This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
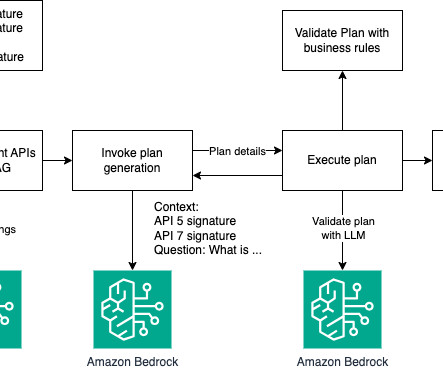
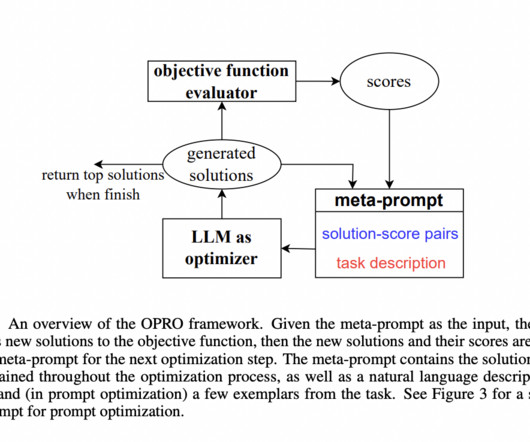
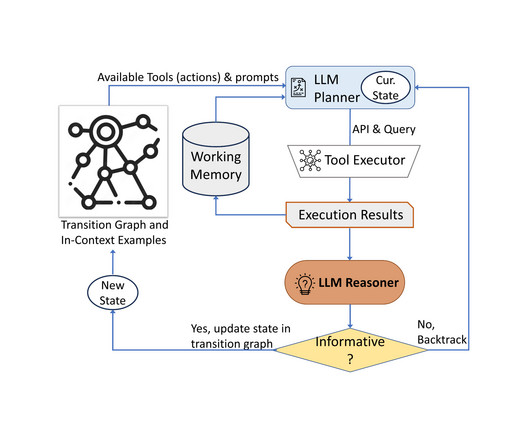
The goal of this blog post is to show you how a largelanguagemodel (LLM) can be used to perform tasks that require multi-step dynamic reasoning and execution. These function signatures act as tools that the LLM can use to formulate a plan to answer a users query.
The latest release of MLPerf Inference introduces new LLM and recommendation benchmarks, marking a leap forward in the realm of AI testing. An updated recommender benchmark – refined to align more closely with industry practices – employs the DLRM-DCNv2 reference model and larger datasets, attracting nine submissions.
He enjoyed working at the intersection of several fields; human robot interaction, largelanguagemodels, and classical computervision were all necessary to create the robot. The LLM can be programmed to return any number of reference photographs.
TL;DR Multimodal LargeLanguageModels (MLLMs) process data from different modalities like text, audio, image, and video. Compared to text-only models, MLLMs achieve richer contextual understanding and can integrate information across modalities, unlocking new areas of application. How do multimodal LLMs work?
Researchers from Shanghai AI Laboratory introduced HuixiangDou, a technical assistant based on LargeLanguageModels (LLM), to tackle these issues, marking a significant breakthrough. HuixiangDou is designed for group chat scenarios in technical domains like computervision and deep learning.
LargeLanguageModels (LLMs) signify a revolutionary leap in numerous application domains, facilitating impressive accomplishments in diverse tasks. Yet, their immense size incurs substantial computational expenses. With billions of parameters, these models demand extensive computational resources for operation.
LargeLanguageModels (LLMs) have extended their capabilities to different areas, including healthcare, finance, education, entertainment, etc. These models have utilized the power of Natural Language Processing (NLP), Natural Language Generation (NLG), and ComputerVision to dive into almost every industry.
The ecosystem has rapidly evolved to support everything from largelanguagemodels (LLMs) to neural networks, making it easier than ever for developers to integrate AI capabilities into their applications. environments. The framework's strength lies in its extensibility and integration capabilities. TensorFlow.js
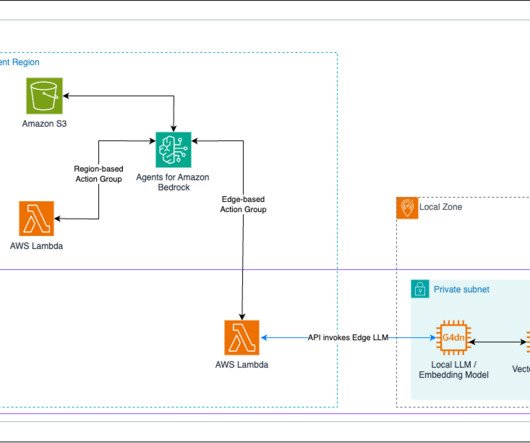
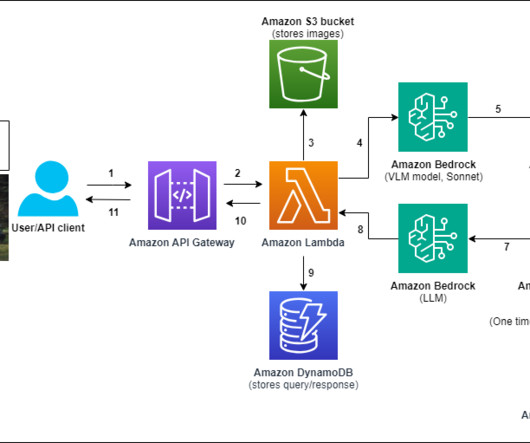
Fully local RAG For the deployment of a largelanguagemodel (LLM) in a RAG use case on an Outposts rack, the LLM will be self-hosted on a G4dn instance and knowledge bases will be created on the Outpost rack, using either Amazon Elastic Block Storage (Amazon EBS) or Amazon S3 on Outposts.
With recent advances in largelanguagemodels (LLMs), a wide array of businesses are building new chatbot applications, either to help their external customers or to support internal teams. From slowest to fastest, we have the call to the Claude V3 Vision FM, which takes on average 8.2
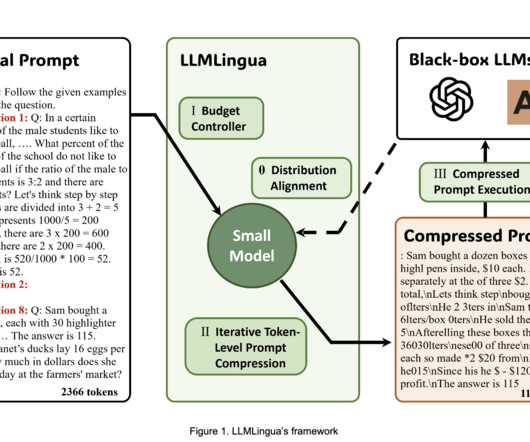
LargeLanguageModels (LLMs), due to their strong generalization and reasoning powers, have significantly uplifted the Artificial Intelligence (AI) community. Aligning the languagemodel distribution improves compatibility between the small languagemodel utilized for rapid compression and the intended LLM.
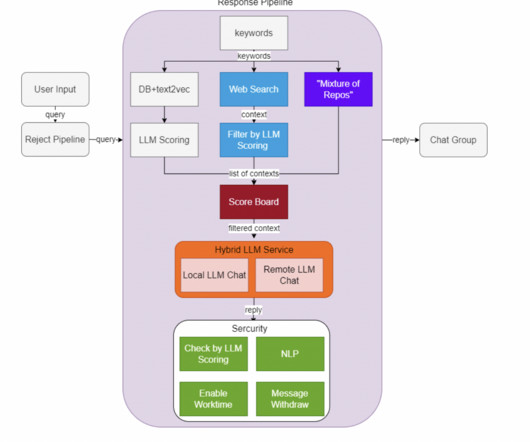
The effectiveness of RAG heavily depends on the quality of context provided to the largelanguagemodel (LLM), which is typically retrieved from vector stores based on user queries. The relevance of this context directly impacts the model’s ability to generate accurate and contextually appropriate responses.
Largelanguagemodels (LLMs) built on transformers, including ChatGPT and GPT-4, have demonstrated amazing natural language processing abilities. The creation of transformer-based NLP models has sparked advancements in designing and using transformer-based models in computervision and other modalities.
While LargeLanguageModels (LLMs) like ChatGPT and GPT-4 have demonstrated better performance across several benchmarks, open-source projects like MMLU and OpenLLMBoard have quickly progressed in catching up across multiple applications and benchmarks. If you like our work, you will love our newsletter.
While LargeVision-LanguageModels (LVLMs) can be useful aides in interpreting some of the more arcane or challenging submissions in computervision literature, there's one area where they are hamstrung: determining the merits and subjective quality of any video examples that accompany new papers*.
With the constant advancements in the field of Artificial Intelligence, its subfields, including Natural Language Processing, Natural Language Generation, Natural Language Understanding, and ComputerVision, are getting significantly popular. Secondly, it provides an Iterative Solution Generation.
However, traditional machine learning approaches often require extensive data-specific tuning and model customization, resulting in lengthy and resource-heavy development. Enter Chronos , a cutting-edge family of time series models that uses the power of largelanguagemodel ( LLM ) architectures to break through these hurdles.
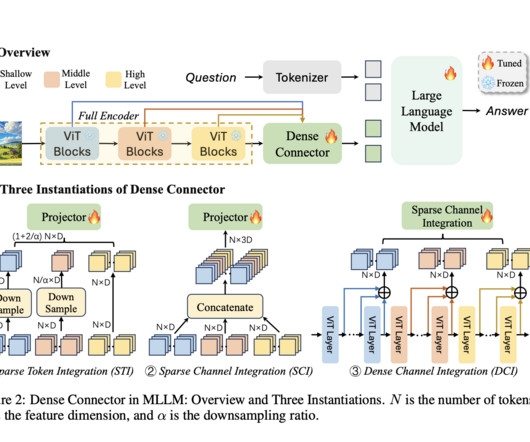
Multimodal LargeLanguageModels (MLLMs) represent an advanced field in artificial intelligence where models integrate visual and textual information to understand and generate responses. Each method utilizes visual tokens effectively to improve the robustness of visual embeddings fed into the LLM.
Largelanguagemodels (LLMs) have revolutionized the field of natural language processing with their ability to understand and generate humanlike text. Researchers developed Medusa , a framework to speed up LLM inference by adding extra heads to predict multiple tokens simultaneously.
The Microsoft AI London outpost will focus on advancing state-of-the-art languagemodels, supporting infrastructure, and tooling for foundation models. This paper offers a comprehensive survey of these studies, delivering a systematic review of LLM-based autonomous agents from a holistic perspective.
Text-to-image (T2I) generation is a rapidly evolving field within computervision and artificial intelligence. It involves creating visual images from textual descriptions blending natural language processing and graphic visualization domains. This method leverages an LLM agent for compositional text-to-image generation.
P.S. We will soon release an extremely in-depth ~90-lesson practical full stack “LLM Developer” conversion course. It highlights the dangers of using black box AI systems in critical applications and discusses techniques like LIME and Grad-CAM for enhancing model transparency. Learn AI Together Community section! AI poll of the week!
Traditional neural network models like RNNs and LSTMs and more modern transformer-based models like BERT for NER require costly fine-tuning on labeled data for every custom entity type. By using the model’s broad linguistic understanding, you can perform NER on the fly for any specified entity type.
Some of the earliest and most extensive work has occurred in the use of deep learning and computervisionmodels. observational studies and clinical trials–have used population-focused modeling approaches that rely on regression models, in which independent variables are used to predict outcomes.
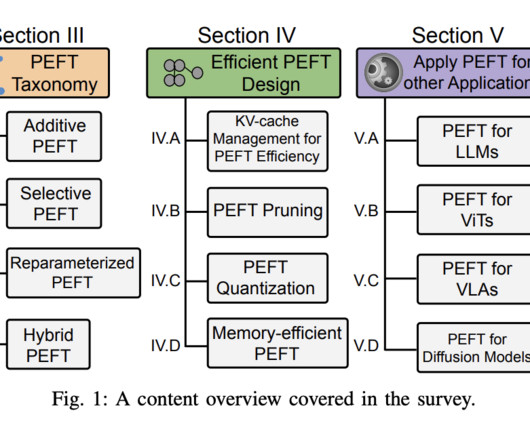
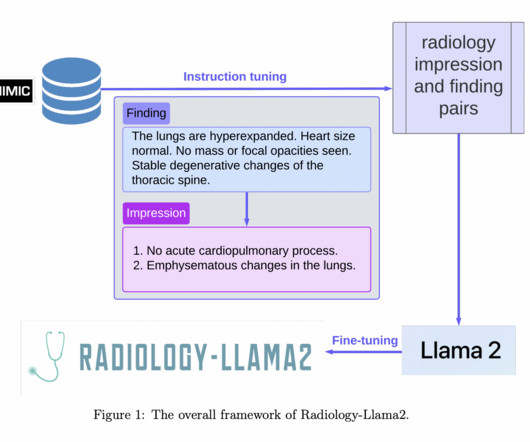
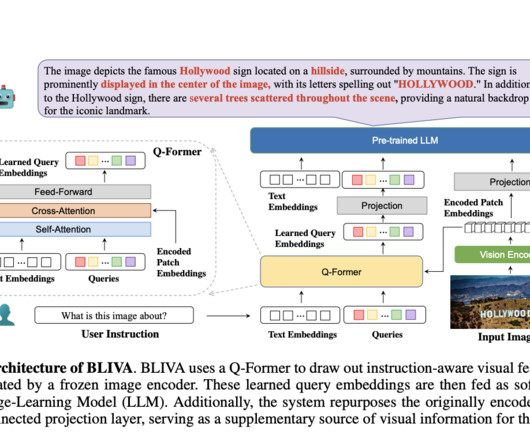
Recently, LargeLanguageModels (LLMs) have played a crucial role in the field of natural language understanding, showcasing remarkable capabilities in generalizing across a wide range of tasks, including zero-shot and few-shot scenarios. An overview of the proposed approach is presented in the figure below.
Largelanguagemodels (LLMs) have revolutionized the field of natural language processing, enabling machines to understand and generate human-like text with remarkable accuracy. However, despite their impressive language capabilities, LLMs are inherently limited by the data they were trained on.
This cutting-edge collaboration comes at a pivotal moment when developers and researchers are actively exploring the potential of largelanguagemodels (LLMs) and accelerated computing to unlock novel consumer and business use cases.
Computervision focuses on enabling devices to interpret & understand visual information from the world. This involves various tasks such as image recognition, object detection, and visual search, where the goal is to develop models that can process and analyze visual data effectively. Check out the Paper.
We are excited to announce that Amazon SageMaker JumpStart can now stream largelanguagemodel (LLM) inference responses. Token streaming allows you to see the model response output as it is being generated instead of waiting for LLMs to finish the response generation before it is made available for you to use or display.
LargeLanguageModels (LLMs) have demonstrated unparalleled capabilities in processing and generating text, transforming how to interact with digital content. KAUST and Harvard University researchers present MiniGPT4-Video , a pioneering multimodal LLM tailored specifically for video understanding.
Enterprises can run the NVIDIA Omniverse and NVIDIA AI Enterprise platforms at scale on RTX PRO 6000 Blackwell Server Edition GPUs to accelerate the development and deployment of agentic and physical AI applications, such as image and video generation, LLM inference, recommender systems , computervision, digital twins and robotics simulation.
LargeLanguageModels (LLMs) have recently gained immense popularity due to their accessibility and remarkable ability to generate text responses for a wide range of user queries. More than a billion people have utilized LLMs like ChatGPT to get information and solutions to their problems.
F-16 A new paper from China is offering a solution, in the form of the first multimodal largelanguagemodel (MLLM, or simply LLM) that can analyze video at 16fps instead of the standard 1fps, while avoiding the major pitfalls of increasing the analysis rate. A learning rate of 210 was used during training.
Source: [link] Sudden Impact The generative video AI research scene itself is no less explosive; it's still the first half of March, and Tuesday's submissions to Arxiv's ComputerVision section (a hub for generative AI papers) came to nearly 350 entries a figure more associated with the height of conference season.
LargeLanguageModels are the new trend, thanks to the introduction of the well-known ChatGPT. Developed by OpenAI, this chatbot does everything from answering questions precisely, summarizing long paragraphs of textual data, completing code snippets, translating the text into different languages, and so on.
If you havent already checked it out, weve also launched an extremely in-depth course to help you land a 6-figure job as an LLM developer. But, all the rules of learning that apply to AI, machine learning, and NLP dont always apply to LLMs, especially if you are building something or looking for a high-paying job.
These models struggle with processing temporal dynamics and integrating audio-visual data, limiting their effectiveness in predicting future events and performing comprehensive multimodal analyses. Addressing these complexities is crucial for enhancing Video-LLM performance.
Unlike traditional systems, which rely on rule-based automation and structured data, agentic systems, powered by largelanguagemodels (LLMs), can operate autonomously, learn from their environment, and make nuanced, context-aware decisions. DeepSeek-R1 is an advanced LLM developed by the AI startup DeepSeek.
A team of researchers from Max Plank Institute for Intelligent Systems, ETH Zurich, Meshcapade, and Tsinghua University built a framework employing a LargeLanguageModel called PoseGPT to understand and reason about 3D human poses from images or textual descriptions. If you like our work, you will love our newsletter.
Posted by Ziniu Hu, Student Researcher, and Alireza Fathi, Research Scientist, Google Research, Perception Team There has been great progress towards adapting largelanguagemodels (LLMs) to accommodate multimodal inputs for tasks including image captioning , visual question answering (VQA) , and open vocabulary recognition.
Multimodal LargeLanguageModels (MLLMs) have made significant progress in various applications using the power of Transformer models and their attention mechanisms. Researchers are focusing on addressing these biases without altering the model’s weights.
However, despite their impressive capabilities, diffusion models like Stable Diffusion often need help with prompts requiring spatial or common sense reasoning, leading to inaccuracies in generated images. In the first stage, an LLM is adapted to function as a text-guided layout generator through in-context learning.
However, despite the innumerable sensors, plethora of cameras, and expensive computervision techniques, this integration poses a few critical questions. This new AOI paradigm is promising and would grow with acceleration in LLM functionalities. Users also provided feedback to improve its ergonomic feasibility.
Today, we're going to discuss ChatDev, a LargeLanguageModel (LLM) based, innovative approach that aims to revolutionize the field of software development. This paradigm seeks to eliminate the need for specialized models during each phase of the development process.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content