This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
One of the computervision applications we are most excited about is the field of robotics. By marrying the disciplines of computervision, natural language processing, mechanics, and physics, we are bound to see a frameshift change in the way we interact with, and are assisted by robot technology.
One of the computervision applications we are most excited about is the field of robotics. By marrying the disciplines of computervision, natural language processing, mechanics, and physics, we are bound to see a frameshift change in the way we interact with, and are assisted by robot technology.
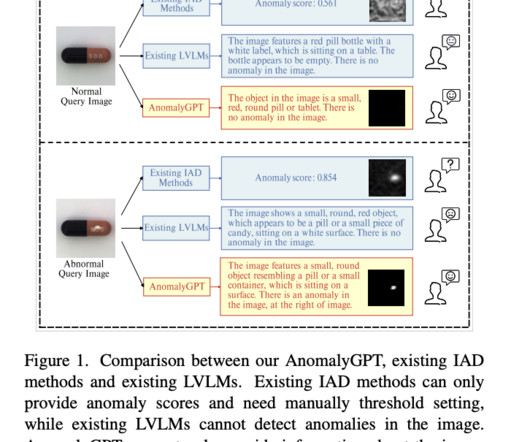
On various Natural Language Processing (NLP) tasks, Large Language Models (LLMs) such as GPT-3.5 They optimize the LVLM using synthesized anomalous visual-textual data and incorporating IAD expertise. Direct training using IAD data, however, needs to be improved. Datascarcity is the first.
A key finding is that for a fixed compute budget, training with up to four epochs of repeated data shows negligible differences in loss compared to training with unique data. However, beyond four epochs, the additional computational investment yields diminishing returns.
SegGPT Many successful approaches from NLP are now being translated into computervision. For instance, the analogy of the masked token prediction task used to train BERT is known as masked image modeling in computervision. Comparison of few-shot inference between NLP and CV. Source: own study.
By leveraging auxiliary information such as semantic attributes, ZSL enhances scalability, reduces data dependency, and improves generalisation. This innovative approach is transforming applications in computervision, Natural Language Processing, healthcare, and more.
In this article, we’ll discuss the following: What is synthetic data? Organizations can easily source data to promote the development, deployment, and scaling of their computervision applications. Viso Suite is the End-to-End, No-Code ComputerVision Platform – Learn more What is Synthetic Data?
Thus it reduces the amount of data and computational need. Transfer Learning has various applications like computervision, NLP, recommendation systems, and robotics. This technology allows models to be fine-tuned using a limited amount of data. Thus it is computationally lesser expensive.
SegGPT Many successful approaches from NLP are now being translated into computervision. For instance, the analogy of the masked token prediction task used to train BERT is known as masked image modeling in computervision. Comparison of few-shot inference between NLP and CV. Source: own study.
Symbolic Music Understanding ( MusicBERT ): MusicBERT is based on the BERT (Bidirectional Encoder Representations from Transformers) NLP model. It focuses on generating hip-hop rap lyrics, utilizing NLP and machine learning techniques to produce rhythmically and thematically coherent verses.
Overcoming datascarcity with translation and synthetic data generation When fine-tuning a custom version of the Mistral 7B LLM for the Italian language, Fastweb faced a major obstacle: high-quality Italian datasets were extremely limited or unavailable. In his free time, Giuseppe enjoys playing football.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















Let's personalize your content