This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Computervision is rapidly transforming industries by enabling machines to interpret and make decisions based on visual data. Learning computervision is essential as it equips you with the skills to develop innovative solutions in areas like automation, robotics, and AI-driven analytics, driving the future of technology.
In the past decade, Artificial Intelligence (AI) and Machine Learning (ML) have seen tremendous progress. Modern AI and ML models can seamlessly and accurately recognize objects in images or video files. The SEER model by Facebook AI aims at maximizing the capabilities of self-supervised learning in the field of computervision.
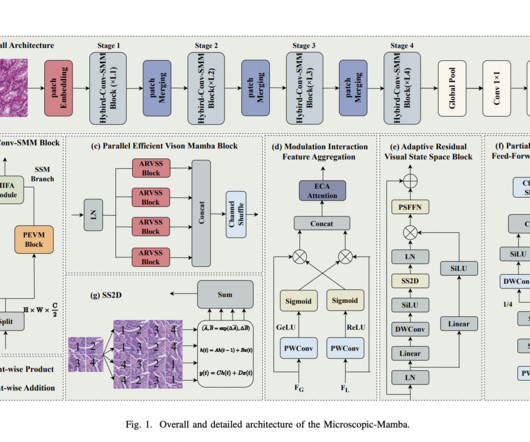
There are two major challenges in visual representation learning: the computational inefficiency of Vision Transformers (ViTs) and the limited capacity of ConvolutionalNeuralNetworks (CNNs) to capture global contextual information. A team of researchers at UCAS, in collaboration with Huawei Inc.
Deep learning models like ConvolutionalNeuralNetworks (CNNs) and Vision Transformers achieved great success in many visual tasks, such as image classification, object detection, and semantic segmentation. Join our Telegram Channel and LinkedIn Gr oup. If you like our work, you will love our newsletter.
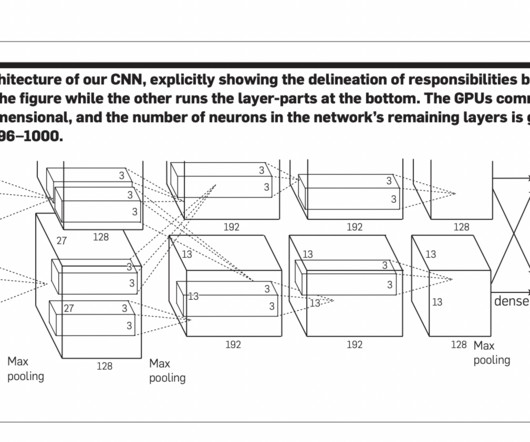
Deep convolutionalneuralnetworks (DCNNs) have been a game-changer for several computervision tasks. Network depth and convolution are the two primary components of a DCNN that determine its expressive power. Check out the Paper and Github. If you like our work, you will love our newsletter.
There has been a dramatic increase in the complexity of the computervision model landscape. Many models are now at your fingertips, from the first ConvNets to the latest Vision Transformers. Join our 36k+ ML SubReddit , 41k+ Facebook Community, Discord Channel , and LinkedIn Gr oup.
To address this, various feature extraction methods have emerged: point-based networks and sparse convolutionalneuralnetworks CNNs ConvolutionalNeuralNetworks. Understanding the underlying reasons for this performance gap is crucial for advancing the capabilities of sparse CNNs.
This model incorporates a static ConvolutionalNeuralNetwork (CNN) branch and utilizes a variational attention fusion module to enhance segmentation performance. Hausdorff Distance Using ConvolutionalNeuralNetwork CNN and ViT Integration appeared first on MarkTechPost. Dice Score and 27.10
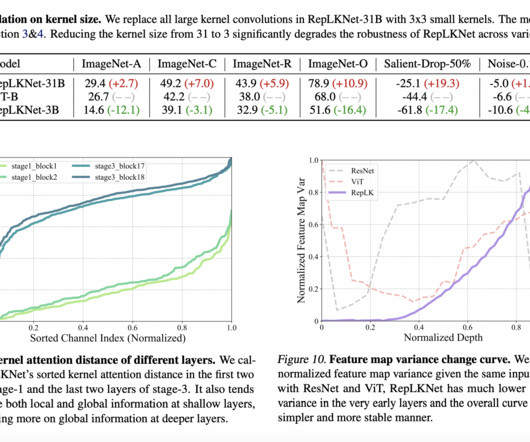
Don’t Forget to join our 46k+ ML SubReddit The post Exploring Robustness: Large Kernel ConvNets in Comparison to ConvolutionalNeuralNetwork CNNs and Vision Transformers ViTs appeared first on MarkTechPost. Join our Telegram Channel and LinkedIn Gr oup. If you like our work, you will love our newsletter.
Traditional machine learning methods, such as convolutionalneuralnetworks (CNNs), have been employed for this task, but they come with limitations. Moreover, the scale of the data generated through microscopic imaging makes manual analysis impractical in many scenarios. If you like our work, you will love our newsletter.
This article covers an extensive list of novel, valuable computervision applications across all industries. Find the best computervision projects, computervision ideas, and high-value use cases in the market right now. provides Viso Suite , the world’s only end-to-end ComputerVision Platform.
Image reconstruction is an AI-powered process central to computervision. In this article, we’ll provide a deep dive into using computervision for image reconstruction. About Us: Viso Suite is the end-to-end computervision platform helping enterprises solve challenges across industry lines.
Stereo depth estimation plays a crucial role in computervision by allowing machines to infer depth from two images. These methods utilize 3D convolutionalneuralnetworks (CNNs) for cost filtering but struggle with generalization beyond their training data. Check out the Paper and GitHub Page.
Computervision is rapidly transforming industries by enabling machines to interpret and make decisions based on visual data. Learning computervision is essential as it equips you with the skills to develop innovative solutions in areas like automation, robotics, and AI-driven analytics, driving the future of technology.
To overcome this business challenge, ICL decided to develop in-house capabilities to use machine learning (ML) for computervision (CV) to automatically monitor their mining machines. As a traditional mining company, the availability of internal resources with data science, CV, or ML skills was limited.
The goal of computervision research is to teach computers to recognize objects and scenes in their surroundings. In this article, I would like to take a look at the current challenges in the field of robotics and discuss the relevance and applications of computervision in this area.
To overcome the challenge presented by single modality models & algorithms, Meta AI released the data2vec, an algorithm that uses the same learning methodology for either computervision , NLP or speech. For computervision, the model practices block-wise marking strategy. What is the Data2Vec Algorithm?
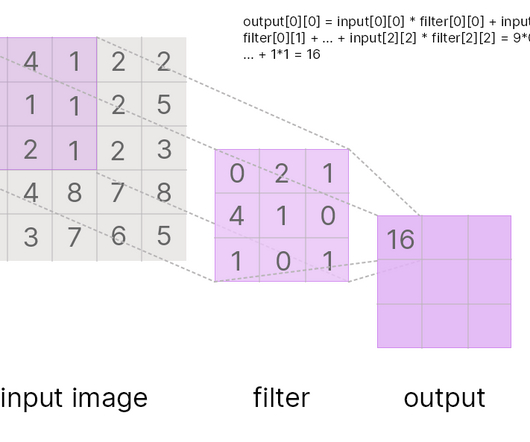
In this guide, we’ll talk about ConvolutionalNeuralNetworks, how to train a CNN, what applications CNNs can be used for, and best practices for using CNNs. What Are ConvolutionalNeuralNetworks CNN? CNNs learn geometric properties on different scales by applying convolutional filters to input data.
With these advancements, it’s natural to wonder: Are we approaching the end of traditional machine learning (ML)? The two main types of traditional ML algorithms are supervised and unsupervised. Data Preprocessing and Feature Engineering: Traditional ML requires extensive preprocessing to transform datasets as per model requirements.
In the field of computervision, supervised learning and unsupervised learning are two of the most important concepts. In this guide, we will explore the differences and when to use supervised or unsupervised learning for computervision tasks. We will also discuss which approach is best for specific applications.
The success of this model reflects a broader shift in computervision towards machine learning approaches that leverage large datasets and computational power. Previously, researchers doubted that neuralnetworks could solve complex visual tasks without hand-designed systems. by the next-best model.
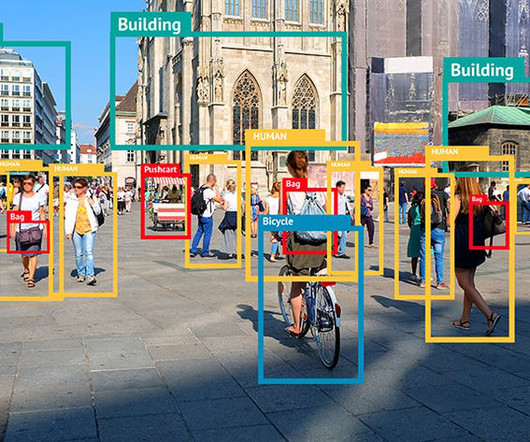
According to IBM, Object detection is a computervision task that looks for items in digital images. In this sense, it is an example of artificial intelligence that is, teaching computers to see in the same way as people do, namely by identifying and categorizing objects based on semantic categories. What is Object Detection?
Contrastingly, agentic systems incorporate machine learning (ML) and artificial intelligence (AI) methodologies that allow them to adapt, learn from experience, and navigate uncertain environments. Image Embeddings: Convolutionalneuralnetworks (CNNs) or vision transformers can transform images into dense vector embedding.
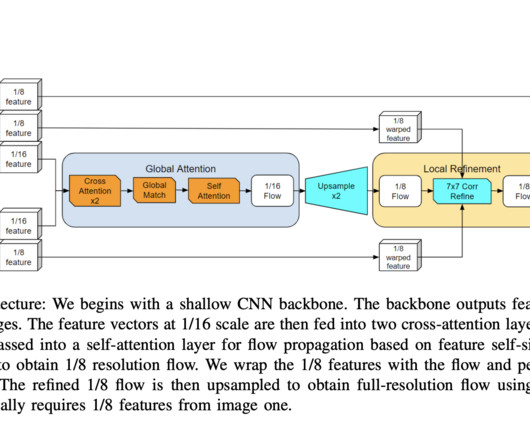
Real-time, high-accuracy optical flow estimation is critical for analyzing dynamic scenes in computervision. Traditional methodologies, while foundational, have often stumbled upon the computational versus accuracy problem, especially when executed on edge devices. Check out the Paper and Github.
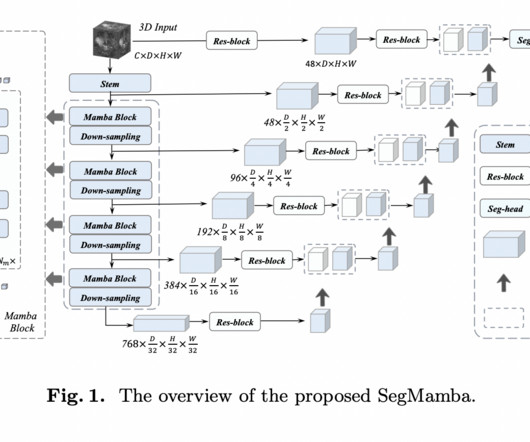
Traditional convolutionalneuralnetworks (CNNs) often struggle to capture global information from high-resolution 3D medical images. One proposed solution is the utilization of depth-wise convolution with larger kernel sizes to capture a wider range of features. Check out the Paper and Github.
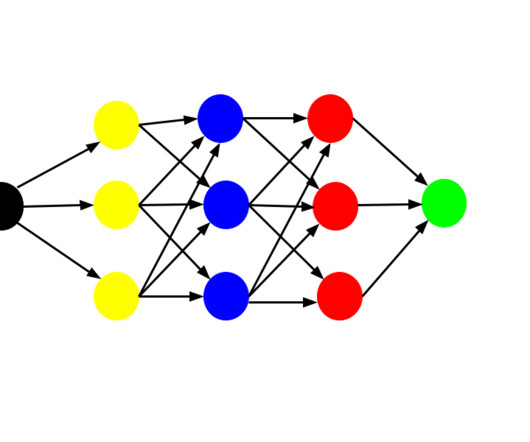
Source Anatomy of a CNN Let’s outline the architectural anatomy of a convolutionalneuralnetwork: Convolutional layers Activation layers Pooling layers Dense layers Andrew Jones of Data Science Infinity Convolutional Layer Instead of flattening the input at the input layer, you start by applying a filter.
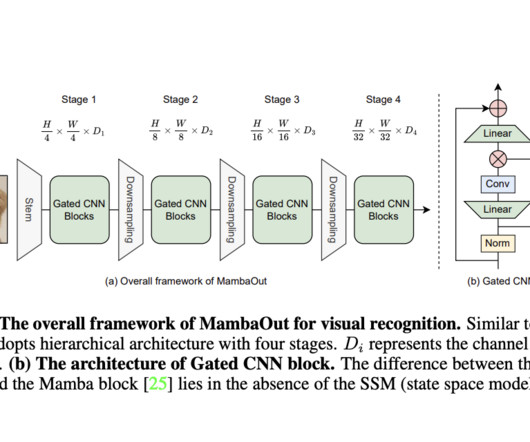
Computervision enables machines to interpret & understand visual information from the world. Innovations in this area have been propelled by developing advanced neuralnetwork architectures, particularly ConvolutionalNeuralNetworks (CNNs) and, more recently, Transformers.
In the first part of this three-part series, we presented a solution that demonstrates how you can automate detecting document tampering and fraud at scale using AWS AI and machine learning (ML) services for a mortgage underwriting use case. We provide guidance on building, training, and deploying deep learning networks on Amazon SageMaker.
This article covers everything you need to know about image classification – the computervision task of identifying what an image represents. Today, the use of convolutionalneuralnetworks (CNN) is the state-of-the-art method for image classification. It’s a powerful all-in-one solution for AI vision.
If you want a gentle introduction to machine learning for computervision, you’re in the right spot. Here at PyImageSearch we’ve been helping people just like you master deep learning for computervision. Also, you might want to check out our computervision for deep learning program before you go.
In recent years, computervision has made significant strides by leveraging advanced neuralnetwork architectures to tackle complex tasks such as image classification, object detection, and semantic segmentation. Also, don’t forget to follow us on Twitter. If you like our work, you will love our newsletter.
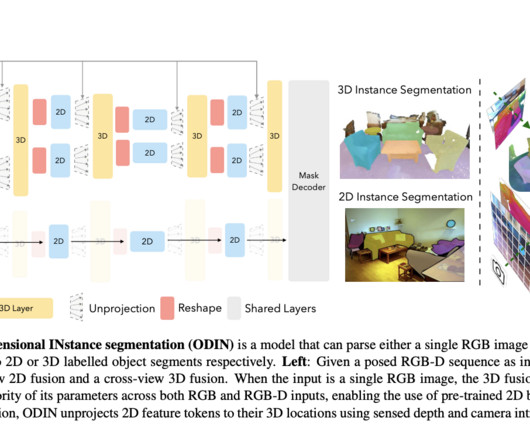
Models tailored for 2D images, such as those based on convolutionalneuralnetworks, need to be revised for interpreting complex 3D environments. ODIN’s approach marks a significant advancement in computervision, offering new possibilities for applications requiring detailed environmental understanding.
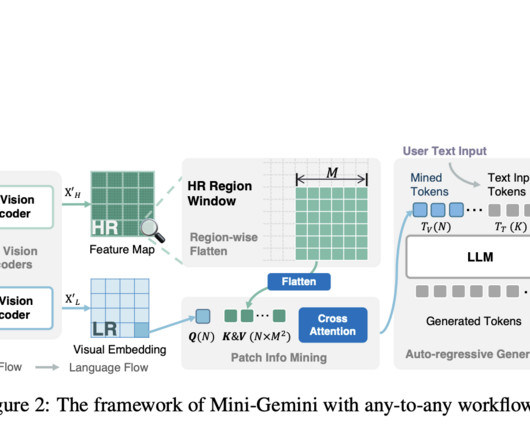
Vision Language Models (VLMs) emerge as a result of a unique integration of ComputerVision (CV) and Natural Language Processing (NLP). These innovations enable Mini-Gemini to process high-resolution images effectively and generate context-rich visual and textual content, setting it apart from existing models.
Image-to-image translation (I2I) is an interesting field within computervision and machine learning that holds the power to transform visual content from one domain into another seamlessly. It leverages the capabilities of deep learning models, such as Generative Adversarial Networks (GANs) and ConvolutionalNeuralNetworks (CNNs).
In the past few years, Artificial Intelligence (AI) and Machine Learning (ML) have witnessed a meteoric rise in popularity and applications, not only in the industry but also in academia. It’s the major reason why its difficult to build a standard ML architecture for IoT networks.
This article will provide an introduction to object detection and provide an overview of the state-of-the-art computervision object detection algorithms. Object detection is a key field in artificial intelligence, allowing computer systems to “see” their environments by detecting objects in visual images or videos.
Observations indicate diminishing returns with increased model depth, mirroring challenges in deep convolutionalneuralnetworks for computervision. Also, don’t forget to follow us on Twitter. Join our Telegram Channel , Discord Channel , and LinkedIn Gr oup.
As many areas of artificial intelligence (AI) have experienced exponential growth, computervision is no exception. According to the data from the recruiting platforms – job listings that look for artificial intelligence or computervision specialists doubled from 2021 to 2023.
Recent advancements in deep neuralnetworks have enabled new approaches to address anatomical segmentation. For instance, state-of-the-art performance in the anatomical segmentation of biomedical images has been attained by deep convolutionalneuralnetworks (CNNs). Check out the Paper and Github.
Researchers in computervision and robotics consistently strive to improve autonomous systems’ perception capabilities. Existing research includes convolutionalneuralnetworks (CNNs) and transformer-based object detection and segmentation architectures. Also, don’t forget to follow us on Twitter.
This image representation comes under a broad category of ComputerVision and ConvolutionalNeuralNetworks. Research scientists find it very similar to ConvolutionalNeuralNetworks. But formatting an image through text is challenging as there was a severe loss and less accuracy.
Well, image segmentation in computervision is a bit like playing a high-tech version of Tetris! So get ready to flex your Tetris skills and dive into the fascinating world of image segmentation in computervision! Have you ever played Tetris?
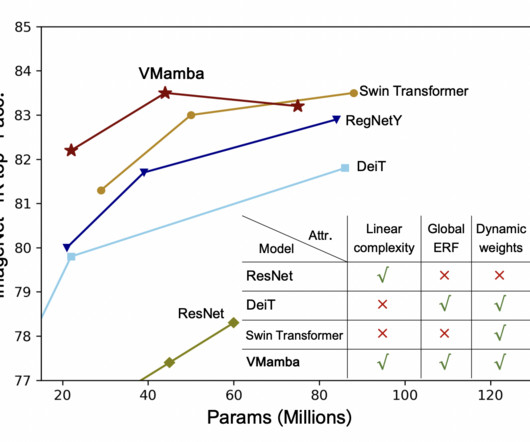
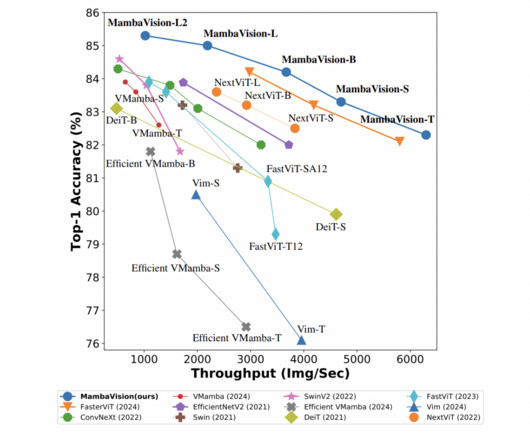
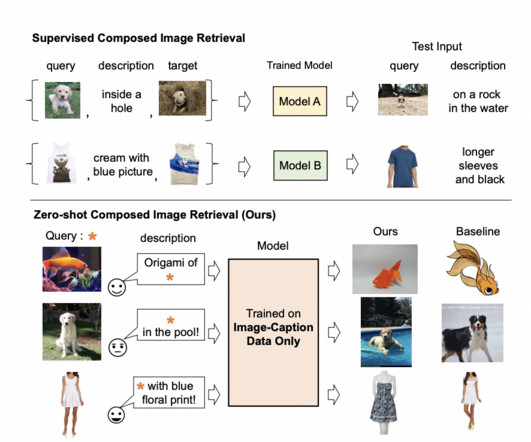
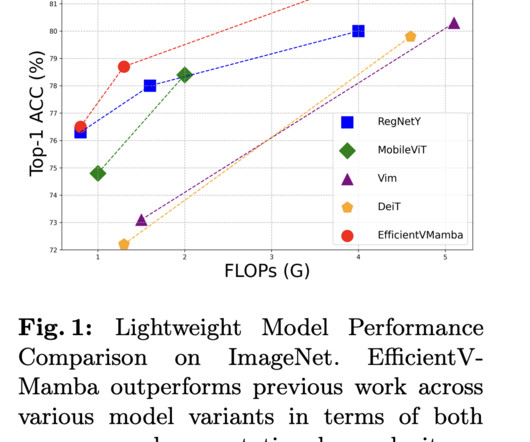
In the evolving landscape of computervision, the quest for models that adeptly navigate the tightrope between high accuracy and low computational cost has led to significant strides. A study by researchers from The University of Sydney introduces EfficientVMamba, a model that redefines efficiency in computervision tasks.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content