This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
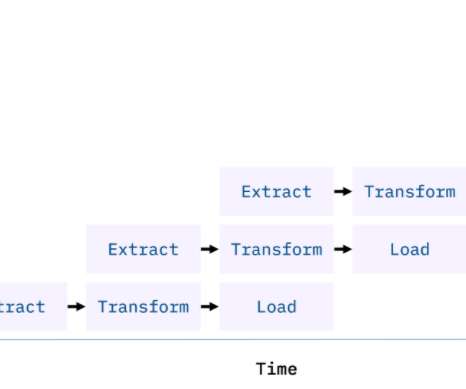
Introduction ETL pipelines can be built from bash scripts. You will learn about how shell scripting can implement an ETL pipeline, and how ETL scripts or tasks can be scheduled using shell scripting. The post ETL Pipeline using Shell Scripting | Data Pipeline appeared first on Analytics Vidhya. What is shell scripting?
An Amazon EventBridge schedule checked this bucket hourly for new files and triggered log transformation extract, transform, and load (ETL) pipelines built using AWS Glue and Apache Spark. Creating ETL pipelines to transform log data Preparing your data to provide quality results is the first step in an AI project.
The embeddings are captured in Amazon Simple Storage Service (Amazon S3) via Amazon Kinesis Data Firehose , and we run a combination of AWS Glue extract, transform, and load (ETL) jobs and Jupyter notebooks to perform the embedding analysis. Set the parameters for the ETL job as follows and run the job: Set --job_type to BASELINE.
Just like this in Data Science we have Data Analysis , Business Intelligence , Databases , Machine Learning , Deep Learning , ComputerVision , NLP Models , Data Architecture , Cloud & many things, and the combination of these technologies is called Data Science. Data Science and AI are related?
Pryon’s platform integrates advanced AI technologies like computervision and large language models. Essentially, it performs ETL (Extract, Transform, Load) on the left side, powering experiences via APIs on the right side. That was the birth of Pryon, the world’s first AI-enhanced knowledge cloud.
It can automate extract, transform, and load (ETL) processes, so multiple long-running ETL jobs run in order and complete successfully without manual orchestration. By combining multiple Lambda functions, Step Functions allows you to create responsive serverless applications and orchestrate microservices.
These courses cover foundational topics such as machine learning algorithms, deep learning architectures, natural language processing (NLP), computervision, reinforcement learning, and AI ethics. Udacity offers comprehensive courses on AI designed to equip learners with essential skills in artificial intelligence.
Hippocratic raised $50 million to accelerate their vision of creating LLM models for healthcare. million to accelerate its AI-first ETL platform. Visual Layer announced a $7 million round to help enterprises manage datasets for computervision models. Union AI raised $19.1
About the authors Samantha Stuart is a Data Scientist with AWS Professional Services, and has delivered for customers across generative AI, MLOps, and ETL engagements. Start implementing a robust ground truth generation and review processes for your generative AI question-answering evaluations today with FMEval.
This wasnt just true for speech recognition it held across language processing, computervision, and even mathematical reasoning. Three critical ingredients must scale together: Larger neural networks More training data Increased computing power If any one ingredient falls short while the others grow, progress stalls.
But, it does not give you all the information about the different functionalities and services, like Data Factory/Linked Services/Analytics Synapse(how to combine and manage databases, ETL), Cognitive Services/Form Recognizer/ (how to do image, text, audio processing), IoT, Deployment, GitHub Actions (running Azure scripts from GitHub).
For examples on using asynchronous inference with unstructured data such as computervision and natural language processing (NLP), refer to Run computervision inference on large videos with Amazon SageMaker asynchronous endpoints and Improve high-value research with Hugging Face and Amazon SageMaker asynchronous inference endpoints , respectively.
TR used AWS Glue DataBrew and AWS Batch jobs to perform the extract, transform, and load (ETL) jobs in the ML pipelines, and SageMaker along with Amazon Personalize to tailor the recommendations. He is passionate about recommendation systems, NLP, and computervision areas in AI and ML.
They build production-ready systems using best-practice containerisation technologies, ETL tools and APIs. Data engineers are the glue that binds the products of data scientists into a coherent and robust data pipeline. They are skilled at deploying to any cloud or on-premises infrastructure.
Fast and Scalable XLA Compilation Distributed Computing Performance Optimization Applied ML New tools for CV and NLP Production Grade Solutions Developer Resources Ready To Deploy Easier Exporting C++ API for applications Deploy JAX Models Simplicity NumPy API Easier Debugging OpenAI opens the public access for Dall-E model in this blog post.
Furthermore, in addition to common extract, transform, and load (ETL) tasks, ML teams occasionally require more advanced capabilities like creating quick models to evaluate data and produce feature importance scores or post-training model evaluation as part of an MLOps pipeline. In her spare time, she enjoys movies, music, and literature.
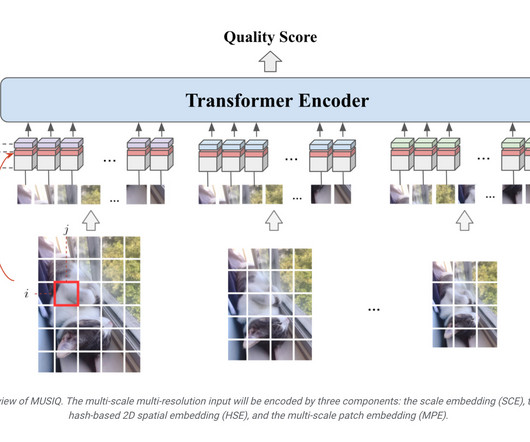
It’s optimized with performance features like indexing, and customers have seen ETL workloads execute up to 48x faster. It helps data engineering teams by simplifying ETL development and management. ComputerVision algorithms can be employed for image recognition and analysis. Dean, J., & Ghemawat, S. Morgan Kaufmann.
On the computervision team, we try to use the most straightforward solutions possible. For example, when the computervision team works with image data that requires labeling, managing the model in production will be different from working with tabular data that is processed in another way. “We
You can use these connections for both source and target data, and even reuse the same connection across multiple crawlers or extract, transform, and load (ETL) jobs. These connections are used by AWS Glue crawlers, jobs, and development endpoints to access various types of data stores.
This is the ETL (Extract, Transform, and Load) layer that combines data from multiple sources, cleans noise from the data, organizes raw data, and prepares for model training. In this section, I will talk about best practices around building the Data Processing platform.
Let’s combine these suggestions to improve upon our original prompt: Human: Your job is to act as an expert on ETL pipelines. Specifically, your job is to create a JSON representation of an ETL pipeline which will solve the user request provided to you.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content