This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
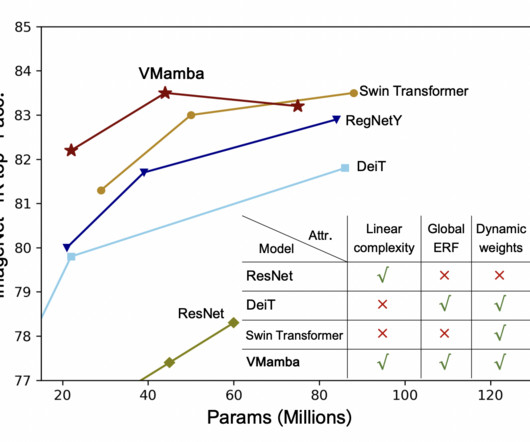
There are two major challenges in visual representation learning: the computational inefficiency of Vision Transformers (ViTs) and the limited capacity of ConvolutionalNeuralNetworks (CNNs) to capture global contextual information. A team of researchers at UCAS, in collaboration with Huawei Inc.
To overcome the challenge presented by single modality models & algorithms, Meta AI released the data2vec, an algorithm that uses the same learning methodology for either computervision , NLP or speech. For computervision, the model practices block-wise marking strategy.
ComputerVision (CV): Using libraries such as OpenCV , agents can detect edges, shapes, or motion within a scene, enabling higher-level tasks like object recognition or scene segmentation. Natural Language Processing (NLP): Text data and voice inputs are transformed into tokens using tools like spaCy.
In the field of computervision, supervised learning and unsupervised learning are two of the most important concepts. In this guide, we will explore the differences and when to use supervised or unsupervised learning for computervision tasks. We will also discuss which approach is best for specific applications.
Its AI courses offer hands-on training for real-world applications, enabling learners to effectively use Intel’s portfolio in deep learning, computervision, and more. By the end, students will understand network construction, kernels, and expanding networks using transfer learning.
Project Structure Accelerating ConvolutionalNeuralNetworks Parsing Command Line Arguments and Running a Model Evaluating ConvolutionalNeuralNetworks Accelerating Vision Transformers Evaluating Vision Transformers Accelerating BERT Evaluating BERT Miscellaneous Summary Citation Information What’s New in PyTorch 2.0?
Applications of Deep Learning Deep Learning has found applications across numerous domains: ComputerVision : Used in image classification, object detection, and facial recognition. Cat vs. Dog Classification This project involves building a ConvolutionalNeuralNetwork (CNN) to classify images as either cats or dogs.
Summary: Deep Learning models revolutionise data processing, solving complex image recognition, NLP, and analytics tasks. These models mimic the human brain’s neuralnetworks, making them highly effective for image recognition, natural language processing, and predictive analytics.
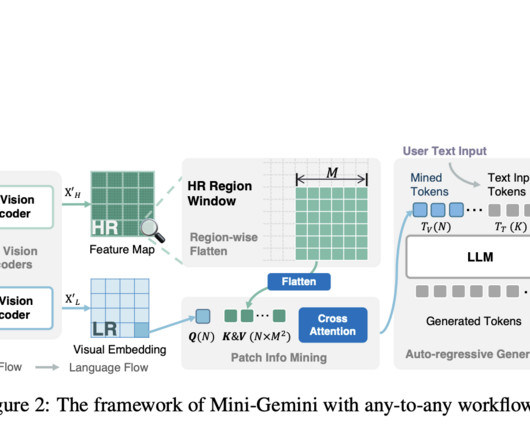
Vision Language Models (VLMs) emerge as a result of a unique integration of ComputerVision (CV) and Natural Language Processing (NLP). These innovations enable Mini-Gemini to process high-resolution images effectively and generate context-rich visual and textual content, setting it apart from existing models.
Application Differences : NeuralNetworks for simple tasks, Deep Learning for complex ones. AI Capabilities : Enables image recognition, NLP, and predictive analytics. NeuralNetworks: The Foundation A neuralnetwork is a computing system inspired by the biological neuralnetworks that constitute animal brains.
Computervision, the field dedicated to enabling machines to perceive and understand visual data, has witnessed a monumental shift in recent years with the advent of deep learning. Photo by charlesdeluvio on Unsplash Welcome to a journey through the advancements and applications of deep learning in computervision.
Deep learning architectures have revolutionized the field of artificial intelligence, offering innovative solutions for complex problems across various domains, including computervision, natural language processing, speech recognition, and generative models. It was introduced in the paper “Attention is All You Need” by Vaswani et al.
adults use only work when they can turn audio data into words, and then apply natural language processing (NLP) to understand it. Computervision systems in dashboard cameras can use video anomaly detection to automatically save clips of unsafe behaviors or crashes. The voice assistants that 62% of U.S.
Throughout the course, you’ll progress from basic programming skills to solving complex computervision problems, guided by videos, readings, quizzes, and programming assignments. It also delves into NLP with tokenization, embeddings, and RNNs and concludes with deploying models using TensorFlow Lite.
AI emotion recognition is a very active current field of computervision research that involves facial emotion detection and the automatic assessment of sentiment from visual data and text analysis. provides the end-to-end computervision platform Viso Suite. About us: Viso.ai
As many areas of artificial intelligence (AI) have experienced exponential growth, computervision is no exception. According to the data from the recruiting platforms – job listings that look for artificial intelligence or computervision specialists doubled from 2021 to 2023.
In image recognition, researchers and developers constantly seek innovative approaches to enhance the accuracy and efficiency of computervision systems. However, recent advancements have paved the way for exploring alternative architectures, prompting the integration of Transformer-based models into visual data analysis.
Well, image segmentation in computervision is a bit like playing a high-tech version of Tetris! So get ready to flex your Tetris skills and dive into the fascinating world of image segmentation in computervision! Have you ever played Tetris?
Understanding Vision Transformers (ViTs) And what I learned while implementing them! Transformers have revolutionized natural language processing (NLP), powering models like GPT and BERT. But recently, theyve also been making waves in computervision.
Put simply, if we double the input size, the computational needs can increase fourfold. AI models like neuralnetworks , used in applications like Natural Language Processing (NLP) and computervision , are notorious for their high computational demands.
Pixabay: by Activedia Image captioning combines natural language processing and computervision to generate image textual descriptions automatically. Image captioning integrates computervision, which interprets visual information, and NLP, which produces human language.
Arguably, one of the most pivotal breakthroughs is the application of ConvolutionalNeuralNetworks (CNNs) to financial processes. This drastically enhanced the capabilities of computervision systems to recognize patterns far beyond the capability of humans. Applications of ComputerVision in Finance No.
Subscribe now #3 Natural Language Processing Course in Python This is a short yet useful 2-hour NLP course for anyone interested in the field of Natural Language Processing. NLP is a branch of artificial intelligence that allows machines to understand human language.
Although optimizers like Adam perform parameter updates iteratively to minimize errors gradually, the sheer size of models, especially in tasks like natural language processing (NLP) and computervision, leads to long training cycles. reduction in training time.
GCNs have been successfully applied to many domains, including computervision and social network analysis. In recent years, researchers have also explored using GCNs for natural language processing (NLP) tasks, such as text classification , sentiment analysis , and entity recognition.
The concept of image segmentation has formed the basis of various modern ComputerVision (CV) applications. Segmentation models help computers understand the various elements and objects in a visual reference frame, such as an image or a video. provides a robust end-to-end no-code computervision solution – Viso Suite.
The advancements in large language models have significantly accelerated the development of natural language processing , or NLP. For the high-resolution flows, the Mini-Gemini framework adopts the CNN or ConvolutionNeuralNetworks based encoder for adaptive and efficient high resolution image processing.
This satisfies the strong MME demand for deep neuralnetwork (DNN) models that benefit from accelerated compute with GPUs. These include computervision (CV), natural language processing (NLP), and generative AI models. 2xlarge, ml.g5.2xlarge, and ml.p3.2xlarge.
Vision Transformer (ViT) have recently emerged as a competitive alternative to ConvolutionalNeuralNetworks (CNNs) that are currently state-of-the-art in different image recognition computervision tasks. Transformer models have become the de-facto status quo in Natural Language Processing (NLP).
Object detection systems typically use frameworks like ConvolutionalNeuralNetworks (CNNs) and Region-based CNNs (R-CNNs). Concept of ConvolutionalNeuralNetworks (CNN) However, in prompt object detection systems, users dynamically direct the model with many tasks it may not have encountered before.
The selection of areas and methods is heavily influenced by my own interests; the selected topics are biased towards representation and transfer learning and towards natural language processing (NLP). This is less of a problem in NLP where unsupervised pre-training involves classification over thousands of word types.
Over the past decade, the field of computervision has experienced monumental artificial intelligence (AI) breakthroughs. This blog will introduce you to the computervision visionaries behind these achievements. Viso Suite is the end-to-End, No-Code ComputerVision Solution.
Value of AI models for businesses The most popular AI models AI models in computervision applications – Viso Suite About us: We provide the platform Viso Suite to collect data and train, deploy, and scale AI models on powerful infrastructure. In computervision, this process is called image annotation.
Most NLP problems can be reduced to machine learning problems that take one or more texts as input. However, most NLP problems require understanding of longer spans of text, not just individual words. This has always been a huge weakness of NLP models. 2016) model and a convolutionalneuralnetwork (CNN).
Catastrophic forgetting problems have become more relevant for spaCy users lately, because spaCy v2’s part-of-speech, named entity, syntactic dependency and sentence segmentation models all share an input representation, produced by a convolutionalneuralnetwork.
Here are a few examples across various domains: Natural Language Processing (NLP) : Predictive NLP models can categorize text into predefined classes (e.g., spam vs. not spam), while generative NLP models can create new text based on a given prompt (e.g., a social media post or product description).
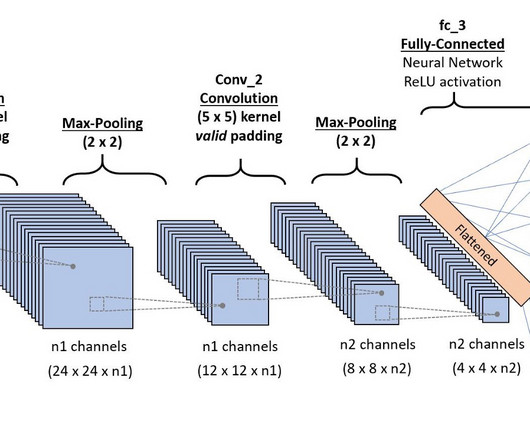
Example of a deep learning visualization: small convolutionalneuralnetwork CNN, notice how the thickness of the colorful lines indicates the weight of the neural pathways | Source How is deep learning visualization different from traditional ML visualization? Let’s take a computervision model as an example.
Applications in ComputerVision Models like ResNET, VGG, Image Captioning, etc. Applications in Multimodal Learning Models like CLIP Emerging Trends and Future Advancement in Foundation Model Research About Us: Viso Suite is the end-to-end computervision infrastructure.
The Segment Anything Model (SAM), a recent innovation by Meta’s FAIR (Fundamental AI Research) lab, represents a pivotal shift in computervision. SAM performs segmentation, a computervision task , to meticulously dissect visual data into meaningful segments, enabling precise analysis and innovations across industries.
Architecture and training process How CLIP resolves key challenges in computervision Practical applications Challenges and limitations while implementing CLIP Future advancements How Does CLIP Work? It typically uses a convolutionalneuralnetwork (CNN) architecture, like ResNet , for extracting image features.
Today, DNNs power cutting-edge technologies like transformers, revolutionizing fields like natural language processing and computervision. How Deep NeuralNetworks DNNs Work DNNs function by learning from data to identify patterns and make predictions. pixel values of an image, numerical data).
The beginning of 2023 brings with it a shift in focus for Heartbeat and we’re excited to dive deeper into Comet related tutorials, more deep learning content, and some NLP and computervision projects. Until 2020, the process of measuring a convolutionalneuralnetwork was never well understood.
With the advancement of technology, machine learning, and computervision techniques can be used to develop automated solutions for leaf disease detection. The model uses a convolutionalneuralnetwork (CNN) to extract features from the images and classify them as healthy or diseased. BECOME a WRITER at MLearning.ai
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content