This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This advancement has spurred the commercial use of generative AI in natural language processing (NLP) and computervision, enabling automated and intelligent dataextraction. Businesses can now easily convert unstructured data into valuable insights, marking a significant leap forward in technology integration.
Using AI algorithms and machine learning models, businesses can sift through big data, extract valuable insights, and tailor. makeuseof.com Computervision's next breakthrough Computervision can do more than reduce costs and improve quality.
With Amazon Bedrock Data Automation, this entire process is now simplified into a single unified API call. It also offers flexibility in dataextraction by supporting both explicit and implicit extractions. Additionally, human-in-the-loop verification may be required for low-threshold outputs.
ComputerVision and Deep Learning for Oil and Gas ComputerVision and Deep Learning for Transportation ComputerVision and Deep Learning for Logistics ComputerVision and Deep Learning for Healthcare (this tutorial) ComputerVision and Deep Learning for Education To learn about ComputerVision and Deep Learning for Healthcare, just keep reading.
A predefined JSON schema can be provided to the Rhubarb API, which makes sure the LLM generates data in that specific format. Internally, Rhubarb also does re-prompting and introspection to rephrase the user prompt in order to increase the chances of successful dataextraction by the model.
The convolution layer applies filters (kernels) over input data, extracting essential features such as edges, textures, or shapes. Pooling layers simplify data by down-sampling feature maps, ensuring the network focuses on the most prominent patterns.
IDP on quarterly reports A leading pharmaceutical data provider empowered their analysts by using Agent Creator and AutoIDP to automate dataextraction on pharmaceutical drugs. He focuses on Deep learning including NLP and ComputerVision domains. The next paragraphs illustrate just a few.
These tools offer a variety of choices to effectively extract, process, and analyze data from various web sources. Scrapy A powerful, open-source Python framework called Scrapy was created for highly effective web scraping and dataextraction.
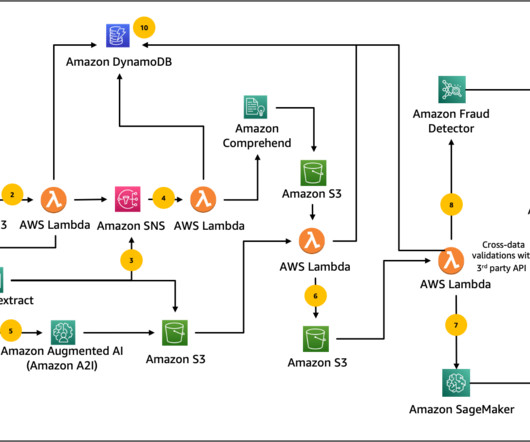
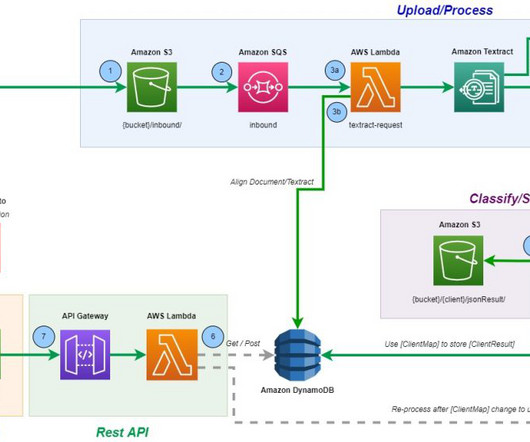
In Part 2, we demonstrate how to train and host a computervision model for tampering detection and localization on Amazon SageMaker. The document pages are then automatically routed to Amazon Textract text processing operations for accurate dataextraction and analysis.
The structure of the dataset allows for the seamless integration of different types of data, making it a valuable resource for training or fine-tuning medical language, computervision, or multi-modal models.
You can use state-of-the-art model architecturessuch as language models, computervision models, and morewithout having to build them from scratch. These pre-trained models serve as powerful starting points that can be deeply customized to address specific use cases.
Intelligent document processing (IDP) applies AI/ML techniques to automate dataextraction from documents. You can apply human-in-the-loop to all types of deep learning AI projects, including natural language processing (NLP), computervision, and transcription.
Sounds crazy, but Wei Shao (Data Scientist at Hortifrut) and Martin Stein (Chief Product Officer at G5) both praised the solution. They have expertise in image processing, including deep learning for computervision and commercial implementation of synthetic imaging. Numlabs Clutch rating: 4.9/5 AI Superior Clutch rating: 5.0/5
provides the world’s only end-to-end computervision platform Viso Suite. The solution enables leading companies to build, deploy and scale real-world computervision systems. Examples of OCR are text extraction tools, PDF to.txt converters, and Google’s image search function. Get a demo here.
It is crucial to pursue a metrics-driven strategy that emphasizes the quality of dataextraction at the field level, particularly for high-impact fields. Harness a flywheel approach, wherein continuous data feedback is utilized to routinely orchestrate and evaluate enhancements to your models and processes.
For these tasks, we use the Recall-Oriented Understudy for Gisting Evaluation (ROUGE) metric to evaluate the performance of an LLM on question-answering tasks with respect to a set of ground truth data. Extractive tasks refer to activities where the model identifies and extracts specific portions of the input text to construct a response.
Importing Libraries Before performing any operations on the image, we’ll import the following packages: i) CV2 (OpenCV): An open source library written in C++ which is used in computervision applications. DataExtraction Once we’ve preprocessed the data, our focus shifts to extracting text from the image.
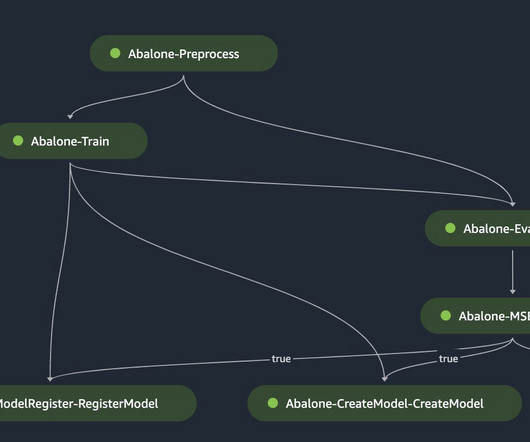
We use a typical pipeline flow, which includes steps such as dataextraction, training, evaluation, model registration and deployment, as a reference to demonstrate the advantages of Selective Execution. SageMaker Pipelines allows you to define runtime parameters for your pipeline run using pipeline parameters.
provides Viso Suite , the world’s only end-to-end ComputerVision Platform. The technology enables global organizations to develop, deploy, and scale all computervision applications in one place. They utilized machine learning algorithms for dataextraction, pattern classification, and prescription prediction.
Careful optimization is needed in the dataextraction and preprocessing stage. He helps AWS customers identify and build ML solutions to address their business challenges in areas such as logistics, personalization and recommendations, computervision, fraud prevention, forecasting and supply chain optimization.
Foundations AWS AI services provide ready-made intelligence, such as automated dataextraction and analysis, using Amazon Textract, Amazon Comprehend, and Amazon Augmented AI (Amazon A2I), for your IDP workflows. His focus is natural language processing and computervision.
We will specifically focus on the two most common uses: template-based normalized key-value entity extractions and document Q&A, with large language models. Template-based normalized extractions In almost all IDP use cases, the dataextracted is eventually sent to a downstream system for further processing or analytics.
More recently, contrastive learning gained popularity in self-supervised representation learning in computervision and speech ( van den Oord, 2018 ; Hénaff et al., This might indicate why unsupervised contrastive learning has not been successful with large pre-trained models in NLP where data augmentation is less common.
By enabling teams to monitor embeddings of unstructured data for computervision and natural language processing models, Arize also helps teams proactively identify what data to label next and troubleshoot issues in production. Users can sign up for a free account at Arize.com.
Techniques such as data augmentation and transfer learning are employed to enhance the model’s ability to generalize across different cases and conditions. These models dive deep into the nuances of pathology data, extracting critical insights that fuel the development of predictive models.
This offering is optimized for large-scale deep learning workloads to accelerate breakthroughs in natural language processing, computervision and more. The Blackwell-based VM series complements previously announced Azure AI clusters with ND H200 V5 VMs , which provide increased high-bandwidth memory for improved AI inferencing.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content