This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Learn about the concept of information extraction We will apply. The post How Search Engines like Google Retrieve Results: Introduction to Information Extraction using Python and spaCy appeared first on Analytics Vidhya. Overview How do search engines like Google understand our queries and provide relevant results?
if this statement sounds familiar, you are not foreign to the field of computationallinguistics and conversational AI. Source: Creative Commons In recent years, we have seen an explosion in the use of voice assistants, chatbots, and other conversational agents that use naturallanguage to communicate with humans.
Source: Author The field of naturallanguageprocessing (NLP), which studies how computer science and human communication interact, is rapidly growing. By enabling robots to comprehend, interpret, and produce naturallanguage, NLP opens up a world of research and application possibilities.
Ravfogel is currently completing his PhD in the NaturalLanguageProcessing Lab at Bar-Ilan University, supervised by Prof. He brings a wealth of experience in naturallanguageprocessing, representation learning, and the analysis and interpretability of neural models. Yoav Goldberg. By Stephen Thomas
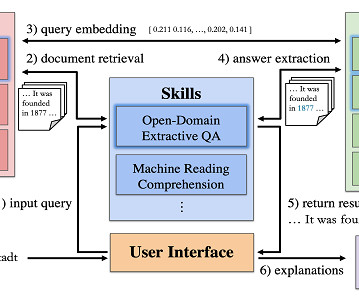
Question Answering is the task in NaturalLanguageProcessing that involves answering questions posed in naturallanguage. Another research line in SQuARE is how to make information retrieval more effective. One type of user question is information-seeking. Don’t worry, you’re not alone!
NaturalLanguageProcessing has seen some major breakthroughs in the past years; with the rise of Artificial Intelligence, the attempt at teaching machines to master human language is becoming an increasingly popular field in academia and industry all over the world. University of St. Gallen The University of St.
The third article of the series covers Germany; see our previous articles about Ireland and France RESEARCH GROUPS AND LABS DFKI Language Technology Lab DFKI Language Technology lab is represented by Berlin LT Lab and the Multilingual Technologies Lab in Saarbrücken. More information can be found on their webpage.
However, among all the modern-day AI innovations, one breakthrough has the potential to make the most impact: large language models (LLMs). These feats of computationallinguistics have redefined our understanding of machine-human interactions and paved the way for brand-new digital solutions and communications.
Discussion Implications of tokenization language disparity Overall, requiring more tokens (to tokenize the same message in a different language) means: You’re limited by how much information you can put in the prompt (because the context window is fixed). Indo-European, Sino-Tibetan).[
I have written short summaries of 68 different research papers published in the areas of Machine Learning and NaturalLanguageProcessing. Prompts are changed by introducing spelling errors, replacing synonyms, concatenating irrelevant information or translating from a different language.
Posted by Malaya Jules, Program Manager, Google This week, the 61st annual meeting of the Association for ComputationalLinguistics (ACL), a premier conference covering a broad spectrum of research areas that are concerned with computational approaches to naturallanguage, is taking place online.
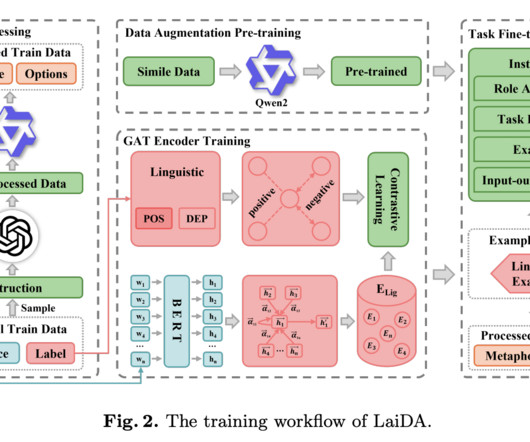
Metaphor Components Identification (MCI) is an essential aspect of naturallanguageprocessing (NLP) that involves identifying and interpreting metaphorical elements such as tenor, vehicle, and ground. The primary issue in MCI lies in the complexity and diversity of metaphors.
For more information check their jobs section. Utilising naturallanguage understanding, they provide solutions that literally ‘speak human language’ by making users free from the need to acquire technical jargon. From time to time the company hires NLP-related specialists for their office in Berlin. They are hiring.
Since the wind is coming from Maria’s direction, she asks “Maria” for a report on current weather conditions as an important piece of information. Another important limitation, as of now, is the recency of the information. When we use language, we do so for a specific purpose, which is our communicative intent.
Hundreds of researchers, students, recruiters, and business professionals came to Brussels this November to learn about recent advances, and share their own findings, in computationallinguistics and NaturalLanguageProcessing (NLP).
Solution overview The target task in this post is to, given a chunk of text in the prompt, return questions that are related to the text but can’t be answered based on the information it contains. This is a useful task to identify missing information in a description or identify whether a query needs more information to be answered.
Different architectures show different layer-wise trends in terms of what information they capture ( Liu et al., The general setup in probing tasks used to study linguistic knowledge within contextual word representations ( Liu et al., On the whole, it is difficult to learn certain types of information from raw text.
Picture by Anna Nekrashevich , Pexels.com Introduction Sentiment analysis is a naturallanguageprocessing technique which identifies and extracts subjective information from source materials using computationallinguistics and text analysis.
LLMs changed how we interact with the internet as finding relevant information or performing specific tasks was never this easy before. What are Large Language Models (LLMs)? In generative AI, human language is perceived as a difficult data type.
Developing models that work for more languages is important in order to offset the existing language divide and to ensure that speakers of non-English languages are not left behind, among many other reasons. On the one hand, data should reflect the background of the speakers speaking the language.
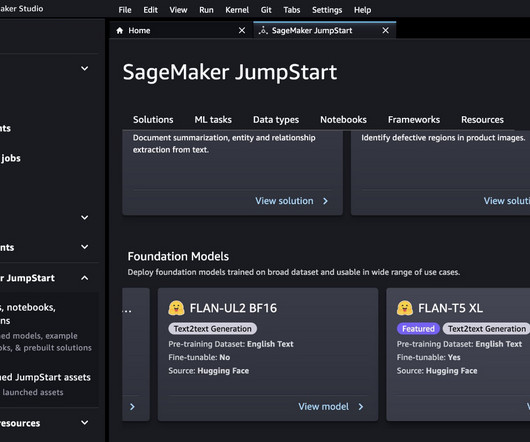
Google created a new learning path guides you through a curated collection of content on generative AI products and technologies, from the fundamentals of Large Language Models to how to create and deploy generative AI solutions on Google Cloud.
Sentiment analysis, commonly referred to as opinion mining/sentiment classification, is the technique of identifying and extracting subjective information from source materials using computationallinguistics , text analysis , and naturallanguageprocessing. Using a tool like neptune.ai
Informed by prior work, we test the following 4 hypotheses: Redirect - Inspired by Brahnam 5 , we hypothesize that using explicit redirection when responding to an offensive user utterance is an effective strategy. Ideally, everyone would take turns responding to prompts, sharing information about themselves, and introducing new topics.
This job brought me in close contact with a large number of IT researchers, and some of them happened to work in computationallinguistics and machine learning. This was when I realized I might try to pursue this path too, as it would allow me to combine my passion for languages and interest in technologies.
In today’s enormous digital environment, where information flows at breakneck speed, determining the sentiment concealed inside textual data has become critical. On the other hand, Sentiment analysis is a method for automatically identifying, extracting, and categorizing subjective information from textual data. Daly, Peter T.
From uncovering patterns of human behavior to predicting the spread of ideas and information, the application of graph theory in social network analysis holds immense promise. 2019 Annual Conference of the North American Chapter of the Association for ComputationalLinguistics. [7] Attention is not Explanation. Weigreffe, Y.
Financial market participants are faced with an overload of information that influences their decisions, and sentiment analysis stands out as a useful tool to help separate out the relevant and meaningful facts and figures. She has a technical background in AI and NaturalLanguageProcessing.
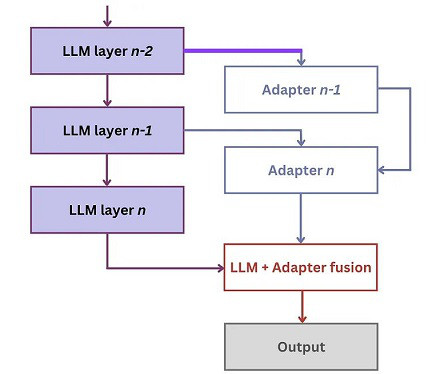
Instead of learning module parameters directly, they can be generated using an auxiliary model (a hypernetwork) conditioned on additional information and metadata. We provide a high-level overview of some of the trade-offs of the different computation functions below. Speech processing. Module parameter generation. Instead
In this post I’ll share some lessons we’ve learned from running spaCy , the popular and fast-growing library for NaturalLanguageProcessing in Python. Challenges for open-source NLP One of the biggest challenges for NaturalLanguageProcessing is dealing with fast-moving and unpredictable technologies.
Ines’ talk in the language track, “Practical Transfer Learning for NLP with spaCy and Prodigy” , focused on the increasing trend of initializing models with information from large raw-text corpora, and how you can use this type of technique in spaCy and Prodigy. Sep 4: spacy-transformers kept getting better as we released v0.4.0,
2021) 2021 saw many exciting advances in machine learning (ML) and naturallanguageprocessing (NLP). Alternatively, FNet [27] uses 1D Fourier Transforms instead of self-attention to mix information at the token level. 2021 saw several breakthroughs in ML applied to advance the natural sciences.
In our review of 2019 we talked a lot about reinforcement learning and Generative Adversarial Networks (GANs), in 2020 we focused on NaturalLanguageProcessing (NLP) and algorithmic bias, in 202 1 Transformers stole the spotlight. As humans we do not know exactly how we learn language: it just happens. What happened?
The initiative focuses on making ComputationalLinguistics (CL) research accessible in 60 languages and across all modalities, including text/speech/sign language translation, closed captioning, and dubbing. We make practical recommendations such as documenting dialect, style, and register information in datasets.
Information retrieval (IR) methods are used to retrieve the relevant paragraphs. In addition, for many domains, the structure of the unlabelled data can contain information that may be useful for the end task. For such languages, datasets must necessarily be cross-lingual. Classic sparse methods such as BM25 ( Robertson et al.,
What information do you want to include? Let’s double-click into correctness to describe our approach on how technology, and specifically machine learning and naturallanguageprocessing, can come together in a very user-centric way to solve real problems that our users face every single day.
What information do you want to include? Let’s double-click into correctness to describe our approach on how technology, and specifically machine learning and naturallanguageprocessing, can come together in a very user-centric way to solve real problems that our users face every single day.
Moreover, unlike some cases where you could change your linguistic theory to avoid the crossing arcs, this one is well motivated by data and very difficult to avoid without losing information. To summarize the above, we need non-projective trees to represent the information that we are interested in when parsing naturallanguage.
After I dedicated the previous post to the awesome field of naturallanguageprocessing, in this post I will drill down and tell you about the specific task that I'm working on: recognizing lexical inference. Proceedings of the 14th conference on Computationallinguistics-Volume 2. ↩ [3] Harris, Zellig S.
By integrating LLMs, the WxAI team enables advanced capabilities such as intelligent virtual assistants, naturallanguageprocessing (NLP), and sentiment analysis, allowing Webex Contact Center to provide more personalized and efficient customer support.
By integrating LLMs, WxAI team enables advanced capabilities such as intelligent virtual assistants, naturallanguageprocessing, and sentiment analysis, allowing Webex Contact Center to provide more personalized and efficient customer support.
The 57th Annual Meeting of the Association for ComputationalLinguistics (ACL 2019) is starting this week in Florence, Italy. Jumping NLP Curves: A Review of NaturalLanguageProcessing Research [Review Article]. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Hirst (2017).
For example, this blog post is published in a blog that largely discusses naturallanguageprocessing, so if I write "NLP", you'd know I refer to naturallanguageprocessing rather than to neuro-linguistic programming. Given enough context (e.g. This can either be by searching for a pattern (e.g.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























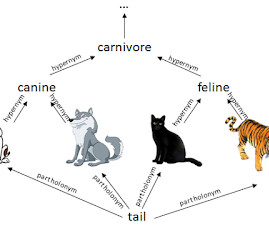










Let's personalize your content