This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
And in the 2nd blog of this series , you were introduced to NeRFs, which is 3D Reconstruction via NeuralNetworks, projecting points in the 3D space. Do you think learning computervision and deep learning has to be time-consuming, overwhelming, and complicated? Or requires a degree in computer science?
To learn how to master YOLO11 and harness its capabilities for various computervision tasks , just keep reading. Jump Right To The Downloads Section What Is YOLO11? This breakdown makes YOLO11 versatile, fast, and ideal for modern computervision challenges. Looking for the source code to this post?
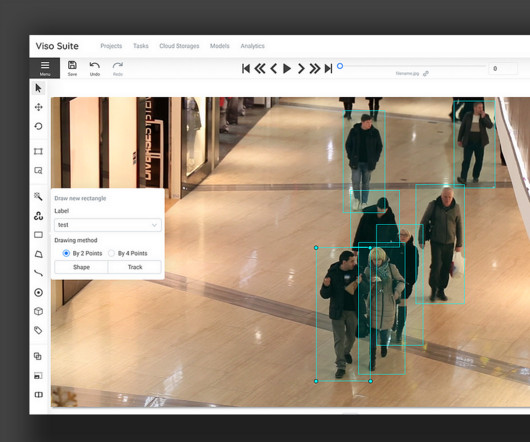
The computervision annotation tool CVAT provides a powerful solution for image annotation in computervision. Computationalvision is the research field that uses machines to collect and analyze images and videos to extract information from processed visual data. Get a demo or the whitepaper.
Indeed, after obtaining a neuralnetwork that accurately predicts all the test data, it remains useless unless it’s made accessible to the world. With Detectron2, you can easily build and fine-tune neuralnetworks to accurately detect and segment objects in images and videos.
To learn about ComputerVision and Deep Learning for Education, just keep reading. ComputerVision and Deep Learning for Education Benefits Smart Content Artificial Intelligence can help teachers and research experts create innovative and personalized content for their students. Or requires a degree in computer science?
Save this blog for comprehensive resources for computervision Source: appen Working in computervision and deep learning is fantastic because, after every few months, someone comes up with something crazy that completely changes your perspective on what is feasible. Also, they will show you how huge this domain is.
Project Structure Accelerating Convolutional NeuralNetworks Parsing Command Line Arguments and Running a Model Evaluating Convolutional NeuralNetworks Accelerating Vision Transformers Evaluating Vision Transformers Accelerating BERT Evaluating BERT Miscellaneous Summary Citation Information What’s New in PyTorch 2.0?
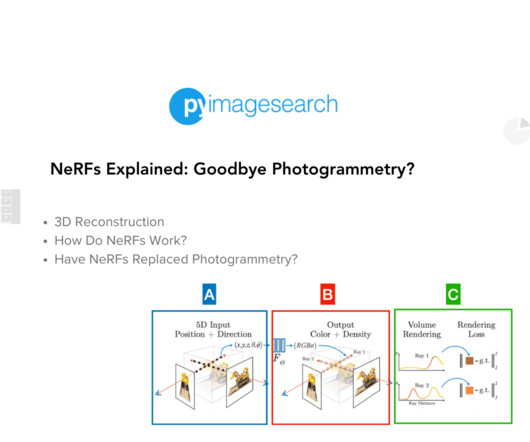
Block #A: We Begin with a 5D Input Block #B: The NeuralNetwork and Its Output Block #C: Volumetric Rendering The NeRF Problem and Evolutions Summary and Next Steps Next Steps Citation Information NeRFs Explained: Goodbye Photogrammetry? And the “neural” radiance field estimates it using NeuralNetworks.
If you are a regular PyImageSearch reader and have even basic knowledge of Deep Learning in ComputerVision, then this tutorial should be easy to understand. Start by accessing the “Downloads” section of this tutorial to retrieve the source code and example images. Before you load this data, you need to download it from Kaggle.
This article will cover image recognition, an application of Artificial Intelligence (AI), and computervision. Image recognition with deep learning is a key application of AI vision and is used to power a wide range of real-world use cases today. Get a personalized demo. link] What is Image Recognition?
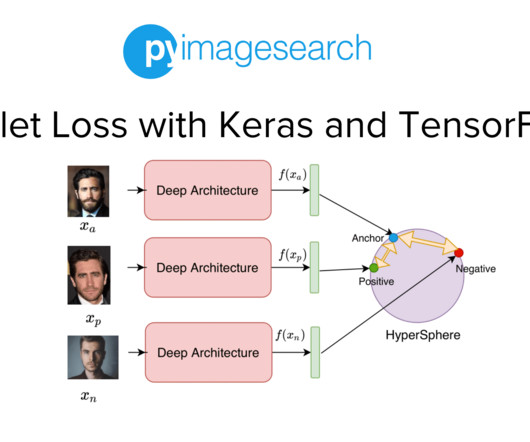
Jump Right To The Downloads Section Triplet Loss with Keras and TensorFlow In the first part of this series, we discussed the basic formulation of a contrastive loss and how it can be used to learn a distance measure based on similarity. Or requires a degree in computer science? Join me in computervision mastery.
MoE models like DeepSeek-V3 and Mixtral replace the standard feed-forward neuralnetwork in transformers with a set of parallel sub-networks called experts. These experts are selectively activated for each input, allowing the model to efficiently scale to a much larger size without a corresponding increase in computational cost.
The second blog post will introduce you to NeRFs , the neuralnetwork solution. Y ou may have recently heard this term via Apple and Google, or you may have seen them when studying techniques to take an image to a 3D model, when learning SLAM, or when looking at 3D ComputerVision. Join me in computervision mastery.
Jump Right To The Downloads Section Introduction to Causality in Machine Learning So, what does causal inference mean? Do you think learning computervision and deep learning has to be time-consuming, overwhelming, and complicated? Or requires a degree in computer science? Join me in computervision mastery.
Table of Contents OAK-D: Understanding and Running NeuralNetwork Inference with DepthAI API Introduction Configuring Your Development Environment Having Problems Configuring Your Development Environment? Start by accessing the “Downloads” section of this tutorial to retrieve the source code and example images.
An autoencoder is an artificial neuralnetwork used for unsupervised learning tasks (i.e., Sequence-to-Sequence Autoencoder Also known as a Recurrent Autoencoder, this type of autoencoder utilizes recurrent neuralnetwork (RNN) layers (e.g., Or requires a degree in computer science? What Are Autoencoders?
Guerena’s project, called Artemis, uses AI and computervision to speed up the phenotyping process. A computer doesn’t have these problems. Well-trained computervision models produce consistent quantitative data instantly.”
Jump Right To The Downloads Section Learning JAX in 2023: Part 3 — A Step-by-Step Guide to Training Your First Machine Learning Model with JAX We conclude our “ Learning JAX in 2023 ” series with a hands-on tutorial. In the context of a neuralnetwork, a PyTree can be used to represent the weights and biases of the network.
For example, image classification, image search engines (also known as content-based image retrieval, or CBIR), simultaneous localization and mapping (SLAM), and image segmentation, to name a few, have all been changed since the latest resurgence in neuralnetworks and deep learning. Object detection is no different. 2015 ; He et al.,
To learn how to develop Face Recognition applications using Siamese Networks, just keep reading. Jump Right To The Downloads Section Face Recognition with Siamese Networks, Keras, and TensorFlow Deep learning models tend to develop a bias toward the data distribution on which they have been trained. That’s not the case.
ComputerVision and Deep Learning for Oil and Gas ComputerVision and Deep Learning for Transportation ComputerVision and Deep Learning for Logistics ComputerVision and Deep Learning for Healthcare (this tutorial) ComputerVision and Deep Learning for Education To learn about ComputerVision and Deep Learning for Healthcare, just keep reading.
Modern ComputerVision (CV) applications are executed on the edge, i.e. directly on remote client devices. Edge computing depends on high speed and low latency to transfer large quantities of data in real-time. Moreover, applications like edge computing are necessary for 5G to sustain its expansion and coverage.
Starting with the input image , which has 3 color channels, the authors employ a standard Convolutional NeuralNetwork (CNN) to create a lower-resolution activation map. The feed-forward neuralnetwork (FFN) predicts the bounding box’s normalized center coordinates, height, and width with respect to the input image.
Specifically, we will discuss the following in detail: Positive and Negative data samples required to train a network with contrastive loss Specific data preprocessing techniques (e.g., Start by accessing the “Downloads” section of this tutorial to retrieve the source code and example images. Or requires a degree in computer science?
Jump Right To The Downloads Section What’s Behind PyTorch 2.0? installed on your system, you can download all the required dependencies in the PyTorch nightly binaries with docker. Start by accessing the “Downloads” section of this tutorial to retrieve the source code. Or requires a degree in computer science?
Jump Right To The Downloads Section Learning JAX in 2023: Part 1 — The Ultimate Guide to Accelerating Numerical Computation and Machine Learning ?? Automatic differentiation (autodiff) is the type of differentiation we all love and use when training our deep neuralnetworks. Or requires a degree in computer science?
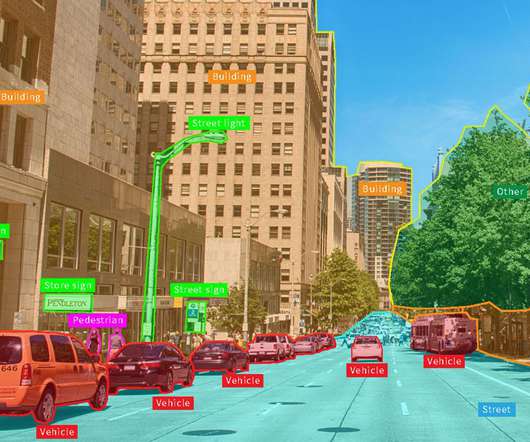
ComputerVision Datasets Object Detection What Is Object Detection Object detection is a cool technique that allows computers to see and understand what’s in an image or a video. The world relies increasingly on fish protein, so you might want to check out this fish dataset and explore the world of underwater computervision.
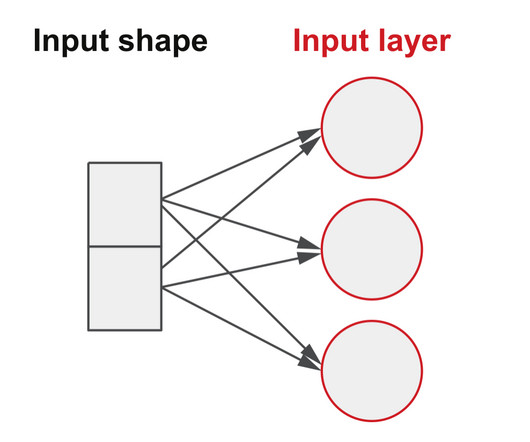
It provides an introduction to deep neuralnetworks in Python. Andrew is an expert on computervision, deep learning, and operationalizing ML in production at Google Cloud AI Developer Relations. NeuralNetwork Basics We will start with some basics on neuralnetworks. Everything is a number.
Traditional 2D neuralnetwork-based segmentation methods still need to be fully optimized for these high-dimensional imaging modalities, highlighting the need for more advanced approaches to handle the increased data complexity effectively. The platform encourages community contributions to expand its model repository.
Jump Right To The Downloads Section Training and Making Predictions with Siamese Networks and Triplet Loss In the second part of this series, we developed the modules required to build the data pipeline for our face recognition application. Or requires a degree in computer science? Join me in computervision mastery.
Value of AI models for businesses The most popular AI models AI models in computervision applications – Viso Suite About us: We provide the platform Viso Suite to collect data and train, deploy, and scale AI models on powerful infrastructure. In computervision, this process is called image annotation.
Jump Right To The Downloads Section Scaling Kaggle Competitions Using XGBoost: Part 4 If you went through our previous blog post on Gradient Boosting, it should be fairly easy for you to grasp XGBoost, as XGBoost is heavily based on the original Gradient Boosting algorithm. kaggle/kaggle.json # download the required dataset from kaggle !kaggle
Jump Right To The Downloads Section People Counter on OAK Introduction People counting is a cutting-edge application within computervision, focusing on accurately determining the number of individuals in a particular area or moving in specific directions, such as “entering” or “exiting.” mp4 │ └── example_02.mp4
Visit the NVIDIA Driver Download page , select the appropriate driver for your GPU, and note the driver version. To check for prebuilt GPU packages on Ubuntu, run: sudo ubuntu-drivers list --gpgpu Reboot your computer and verify the installation: nvidia-smi 2. Install cuDNN Download the cuDNN package from the NVIDIA Developer website.
Additionally, YOLOv8 supports the latest computervision algorithms, including instance segmentation, which allows for the detection of multiple objects in an image. Firstly, YOLOv8 introduces a new backbone network, Darknet-53, which is significantly faster and more accurate than the previous backbone used in YOLOv7.
An Introduction to Image Segmentation Image segmentation is a massively popular computervision task that deals with the pixel-level classification of images. Note: Downloading the dataset takes 1.2 Now, let’s download the dataset from the ? Download SceneParsing instance segmentation labels !wget
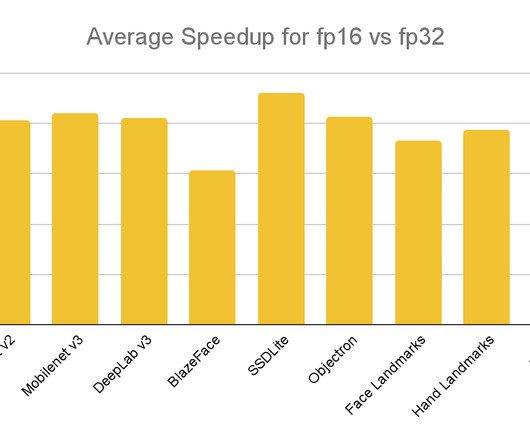
Performance Improvements Half-precision inference has already been battle-tested in production across Google Assistant, Google Meet, YouTube, and ML Kit, and demonstrated close to 2X speedups across a wide range of neuralnetwork architectures and mobile devices. The average speedup is shown below.
The overall system ( Figure 2 ) consists of two neuralnetworks for candidate generation and ranking. The candidate generation network aims to filter out a few thousand video candidates from the vast corpus based on user watch history and context. Or requires a degree in computer science? RecSys’16 ). RecSys’16 ).
Jump Right To The Downloads Section Scaling Kaggle Competitions Using XGBoost: Part 3 Gradient Boost at a Glance In the first blog post of this series, we went through basic concepts like ensemble learning and decision trees. Do you think learning computervision and deep learning has to be time-consuming, overwhelming, and complicated?
This is especially the case when thinking about the robustness and fairness of deep neuralnetwork models, both of which are essential for models used in practical settings in addition to their sheer accuracy. A trained deep neuralnetwork’s full capabilities, including its robustness, can be assessed this way.
Since it helps robots understand and interpret visual input, image annotation is vital in computervision, robotics, and autonomous driving. is a no-download, no-install internet application for labeling photographs. CVAT is available to companies as part of the Viso Suite computervision application suite.
Having a grasp of this concept enables you to do flexible tasks with the feature space, and reframe ML/DL problems differently, especially with high-dimensional data in ComputerVision and Natural Language Processing. You can download the images here [4]. You can download the data here (product images by [5]).
Jump Right To The Downloads Section Adversarial Learning with Keras and TensorFlow (Part 2): Implementing the Neural Structured Learning (NSL) Framework and Building a Data Pipeline The TensorFlow NSL framework allows neuralnetworks to learn with structured data. Given the input image and the structure (i.e.,
Jump Right To The Downloads Section A Deep Dive into Variational Autoencoder with PyTorch Introduction Deep learning has achieved remarkable success in supervised tasks, especially in image recognition. Before the rise of GANs, there were other foundational neuralnetwork architectures for generative modeling. on Lines 6 and 7.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content