This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
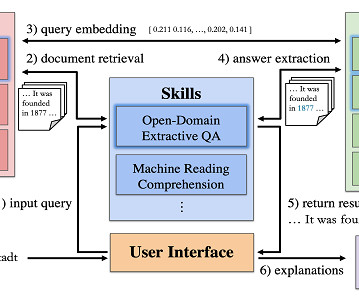
The ReproHum project (where I am working with Anya Belz (PI) and Craig Thomson (RF) as well as many partner labs) is looking at the reproducibility of human evaluations in NLP. So User interface problems : Very few NLP papers give enough information about UIs to enable reviewers to check these for problems. Especially
Learn about the concept of information extraction We will apply. The post How Search Engines like Google Retrieve Results: Introduction to Information Extraction using Python and spaCy appeared first on Analytics Vidhya. Overview How do search engines like Google understand our queries and provide relevant results?
Prompts are changed by introducing spelling errors, replacing synonyms, concatenating irrelevant information or translating from a different language. link] The paper proposes query rewriting as the solution to the problem of LLMs being overly affected by irrelevant information in the prompts. Character-level attacks rank second.
if this statement sounds familiar, you are not foreign to the field of computationallinguistics and conversational AI. These technologies have revolutionized the way we interact with computers — enabling us to access information, make purchases, and carry out an array of tasks through simple voice commands or text messages.
Are you looking to study or work in the field of NLP? For this series, NLP People will be taking a closer look at the NLP education & development landscape in different parts of the world, including the best sites for job-seekers and where you can go for the leading NLP-related education programs on offer.
While ETH does not have a Linguistics department, its Data Analytics Lab , lead by Thomas Hofmann , focuses on topics in machine learning, natural language processing and understanding, data mining and information retrieval. Research foci include Big Data technology, data mining, machine learning, information retrieval and NLP.
Are you looking to study or work in the field of NLP? For this series, NLP People will be taking a closer look at the NLP education & development landscape in different parts of the world, including the best sites for job-seekers and where you can go for the leading NLP-related education programs on offer.
QA is a critical area of research in NLP, with numerous applications such as virtual assistants, chatbots, customer support, and educational platforms. Another research line in SQuARE is how to make information retrieval more effective. One type of user question is information-seeking. Euro) in 2021. Sung-Hyon Myaeng.
This post expands on the NAACL 2019 tutorial on Transfer Learning in NLP. In the span of little more than a year, transfer learning in the form of pretrained language models has become ubiquitous in NLP and has contributed to the state of the art on a wide range of tasks. However, transfer learning is not a recent phenomenon in NLP.
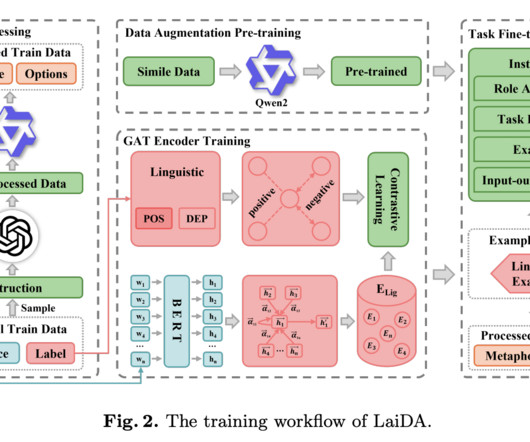
Metaphor Components Identification (MCI) is an essential aspect of natural language processing (NLP) that involves identifying and interpreting metaphorical elements such as tenor, vehicle, and ground. These components are critical for understanding metaphors, which are prevalent in daily communication, literature, and scientific discourse.
The development of Large Language Models (LLMs), such as GPT and BERT, represents a remarkable leap in computationallinguistics. The computational intensity required and the potential for various failures during extensive training periods necessitate innovative solutions for efficient management and recovery.
Ravfogel’s research focuses on understanding how neural networks learn distributed representations that encode structured information, and how these representations are utilized to solve complex tasks. This multidisciplinary foundation has informed his unique approach to computationallinguistics and machine learning.
The 57th Annual Meeting of the Association for ComputationalLinguistics (ACL 2019) is starting this week in Florence, Italy. We took the opportunity to review major research trends in the animated NLP space and formulate some implications from the business perspective. But what is the substance behind the buzz?
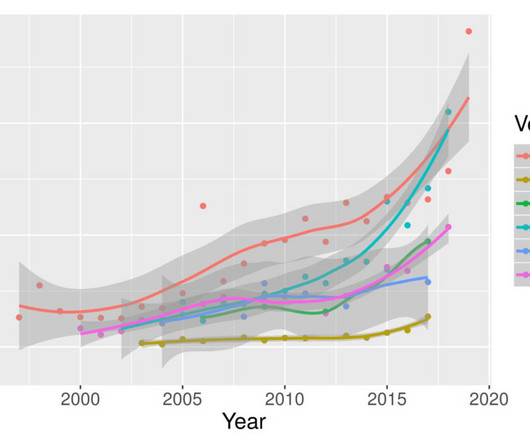
The growth of interest in NLP technology, fuelled largely by investment in AI applications, has been accompanied by unprecedented expansion of the preeminent NLP conferences: ACL, NAACL and EMNLP in particular. Paper count by country at the 2018 NLP conferences. Normalized paper count by country at the 2018 NLP conferences.
2021) 2021 saw many exciting advances in machine learning (ML) and natural language processing (NLP). Alternatively, FNet [27] uses 1D Fourier Transforms instead of self-attention to mix information at the token level. Popularized by GPT-3 [32] , prompting has emerged as a viable alternative input format for NLP models.
Challenges for open-source NLP One of the biggest challenges for Natural Language Processing is dealing with fast-moving and unpredictable technologies. This is a lot less true in AI or NLP. Since spaCy was released, the best practices for NLP have changed considerably. to adding tokenizer exceptions for Bengali or Hebrew.
These feats of computationallinguistics have redefined our understanding of machine-human interactions and paved the way for brand-new digital solutions and communications. Engineers train these models on vast amounts of information. Reliability: LLMs can inadvertently generate false information or fake news.
NLPositionality: Characterizing Design Biases of Datasets and Models Sebastin Santy, Jenny Liang, Ronan Le Bras*, Katharina Reinecke, Maarten Sap* Design biases in NLP systems, such as performance differences for different populations, often stem from their creator’s positionality, i.e., views and lived experiences shaped by identity and background.
Posted by Malaya Jules, Program Manager, Google This week, the 61st annual meeting of the Association for ComputationalLinguistics (ACL), a premier conference covering a broad spectrum of research areas that are concerned with computational approaches to natural language, is taking place online.
Discussion Implications of tokenization language disparity Overall, requiring more tokens (to tokenize the same message in a different language) means: You’re limited by how much information you can put in the prompt (because the context window is fixed). 4 ] Percentages of websites using various content languages (as of April 30, 2023).
Hundreds of researchers, students, recruiters, and business professionals came to Brussels this November to learn about recent advances, and share their own findings, in computationallinguistics and Natural Language Processing (NLP). BERT is a new milestone in NLP.
Jan 15: The year started out with us as guests on the NLP Highlights podcast , hosted by Matt Gardner and Waleed Ammar of Allen AI. In the interview, Matt and Ines talked about Prodigy , where training corpora come from and the challenges of annotating data for an NLP system – with some ideas about how to make it easier. ?
Picture by Anna Nekrashevich , Pexels.com Introduction Sentiment analysis is a natural language processing technique which identifies and extracts subjective information from source materials using computationallinguistics and text analysis. Spark NLP is a natural language processing library built on Apache Spark.
Source: Author The field of natural language processing (NLP), which studies how computer science and human communication interact, is rapidly growing. By enabling robots to comprehend, interpret, and produce natural language, NLP opens up a world of research and application possibilities.
Solution overview The target task in this post is to, given a chunk of text in the prompt, return questions that are related to the text but can’t be answered based on the information it contains. This is a useful task to identify missing information in a description or identify whether a query needs more information to be answered.
By integrating LLMs, the WxAI team enables advanced capabilities such as intelligent virtual assistants, natural language processing (NLP), and sentiment analysis, allowing Webex Contact Center to provide more personalized and efficient customer support.
At the same time, a wave of NLP startups has started to put this technology to practical use. I will be focusing on topics related to natural language processing (NLP) and African languages as these are the domains I am most familiar with. This post takes a closer look at how the AI community is faring in this endeavour.
Natural language processing (NLP) or computationallinguistics is one of the most important technologies of the information age. In this course, students will gain a thorough introduction to cutting-edge research in Deep Learning for NLP.
Seeing the emergence of such multilingual multimodal approaches is particularly encouraging as it is an improvement over the previous year’s ACL where multimodal approaches mainly dealt with English (based on an analysis of “multi-dimensional” NLP research we did for an ACL 2022 Findings paper ). Hershcovich et al.
Since the wind is coming from Maria’s direction, she asks “Maria” for a report on current weather conditions as an important piece of information. Another important limitation, as of now, is the recency of the information. For example, the communicative intent can be to convey information, socialise or ask someone to do something.
LLMs changed how we interact with the internet as finding relevant information or performing specific tasks was never this easy before. If a computer program is trained on enough data such that it can analyze, understand, and generate responses in natural language and other forms of content, it is called a Large Language Model (LLM).
For modular fine-tuning for NLP, check out our EMNLP 2022 tutorial. Instead of learning module parameters directly, they can be generated using an auxiliary model (a hypernetwork) conditioned on additional information and metadata. We cover such methods for NLP in our EMNLP 2022 tutorial. These models are monoliths.
In today’s enormous digital environment, where information flows at breakneck speed, determining the sentiment concealed inside textual data has become critical. On the other hand, Sentiment analysis is a method for automatically identifying, extracting, and categorizing subjective information from textual data. Daly, Peter T.
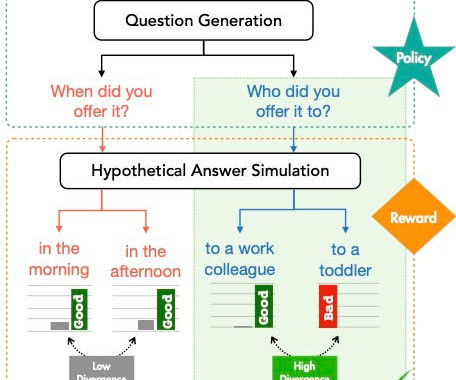
We evaluate the approach using human evaluation: compared to four other baselines ClarifyDelphi produces more informative and more relevant questions. It would be more elegant to have a way to automatically predict when enough contextual information has been obtained and the system does not have to ask an additional question.
Financial market participants are faced with an overload of information that influences their decisions, and sentiment analysis stands out as a useful tool to help separate out the relevant and meaningful facts and figures. In the main() function, you can call the run() function as shown in the following code.
This methodology has been used to provide explanations for sentiment classification, topic tagging, and other NLP tasks and could potentially work for chatbot-writing detection as well.
This job brought me in close contact with a large number of IT researchers, and some of them happened to work in computationallinguistics and machine learning. It might be a bit too early for an informative answer, but what can students and professionals planning to move to Europe expect from personal and professional perspectives?
In our review of 2019 we talked a lot about reinforcement learning and Generative Adversarial Networks (GANs), in 2020 we focused on Natural Language Processing (NLP) and algorithmic bias, in 202 1 Transformers stole the spotlight. As people played around with them, many problems such as bias and mis-information became prevalent.
Information retrieval (IR) methods are used to retrieve the relevant paragraphs. In addition, for many domains, the structure of the unlabelled data can contain information that may be useful for the end task. Linguistic and demographic utility of different NLP applications ( Blasi et al., TyDi QA ( Clark et al.,
self-supervised or cheaply supervised learning) has been the backbone of the many recent successes of foundation models 3 in NLP 4 5 6 7 8 9 and vision 10 11 12. Conference of the North American Chapter of the Association for ComputationalLinguistics. ↩ Devlin, J., Neural Information Processing Systems. ↩ Finn, C.,
Sentiment analysis, commonly referred to as opinion mining/sentiment classification, is the technique of identifying and extracting subjective information from source materials using computationallinguistics , text analysis , and natural language processing. as these words do not make any sense to machines.
Timo Mertens is the Head of ML and NLP Products at Grammarly. What information do you want to include? That ranges all the way from analytical and computationallinguists to applied research scientists, machine learning engineers, data scientists, product managers, designers, UX researchers, and so on.
Timo Mertens is the Head of ML and NLP Products at Grammarly. What information do you want to include? That ranges all the way from analytical and computationallinguists to applied research scientists, machine learning engineers, data scientists, product managers, designers, UX researchers, and so on.
As many other NLP tasks, this one is also difficult. We used other structured knowledge resources that contain exactly this kind of information, are much larger than WordNet and are frequently updated. Proceedings of the 14th conference on Computationallinguistics-Volume 2. Association for ComputationalLinguistics.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content