This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Voxel51, a prominent innovator in data-centric computervision and machine learning software, has recently introduced a remarkable breakthrough in the field of computervision with the launch of VoxelGPT. ’s Power to Generate Python Code for ComputerVision Dataset Analysis appeared first on MarkTechPost.
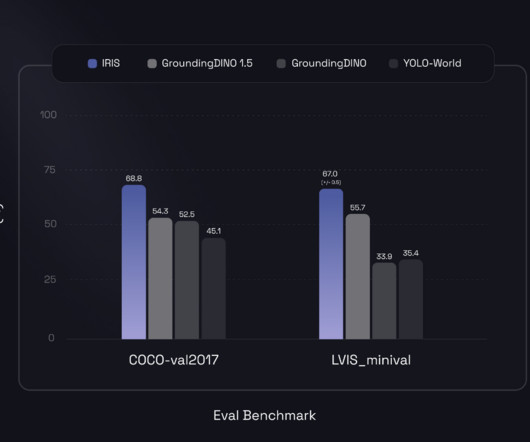
Combining pre-trained zero-shot models to construct strong custom computervision solutions is simple using Overeasy. Also, launched by Overeasy, IRIS is an exciting artificial intelligence agent with game-changing potential in computervision. It can also generate bounding boxes around objects in images.
Unlike traditional computervision models that rely on manual feature crafting, LVMs leverage deep learning techniques, utilizing extensive datasets to generate authentic and diverse outputs. Prioritizing dataquality, establishing governance policies, and complying with relevant regulations are important steps.
Alix Melchy is the VP of AI at Jumio, where he leads teams of machine learning engineers across the globe with a focus on computervision, natural language processing and statistical modeling. The role of AI in identity verification will continue to expand significantly over the next five years.
Wake Vision's comprehensive filtering and labeling process significantly enhances the dataset's quality. Why DataQuality Matters for TinyML Models In traditional overparameterized models, it is widely believed that data quantity matters more than dataquality, as an overparameterized model can adapt to errors in the training data.
As many areas of artificial intelligence (AI) have experienced exponential growth, computervision is no exception. According to the data from the recruiting platforms – job listings that look for artificial intelligence or computervision specialists doubled from 2021 to 2023.
In many computervision applications (e.g. Such image fusion will provide higher reliability, accuracy, and dataquality. provides a robust end-to-end no-code computervision solution – Viso Suite. Viso Suite is the end-to-end computervision application infrastructure. About us : Viso.ai
Manufacturers must adopt strict cybersecurity practices to protect their data while adhering to regulatory requirements, maintaining trust, and safeguarding their operations. DataQuality and Preprocessing The effectiveness of AI applications in manufacturing heavily depends on the quality of the data fed into the models.
Large-scale pretraining followed by task-specific fine-tuning has revolutionized language modeling and is now transforming computervision. The paper introduces a novel approach to human-centric computervision through Sapiens, a family of vision transformer models.
With over 3 years of experience in designing, building, and deploying computervision (CV) models , I’ve realized people don’t focus enough on crucial aspects of building and deploying such complex systems. Hopefully, at the end of this blog, you will know a bit more about finding your way around computervision projects.
Beyond Scale: DataQuality for AI Infrastructure The trajectory of AI over the past decade has been driven largely by the scale of data available for training and the ability to process it with increasingly powerful compute & experimental models. Author(s): Richie Bachala Originally published on Towards AI.
While important for complying with privacy regulations, anonymization often reduces dataquality, which hampers computervision development. Several challenges exist, such as data degradation, balancing privacy and utility, creating efficient algorithms, and negotiating moral and legal issues.
With the emergence of new advances and applications in machine learning models and artificial intelligence, including generative AI, generative adversarial networks, computervision and transformers, many businesses are seeking to address their most pressing real-world data challenges using both types of synthetic data: structured and unstructured.
Artificial intelligence solutions are transforming businesses across all industries, and we at LXT are honored to provide the high-qualitydata to train the machine learning algorithms that power them. Speech and audio processing is rapidly approaching near perfection when it comes to English and specifically white men.
ComputerVision Datasets Object Detection What Is Object Detection Object detection is a cool technique that allows computers to see and understand what’s in an image or a video. The world relies increasingly on fish protein, so you might want to check out this fish dataset and explore the world of underwater computervision.
Computervision focuses on enabling devices to interpret & understand visual information from the world. This involves various tasks such as image recognition, object detection, and visual search, where the goal is to develop models that can process and analyze visual data effectively. Check out the Paper.
Denoising Autoencoders (DAEs) Denoising autoencoders are trained on corrupted versions of the input data. The model learns to reconstruct the original data from this noisy input, making them effective for tasks like image denoising and signal processing. They help improve dataquality by filtering out noise.
Multimodal large language models (MLLMs) represent a cutting-edge intersection of language processing and computervision, tasked with understanding and generating responses that consider both text and imagery. Quantitative improvements in several key performance metrics underscore the efficacy of studied models.
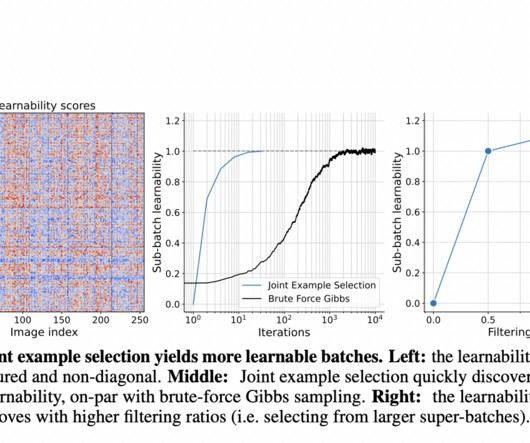
Model-based data curation, leveraging training model features to select high-qualitydata, offers potential improvements in scaling efficiency. Traditional methods focus on individual data points, but batch quality also depends on composition.
In quality control, an outlier could indicate a defect in a manufacturing process. By understanding and identifying outliers, we can improve dataquality, make better decisions, and gain deeper insights into the underlying patterns of the data. Thakur, eds., Join the Newsletter!
Steps for building a successful AI strategy The following steps are commonly used to help craft an effective artificial intelligence strategy: Explore the technology Gain an understanding of various AI technologies, including generative AI , machine learning (ML), natural language processing, computervision, etc.
Dataquality plays a crucial role in AI model development. Could you share how Appen ensures the accuracy, diversity, and relevance of its datasets, especially with the increasing demand for high-quality LLM training data? We feel we are just at the beginning of the largest AI wave.
Common Types of Data Labeling in AI Domains 1. ComputerVision Image classification: The process of giving an image one or more tags. Disadvantages of Data Labeling Time and Cost: Manual labeling requires a lot of resources. Human error: Dataquality is impacted by mislabeling brought on by bias or cognitive exhaustion.
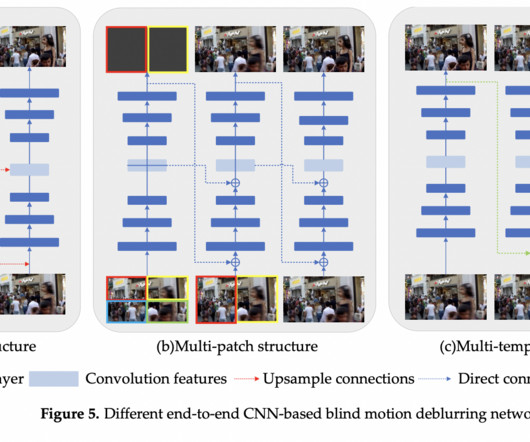
Computervision tasks like autonomous driving, object segmentation, and scene analysis can negatively impact this effect, which blurs or stretches the image’s object contours, diminishing their clarity and detail. To create efficient methods for removing motion blur, it is essential to understand where it comes from.
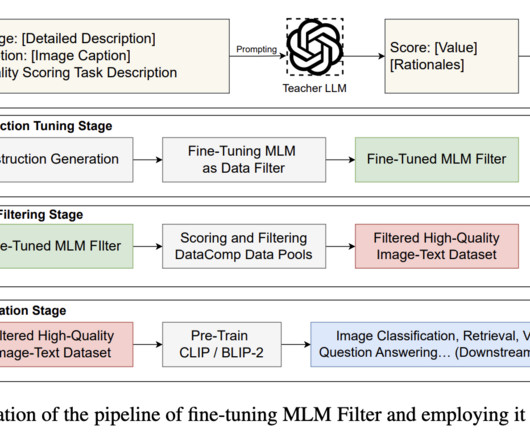
Their solution focuses on filtering image-text data, a novel approach that introduces a nuanced scoring system for dataquality evaluation, offering a more refined assessment than its predecessors. The research introduces a comprehensive scoring system that evaluates the quality of image-text pairs across four distinct metrics.
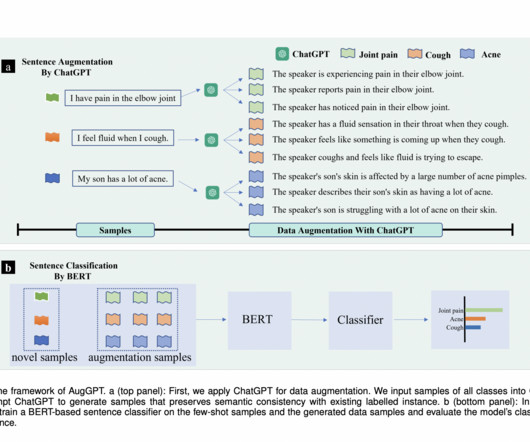
Recent NLP research has focused on improving few-shot learning (FSL) methods in response to data insufficiency challenges. While these methods enhance model capabilities through architectural designs and pre-trained language models, dataquality and quantity limitations persist. Check out the Paper.
These technologies have revolutionized computervision, robotics, and natural language processing and played a pivotal role in the autonomous driving revolution. Over the past decade, advancements in deep learning and artificial intelligence have driven significant strides in self-driving vehicle technology.
Examples include financial systems processing transaction data streams, recommendation engines processing user activity data, and computervision models processing video frames.
Among AI technologies, search engines, speech & voice recognition, and computervision lead in deployment across industries, illustrating the diverse applications of AI in enhancing user interaction, processing information, and interpreting visual data.
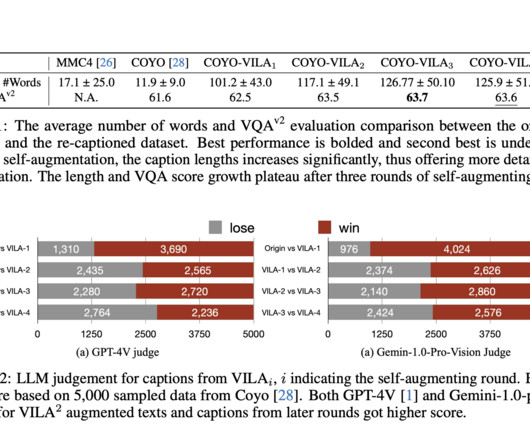
This approach progressively enhances dataquality by improving visual semantics and reducing hallucinations, directly boosting VLM performance. Through iterative rounds, VILA 2 significantly increases caption length and quality, with improvements observed primarily after round-1. Check out the Paper.
In the domain of Artificial Intelligence (AI) , workflows are essential, connecting various tasks from initial data preprocessing to the final stages of model deployment. This foundational step requires clean and well-structured data to facilitate accurate model training. Next, efficient model training is critical.
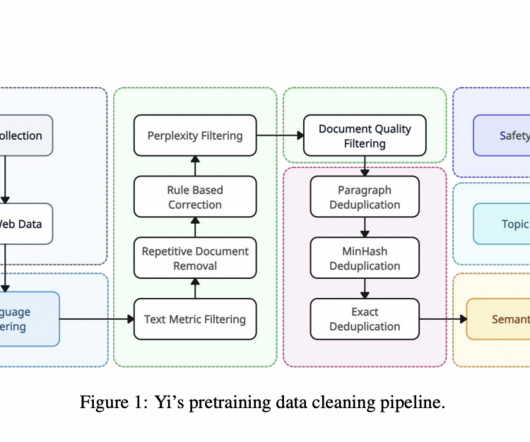
These are based on an evolved transformer architecture that’s been fine-tuned with a keen eye on dataquality, a factor that significantly boosts performance across various benchmarks. This practicality makes the Yi model series a powerful tool for various applications, from natural language processing to computervision tasks.
Can you discuss how the computer app uses AI to assess users posture using the webcam? The computer app we've developed at Zen utilizes AI algorithms, mainly computervision and complex mathematical models, to assess users' posture in real-time through their computer's webcam.
Dataquality control: Robust dataset labeling and annotation tools incorporate quality control mechanisms such as inter-annotator agreement analysis, review workflows, and data validation checks to ensure the accuracy and reliability of annotations. Data monitoring tools help monitor the quality of the data.
The following sections further explain the main components of the solution: ETL pipelines to transform the log data, agentic RAG implementation, and the chat application. Creating ETL pipelines to transform log data Preparing your data to provide quality results is the first step in an AI project.
Here are just a few: Dataquality. In production, machine learning models may encounter data that differs from the training data, such as missing values, noise, or outliers. Ensuring dataquality and consistency is critical to maintaining model robustness. Concept drift.
collaborated with the AWS Machine Learning Solutions Lab (MLSL) to use computervision to automate the inspection of wooden utility poles and help prevent power outages, property damage and even injuries. We also employed various data processing techniques that helped improve the performance. Dr. Nkechinyere N.
Furthermore, the convergence of natural language processing and computervision models has given rise to VLMs, or Vision Language Models, which combine linguistic and vision models to achieve cross-modal comprehension and reasoning capabilities.
Dataquality over quantity: Models trained on 2 billion high-quality samples outperform those trained on larger datasets, emphasizing the importance of data curation. UniBench also highlights the importance of dataquality over quantity and the effectiveness of tailored learning objectives.
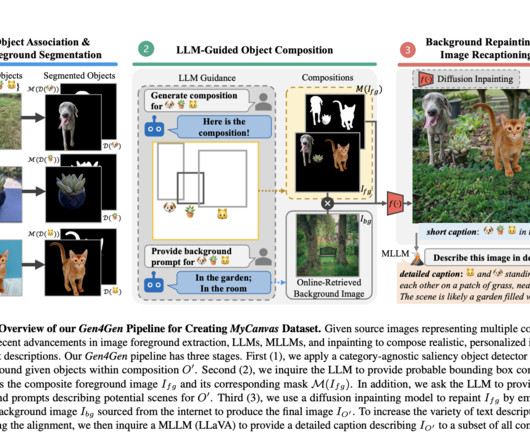
The findings have shown that the quality of multi-concept personalized image production can be significantly improved by improving dataquality and utilizing efficient prompting tactics. Future researchers can use this baseline as a starting point to assess the MyCanvas dataset.
Some of our most popular in-person sessions were: MLOps: Monitoring and Managing Drift: Oliver Zeigermann | Machine Learning Architect ODSC Keynote: Human-Centered AI: Peter Norvig, PhD | Engineering Director, Education Fellow | Google, Stanford Institute for Human-Centered Artificial Intelligence (HAI) The Cost of AI Compute and Why AI Clouds Will (..)
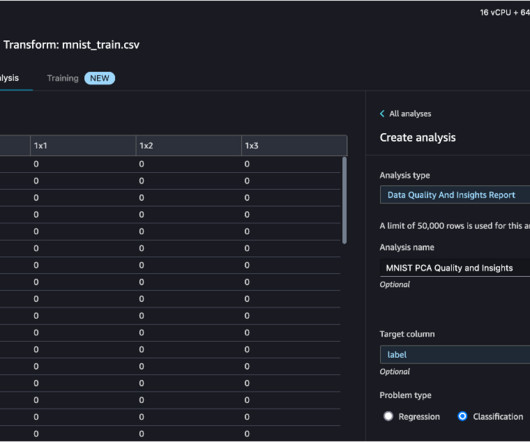
Solution overview In this post, we show how you can use the dimensionality reduction transform in Data Wrangler on the MNIST dataset to reduce the number of features by 85% and still achieve similar or better accuracy than the original dataset. Refer to Get Insights On Data and DataQuality for more information.
Scalability : It can handle large datasets efficiently, as the model can be trained on existing data without the need for continuous human intervention. Disadvantages DataQuality: Passive learning relies heavily on the quality and diversity of the pre-collected data.
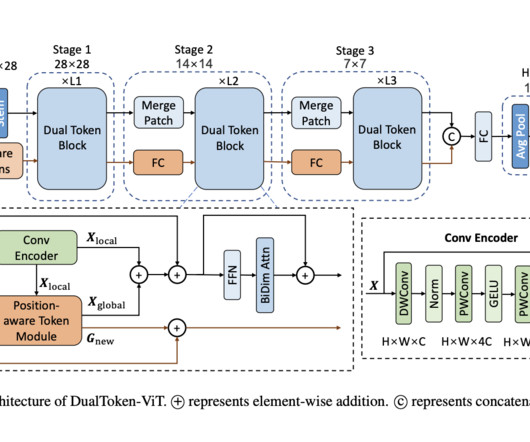
This can lower the computational cost of self-attention in global information broadcasting. Additionally, they employ position-aware global tokens at every level to improve global dataquality.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content