This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Envision yourself as an MLEngineer at one of the world’s largest companies. You make a Machine Learning (ML) pipeline that does everything, from gathering and preparing data to making predictions. Download the RPM (Red Hat Package Management system) file for Docker Desktop ( Note: This link may change in the future.
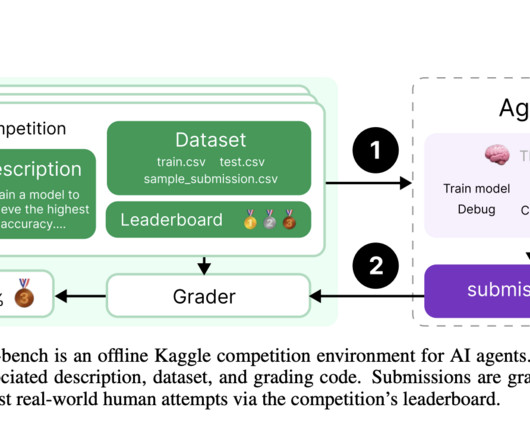
Machine Learning (ML) models have shown promising results in various coding tasks, but there remains a gap in effectively benchmarking AI agents’ capabilities in MLengineering. MLE-bench is a novel benchmark aimed at evaluating how well AI agents can perform end-to-end machine learning engineering.
Getting Used to Docker for Machine Learning Introduction Docker is a powerful addition to any development environment, and this especially rings true for MLEngineers or enthusiasts who want to get started with experimentation without having to go through the hassle of setting up several drivers, packages, and more. the image).
[link] Transfer learning using pre-trained computervision models has become essential in modern computervision applications. In this article, we will explore the process of fine-tuning computervision models using PyTorch and monitoring the results using Comet. Pre-trained models, such as VGG, ResNet.
is a state-of-the-art vision segmentation model designed for high-performance computervision tasks, enabling advanced object detection and segmentation workflows. You can now use state-of-the-art model architectures, such as language models, computervision models, and more, without having to build them from scratch.
About us: We are viso.ai, the creators of the end-to-end computervision platform, Viso Suite. With Viso Suite, enterprises can get started using computervision to solve business challenges without any code. Viso Suite : the only end-to-end computervision platform Detectron2: What’s Inside?
You can use state-of-the-art model architecturessuch as language models, computervision models, and morewithout having to build them from scratch. Image 1: Image 2: Input: def url_to_base64(image_url): # Download the image response = requests.get(image_url) if response.status_code != b64encode(img).decode('utf-8')
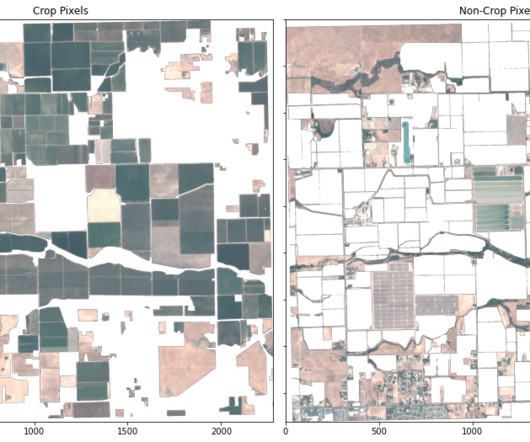
Planet and AWS’s partnership on geospatial ML SageMaker geospatial capabilities empower data scientists and MLengineers to build, train, and deploy models using geospatial data. This example uses the Python client to identify and download imagery needed for the analysis. Xiong Zhou is a Senior Applied Scientist at AWS.
Throughout this exercise, you use Amazon Q Developer in SageMaker Studio for various stages of the development lifecycle and experience firsthand how this natural language assistant can help even the most experienced data scientists or MLengineers streamline the development process and accelerate time-to-value.
You can download the generated images directly from the UI or check the image in your S3 bucket. About the Authors Akarsha Sehwag is a Data Scientist and MLEngineer in AWS Professional Services with over 5 years of experience building ML based solutions.
SageMaker AI starts and manages all the necessary Amazon Elastic Compute Cloud (Amazon EC2) instances for us, supplies the appropriate containers, downloads data from our S3 bucket to the container and uploads and runs the specified training script, in our case fine_tune_llm.py. Moran Beladev is a Senior ML Manager at Booking.com.
Voxel51 is the company behind FiftyOne, the open-source toolkit for building high-quality datasets and computervision models. Solution overview Ground Truth is a fully self-served and managed data labeling service that empowers data scientists, machine learning (ML) engineers, and researchers to build high-quality datasets.
You can now use state-of-the-art model architectures, such as language models, computervision models, and more, without having to build them from scratch. Single-image input You can set up vision-based reasoning tasks with Llama 3.2 With SageMaker JumpStart, you can deploy models in a secure environment. models today.
Data scientists and machine learning (ML) engineers use pipelines for tasks such as continuous fine-tuning of large language models (LLMs) and scheduled notebook job workflows. Download the pipeline definition as a JSON file to your local environment by choosing Export at the bottom of the visual editor.
Rather than downloading the data to a local machine for inferences, SageMaker does all the heavy lifting for you. SageMaker automatically downloads and preprocesses the satellite image data for the EOJ, making it ready for inference. This land cover segmentation model can be run with a simple API call.
2 For dynamic models, such as those with variable-length inputs or outputs, which are frequent in natural language processing (NLP) and computervision, PyTorch offers improved support. To save the model using ONNX, you need to have onnx and onnxruntime packages downloaded in your system. In this example, I’ll use the Neptune.
MLOps workflows for computervision and ML teams Use-case-centric annotations. Data storage and versioning You need data storage and versioning tools to maintain data integrity, enable collaboration, facilitate the reproducibility of experiments and analyses, and ensure accurate ML model development and deployment.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content