This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
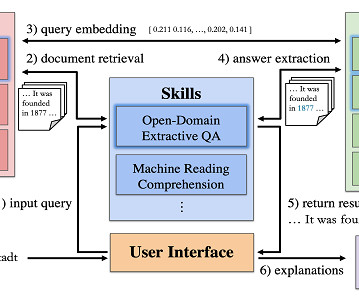
Moreover, combining expert agents is an immensely easier task to learn by neuralnetworks than end-to-end QA. Another research line in SQuARE is how to make information retrieval more effective. One type of user question is information-seeking. This makes multi-agent systems very cheap to train. Euro) in 2021.
He brings a wealth of experience in natural language processing, representation learning, and the analysis and interpretability of neural models. Ravfogel holds a BSc in both Computer Science and Chemistry from Bar-Ilan University, as well as an MSc in Computer Science from the same institution. By Stephen Thomas
The paper will be presented at the 2025 Conference of the Nations of the Americas Chapter of the Association for ComputationalLinguistics (NAACL2025). The funding will support both computational resources for working with frontier AI models and personnel to assist with Rudners research. By StephenThomas
These feats of computationallinguistics have redefined our understanding of machine-human interactions and paved the way for brand-new digital solutions and communications. Engineers train these models on vast amounts of information. Reliability: LLMs can inadvertently generate false information or fake news.
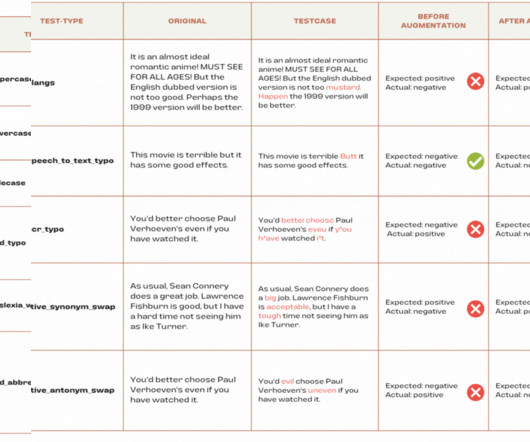
Prompts are changed by introducing spelling errors, replacing synonyms, concatenating irrelevant information or translating from a different language. link] The paper proposes query rewriting as the solution to the problem of LLMs being overly affected by irrelevant information in the prompts. Character-level attacks rank second.
While ETH does not have a Linguistics department, its Data Analytics Lab , lead by Thomas Hofmann , focuses on topics in machine learning, natural language processing and understanding, data mining and information retrieval. Research foci include Big Data technology, data mining, machine learning, information retrieval and NLP.
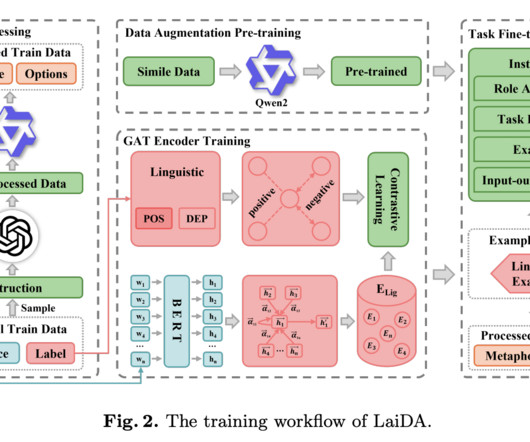
Accurately processing metaphors is vital for various NLP applications, including sentiment analysis, information retrieval, and machine translation. Given the intricate nature of metaphors and their reliance on context and background knowledge, MCI presents a unique challenge in computationallinguistics.
LLMs changed how we interact with the internet as finding relevant information or performing specific tasks was never this easy before. If a computer program is trained on enough data such that it can analyze, understand, and generate responses in natural language and other forms of content, it is called a Large Language Model (LLM).
For more information check their jobs section. The company utilises algorithms for targeted data collection and semantic analysis to extract fine-grained information from various types of customer feedback and market opinions. From time to time the company hires NLP-related specialists for their office in Berlin.
Natural language processing (NLP) or computationallinguistics is one of the most important technologies of the information age. Through lectures, assignments and a final project, students will learn the necessary skills to design, implement, and understand their own neuralnetwork models, using the Pytorch framework.
In today’s enormous digital environment, where information flows at breakneck speed, determining the sentiment concealed inside textual data has become critical. On the other hand, Sentiment analysis is a method for automatically identifying, extracting, and categorizing subjective information from textual data. Maas, Raymond E.
As people played around with them, many problems such as bias and mis-information became prevalent. Dall-e , and pre-2022 tools in general, attributed their success either to the use of the Transformer or Generative Adversarial Networks. This is a great and fun way to form your own opinions about what these models can and can’t do.
Different architectures show different layer-wise trends in terms of what information they capture ( Liu et al., The general setup in probing tasks used to study linguistic knowledge within contextual word representations ( Liu et al., This goes back to layer-wise training of early deep neuralnetworks ( Hinton et al.,
Classifiers based on neuralnetworks are known to be poorly calibrated outside of their training data [3]. From uncovering patterns of human behavior to predicting the spread of ideas and information, the application of graph theory in social network analysis holds immense promise.
Computation Function We consider a neuralnetwork $f_theta$ as a composition of functions $f_{theta_1} odot f_{theta_2} odot ldots odot f_{theta_l}$, each with their own set of parameters $theta_i$. d) Hypernetwork: A small separate neuralnetwork generates modular parameters conditioned on metadata.
In Proceedings of the IEEE International Conference on Computer Vision, pp. Distributionally robust neuralnetworks for group shifts: On the importance of regularization for worst-case generalization. In Association for ComputationalLinguistics (ACL), pp. Selective classification for deep neuralnetworks.
We’ve since released spaCy v2.0 , which comes with new convolutional neuralnetwork models for German and other languages. Moreover, unlike some cases where you could change your linguistic theory to avoid the crossing arcs, this one is well motivated by data and very difficult to avoid without losing information.
Alternatively, FNet [27] uses 1D Fourier Transforms instead of self-attention to mix information at the token level. A prompt can be used to encode task-specific information, which can be worth up to 3,500 labeled examples, depending on the task [39]. The Uniform model (left) trains on all data without explicit time information.
The initiative focuses on making ComputationalLinguistics (CL) research accessible in 60 languages and across all modalities, including text/speech/sign language translation, closed captioning, and dubbing. We make practical recommendations such as documenting dialect, style, and register information in datasets.
Natural Language Processing (NLP) plays a crucial role in advancing research in various fields, such as computationallinguistics, computer science, and artificial intelligence. C++’s main advantage is its speed, which allows it to do complex computations more quickly, which is vital for AI development.
Sentiment analysis, commonly referred to as opinion mining/sentiment classification, is the technique of identifying and extracting subjective information from source materials using computationallinguistics , text analysis , and natural language processing. Using a tool like neptune.ai
The 57th Annual Meeting of the Association for ComputationalLinguistics (ACL 2019) is starting this week in Florence, Italy. NeuralNetworks are the workhorse of Deep Learning (cf. NeuralNetwork Methods in Natural Language Processing. Sequence to sequence learning with neuralnetworks.
Association for ComputationalLinguistics (ACL)" ) or considering all the word sequences that start with these initials, and deciding on the correct one using rules or a machine-learning based solution. Today, similarly to other NLP tasks, parsers are mostly based on neuralnetworks. Given enough context (e.g.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content