This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
One effective way to improve context relevance is through metadata filtering, which allows you to refine search results by pre-filtering the vector store based on custom metadata attributes. By combining the capabilities of LLM function calling and Pydantic data models, you can dynamically extract metadata from user queries.
Despite advances in image and text-based AI research, the audio domain lags due to the absence of comprehensive datasets comparable to those available for computervision or natural language processing. The alignment of metadata to each audio clip provides valuable contextual information, facilitating more effective learning.
Despite their capabilities, AI & ML models are not perfect, and scientists are working towards building models that are capable of learning from the information they are given, and not necessarily relying on labeled or annotated data.
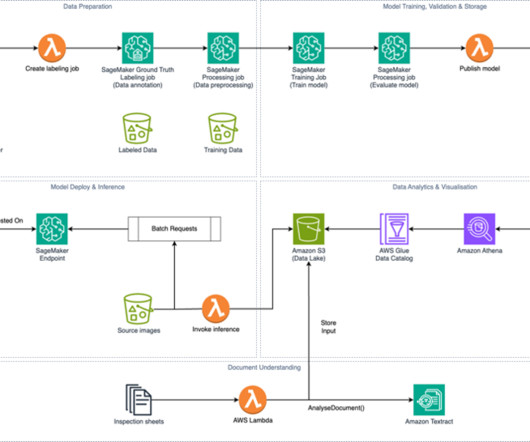
AI/ML and generative AI: Computervision and intelligent insights As drones capture video footage, raw data is processed through AI-powered models running on Amazon Elastic Compute Cloud (Amazon EC2) instances. During the flight, sensor data is processed at the edge and streamed to Amazon S3, with metadata stored in Amazon RDS.
Knowledge bases effectively bridge the gap between the broad knowledge encapsulated within foundation models and the specialized, domain-specific information that businesses possess, enabling a truly customized and valuable generative artificial intelligence (AI) experience.
Multimodal Capabilities in Detail Configuring Your Development Environment Project Structure Implementing the Multimodal Chatbot Setting Up the Utilities (utils.py) Designing the Chatbot Logic (chatbot.py) Building the Interface (app.py) Summary Citation Information Building a Multimodal Gradio Chatbot with Llama 3.2 Introducing Llama 3.2
Specifically, we cover the computervision and artificial intelligence (AI) techniques used to combine datasets into a list of prioritized tasks for field teams to investigate and mitigate. The resulting dashboard highlighted that 141 power pole assets required action, out of a network of 57,230 poles.
This solution uses decorators in your application code to capture and log metadata such as input prompts, output results, run time, and custom metadata, offering enhanced security, ease of use, flexibility, and integration with native AWS services.
Building disruptive ComputerVision applications with No Fine-Tuning Imagine a world where computervision models could learn from any set of images without relying on labels or fine-tuning. Understanding DINOv2 DINOv2 is a cutting-edge method for training computervision models using self-supervised learning.
product specifications, movie metadata, documents, etc.) These word vectors are trained from Twitter data making them semantically rich in information. Do you think learning computervision and deep learning has to be time-consuming, overwhelming, and complicated? Join me in computervision mastery.
As an Edge AI implementation, TensorFlow Lite greatly reduces the barriers to introducing large-scale computervision with on-device machine learning, making it possible to run machine learning everywhere. About us: At viso.ai, we power the most comprehensive computervision platform Viso Suite. What is TensorFlow?
In a world whereaccording to Gartner over 80% of enterprise data is unstructured, enterprises need a better way to extract meaningful information to fuel innovation. This is particularly valuable for industries handling large document volumes, where rapid access to specific information is crucial.
In recent years, advances in computervision have enabled researchers, first responders, and governments to tackle the challenging problem of processing global satellite imagery to understand our planet and our impact on it.
By linking this contextual information, the generative AI system can provide responses that are more complete, precise, and grounded in source data. GraphRAG boosts relevance and accuracy when relevant information is dispersed across multiple sources or documents, which can be seen in the following three use cases.
GPT3, LaMDA, PALM, BLOOM, and LLaMA are just a few examples of large language models (LLMs) that have demonstrated their ability to store and apply vast amounts of information. For many reasons, it is difficult for today’s most advanced vision-language models (VLMs) to respond satisfactorily to such inquiries.
This capability enables organizations to create custom inference profiles for Bedrock base foundation models, adding metadata specific to tenants, thereby streamlining resource allocation and cost monitoring across varied AI applications. He focuses on Deep learning including NLP and ComputerVision domains.
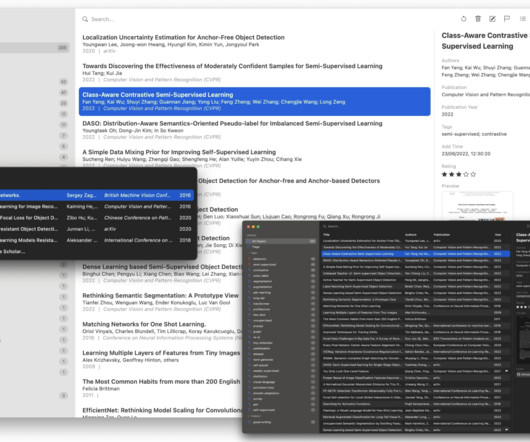
In academic research, particularly in computervision, keeping track of conference papers can be a real challenge. Unlike journal articles, conference papers often lack easily accessible metadata such as DOI or ISBN, making them harder to find and cite. We found this tool being featured on reddit.
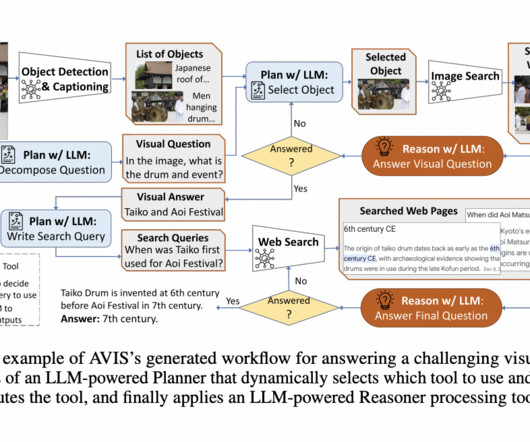
The new model combines LLMs with web search, computervision, and image search to achieve remarkable results. One of those areas is visual information-seeking tasks where external knowledge is required to answer a specific question. Throughout the process, a functional memory module retains and preserves information.
To prevent these scenarios, protection of data, user assets, and identity information has been a major focus of the blockchain security research community, as to ensure the development of the blockchain technology, it is essential to maintain its security.
Employees and managers see different levels of company policy information, with managers getting additional access to confidential data like performance review and compensation details. The role information is also used to configure metadata filtering in the knowledge bases to generate relevant responses.
Despite such achievements, current state-of-the-art visual language models (VLMs) perform inadequately on visual information seeking datasets, such as Infoseek and OK-VQA , where external knowledge is required to answer the questions. Examples of visual information seeking queries where external knowledge is required to answer the question.
Deliver new insights Expert systems can be trained on a corpus—metadata used to train a machine learning model—to emulate the human decision-making process and apply this expertise to solve complex problems. Transportation AI informs many transportation systems these days.
From predicting traffic flow to sales forecasting, accurate predictions enable organizations to make informed decisions, mitigate risks, and allocate resources efficiently. It stores models, organizes model versions, captures essential metadata and artifacts such as container images, and governs the approval status of each model.
Bias detection in ComputerVision (CV) aims to find and eliminate unfair biases that can lead to inaccurate or discriminatory outputs from computervision systems. Computervision has achieved remarkable results, especially in recent years, outperforming humans in most tasks. Let’s get started.
Examples include financial systems processing transaction data streams, recommendation engines processing user activity data, and computervision models processing video frames. The information pertaining to the request and response is stored in Amazon S3. Args: input_data (obj): the request data.
You can use advanced parsing options supported by Amazon Bedrock Knowledge Bases for parsing non-textual information from documents using FMs. Some documents benefit from semantic chunking by preserving the contextual relationship in the chunks, helping make sure that the related information stays together in logical chunks.
Inspect Rich Documents with Gemini Multimodality and Multimodal RAG This course covers using multimodal prompts to extract information from text and visual data and generate video descriptions with Gemini. TensorFlow on Google Cloud This course covers designing TensorFlow input data pipelines and building ML models with TensorFlow and Keras.
Advanced parsing Advanced parsing is the process of analyzing and extracting meaningful information from unstructured or semi-structured documents. It involves breaking down the document into its constituent parts, such as text, tables, images, and metadata, and identifying the relationships between these elements.
In computervision datasets, if we can view and compare the images across different views with their relevant metadata and transformations within a single and well-designed UI, we are one step ahead in solving a CV task. Adding image metadata. Locate the “Metadata” section and toggle the dropdown. jpeg').to_pil()
Every episode is focused on one specific ML topic, and during this one, we talked to Michal Tadeusiak about managing computervision projects. I’m joined by my co-host, Stephen, and with us today, we have Michal Tadeusiak , who will be answering questions about managing computervision projects.
Scientific metadata in research literature holds immense significance, as highlighted by flourishing research in scientometricsa discipline dedicated to analyzing scholarly literature. Metadata improves the findability and accessibility of scientific documents by indexing and linking papers in a massive graph.
Jump Right To The Downloads Section People Counter on OAK Introduction People counting is a cutting-edge application within computervision, focusing on accurately determining the number of individuals in a particular area or moving in specific directions, such as “entering” or “exiting.” Looking for the source code to this post?
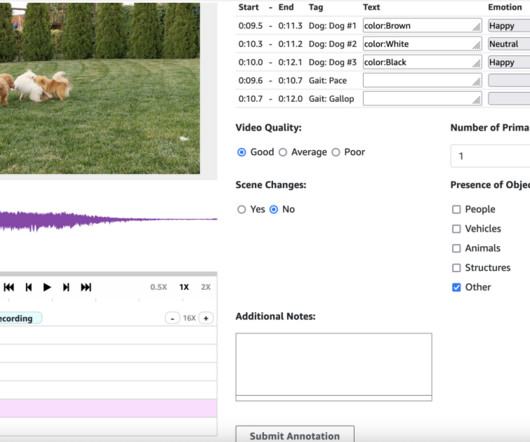
We start with a simple scenario: you have an audio file stored in Amazon S3, along with some metadata like a call ID and its transcription. What feature would you like to see added ? " } You can adapt this structure to include additional metadata that your annotation workflow requires.
Highly specialized distributed learning algorithms and efficient serving mechanisms are required to process and serve such massive information in the user base and video corpus. Noise: The metadata associated with the content doesn’t have a well-defined ontology. This way, MoE can learn modularized information from the input.
The personalization of LLM applications can be achieved by incorporating up-to-date user information, which typically involves integrating several components. A media metadata store keeps the promotion movie list up to date. The agent takes the promotion item list (movie name, description, genre) from a media metadata store.
You can use state-of-the-art model architecturessuch as language models, computervision models, and morewithout having to build them from scratch. For more information about version updates, see Shut down and Update Studio Classic Apps. With SageMaker JumpStart, you can deploy models in a secure environment.
Here are some features which we will cover: AWS CloudFormation support Private network policies for Amazon OpenSearch Serverless Multiple S3 buckets as data sources Service Quotas support Hybrid search, metadata filters, custom prompts for the RetreiveAndGenerate API, and maximum number of retrievals.
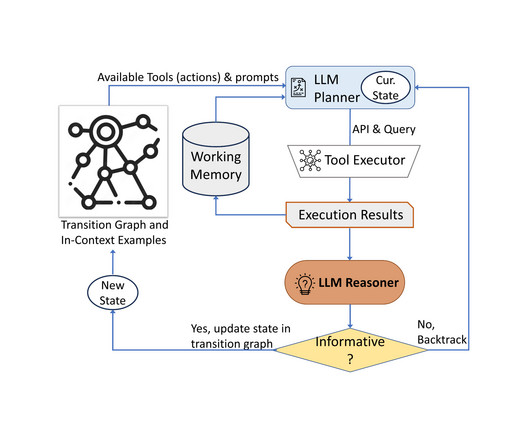
This involves cutting out and replacing hidden representations between different prompts and layers, allowing for a detailed inspection of the information contained within. This prompt serves as the context from which information will be extracted. across different layers of the model.
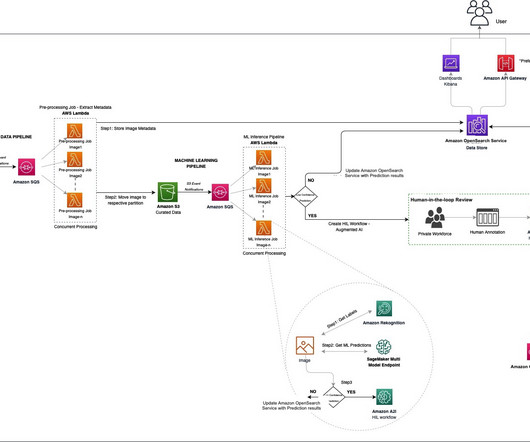
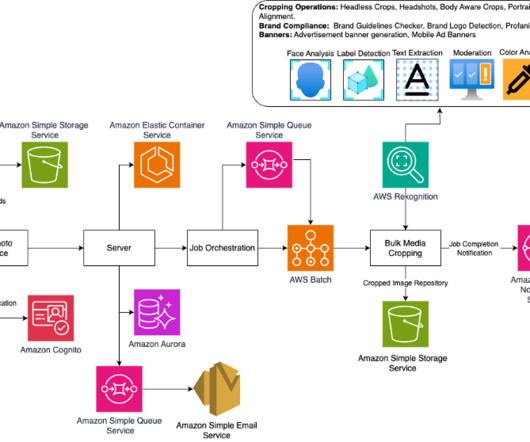
Media and job storage Information about uploaded files and job execution is stored in Amazon Aurora. Amazon Rekognition is an AWS computervision service that powers Crop.photos automated image analysis. The system highlights text areas to make sure critical product information remains legible after cropping.
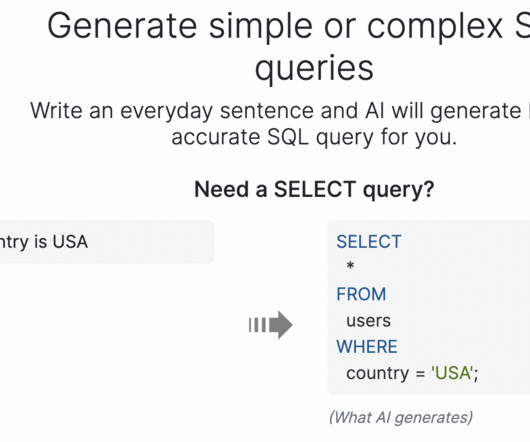
It is simple to understand and translate a sentence like “clients with their orders and remarks from the last three months” into: However, since the input doesn’t provide much information about the potential database schema, AI Bot must “guess” the names of the tables and columns.
To ensure the highest quality measurement of your question answering application against ground truth, the evaluation metrics implementation must inform ground truth curation. For more information, see the Amazon Bedrock documentation on LLM prompt design and the FMEval documentation.
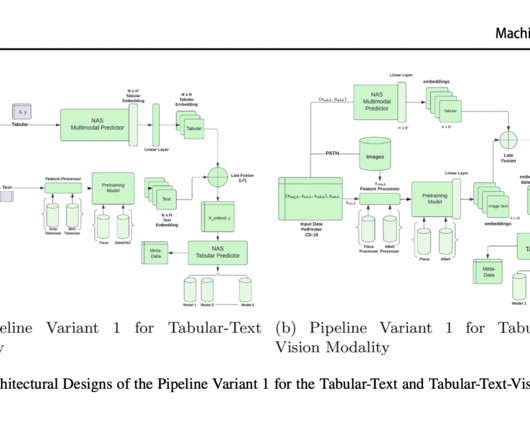
There are currently no systematic comparisons between different information fusion approaches and no generalized frameworks for multi-modality processing; these are the main obstacles to multimodal AutoML. Nevertheless, a major obstacle that many current AutoML systems encounter is the efficient and correct handling of multimodal data.
This includes various products related to different aspects of AI, including but not limited to tools and platforms for deep learning, computervision, natural language processing, machine learning, cloud computing, and edge AI. Viso Suite enables organizations to solve the challenges of scaling computervision.
This graph integrates public and internal databases with information from scientific literature, modeling between 10 million and 1 billion complex biological relationships. However, the value of this imagery can be limited if it lacks specific location metadata. million-x speedup, returning results in 67 microseconds.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content