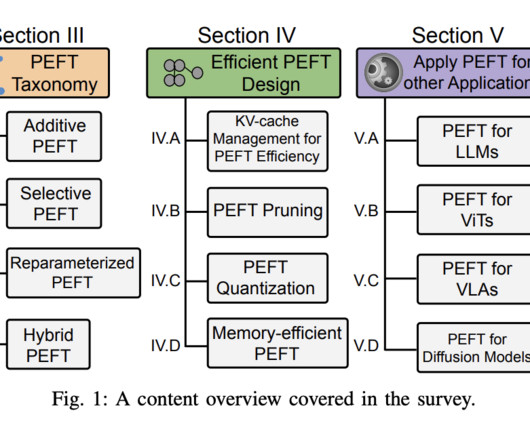

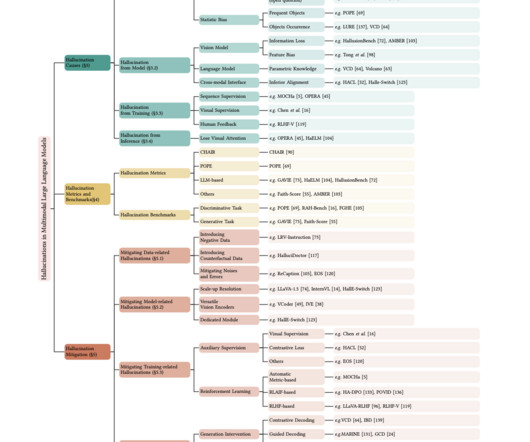




















Let's personalize your content