This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Learn about the concept of information extraction We will apply. The post How Search Engines like Google Retrieve Results: Introduction to Information Extraction using Python and spaCy appeared first on Analytics Vidhya. Overview How do search engines like Google understand our queries and provide relevant results?
We discovered early on in the project that none of the papers we considered replicating had sufficient information for replicability and that only 13% of authors were willing and able to provide the missing information ( paper ) ( blog ). Once ComputationalLinguistics. So far our findings have been pretty depressing. We
if this statement sounds familiar, you are not foreign to the field of computationallinguistics and conversational AI. These technologies have revolutionized the way we interact with computers — enabling us to access information, make purchases, and carry out an array of tasks through simple voice commands or text messages.
Language Agents represent a transformative advancement in computationallinguistics. They leverage large language models (LLMs) to interact with and process information from the external world. In conclusion, the Uncertainty-Aware Language Agent methodology marks a significant leap forward in computationallinguistics.
Computationallinguistics focuses on developing advanced language models capable of understanding and generating human language. However, these approaches have limitations, such as the risk of models forgetting previously learned information or requiring extensive new data for effective updating.
Speech Recognition and Processing Speech Recognition and Processing is a subfield of AI and computationallinguistics that focuses on developing systems capable of recognizing and interpreting human speech. For AGI, the ability to process and synthesize information from multiple senses is a game-changer.
In computationallinguistics, much research focuses on how language models handle and interpret extensive textual data. These models are crucial for tasks that require identifying and extracting specific information from large volumes of text, presenting a considerable challenge in ensuring accuracy and efficiency.
For example, it organizes computations in a way that minimizes the need to load data repeatedly from memory, ensuring that the process doesn’t become a bottleneck. Additionally, Marlin uses asynchronous loading of data, meaning it can fetch the necessary information while continuing other computations, optimizing the use of the GPU.
Research in computationallinguistics continues to explore how large language models (LLMs) can be adapted to integrate new knowledge without compromising the integrity of existing information. This structured approach provides a clear view of the impact of fine-tuning with both familiar and novel data on model accuracy.
In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. In Proceedings of the 2022 Conference of the North American Chapter of the Association for ComputationalLinguistics: Human Language Technologies, pages 1115–1127, Seattle, United States. Association for ComputationalLinguistics.
The development of Large Language Models (LLMs), such as GPT and BERT, represents a remarkable leap in computationallinguistics. The computational intensity required and the potential for various failures during extensive training periods necessitate innovative solutions for efficient management and recovery.
Ravfogel’s research focuses on understanding how neural networks learn distributed representations that encode structured information, and how these representations are utilized to solve complex tasks. This multidisciplinary foundation has informed his unique approach to computationallinguistics and machine learning.
DFKI LT lab conducts advanced research in language technology and develops novel solutions related to information and knowledge management, content production, speech and text processing. For more information about job openings , projects , and publications visit their website. More information can be found on their webpage.
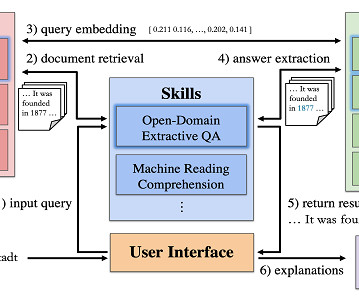
Another research line in SQuARE is how to make information retrieval more effective. Information retrieval is a key aspect in question answering since it is used to obtain the documents to extract the answers to the given questions. One type of user question is information-seeking. Euro) in 2021.
The paper will be presented at the 2025 Conference of the Nations of the Americas Chapter of the Association for ComputationalLinguistics (NAACL2025). The project builds on Rudners long-standing collaboration with CSET, where he has published several papers on AI policy and governance since 2019. By StephenThomas
These feats of computationallinguistics have redefined our understanding of machine-human interactions and paved the way for brand-new digital solutions and communications. Engineers train these models on vast amounts of information. Reliability: LLMs can inadvertently generate false information or fake news.
While ETH does not have a Linguistics department, its Data Analytics Lab , lead by Thomas Hofmann , focuses on topics in machine learning, natural language processing and understanding, data mining and information retrieval. Research foci include Big Data technology, data mining, machine learning, information retrieval and NLP.
Prompts are changed by introducing spelling errors, replacing synonyms, concatenating irrelevant information or translating from a different language. link] The paper proposes query rewriting as the solution to the problem of LLMs being overly affected by irrelevant information in the prompts. Character-level attacks rank second.
We’re kind of at the point where we can make fire but do not even have the rudiments of what we’d need to understand it,” my friend Luke Gessler , a computationallinguist, told me. We have no reason to believe any current AIs are sentient, but we also have no way of knowing whether or how that could change.
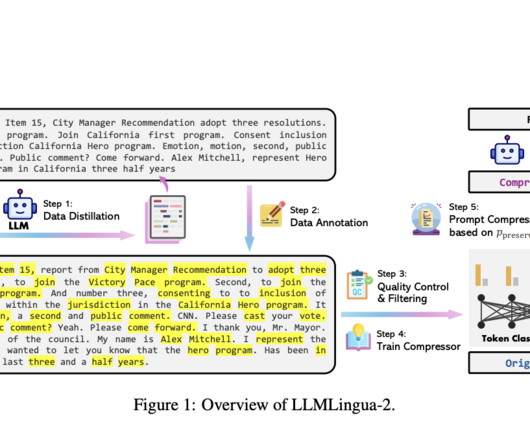
This groundbreaking study delves into language model efficiency, aiming to streamline communication between humans and machines and reduce the verbosity of natural language without compromising the conveyed information’s essence. The technical foundation of this research is both innovative and robust. Check out the Paper.
The *CL conferences created the NLP Reproducibility Checklist in 2020 to be completed by authors at submission to remind them of key information to include. First, they found evidence of an increase in reporting of information on efficiency, validation performance, summary statistics, and hyperparameters after the Checklist’s introduction.
Discussion Implications of tokenization language disparity Overall, requiring more tokens (to tokenize the same message in a different language) means: You’re limited by how much information you can put in the prompt (because the context window is fixed). Association for ComputationalLinguistics. Indo-European, Sino-Tibetan).[
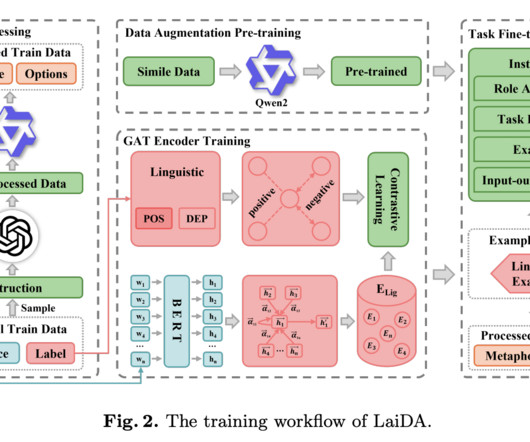
Accurately processing metaphors is vital for various NLP applications, including sentiment analysis, information retrieval, and machine translation. Given the intricate nature of metaphors and their reliance on context and background knowledge, MCI presents a unique challenge in computationallinguistics.
Posted by Malaya Jules, Program Manager, Google This week, the 61st annual meeting of the Association for ComputationalLinguistics (ACL), a premier conference covering a broad spectrum of research areas that are concerned with computational approaches to natural language, is taking place online.
For more information check their jobs section. The company utilises algorithms for targeted data collection and semantic analysis to extract fine-grained information from various types of customer feedback and market opinions. From time to time the company hires NLP-related specialists for their office in Berlin.
Since the wind is coming from Maria’s direction, she asks “Maria” for a report on current weather conditions as an important piece of information. Another important limitation, as of now, is the recency of the information. For example, the communicative intent can be to convey information, socialise or ask someone to do something.
Informed by prior work, we test the following 4 hypotheses: Redirect - Inspired by Brahnam 5 , we hypothesize that using explicit redirection when responding to an offensive user utterance is an effective strategy. Ideally, everyone would take turns responding to prompts, sharing information about themselves, and introducing new topics.
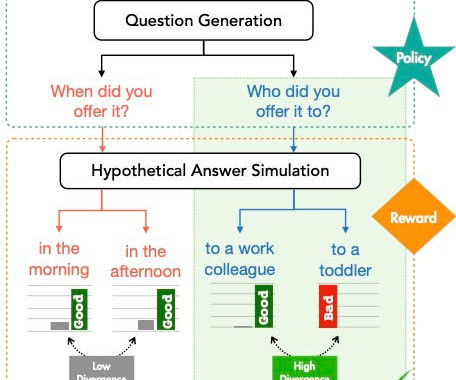
We evaluate the approach using human evaluation: compared to four other baselines ClarifyDelphi produces more informative and more relevant questions. It would be more elegant to have a way to automatically predict when enough contextual information has been obtained and the system does not have to ask an additional question.
Solution overview The target task in this post is to, given a chunk of text in the prompt, return questions that are related to the text but can’t be answered based on the information it contains. This is a useful task to identify missing information in a description or identify whether a query needs more information to be answered.
Hundreds of researchers, students, recruiters, and business professionals came to Brussels this November to learn about recent advances, and share their own findings, in computationallinguistics and Natural Language Processing (NLP).
From uncovering patterns of human behavior to predicting the spread of ideas and information, the application of graph theory in social network analysis holds immense promise. 2019 Annual Conference of the North American Chapter of the Association for ComputationalLinguistics. [7] Attention is not Explanation. Weigreffe, Y.
In today’s enormous digital environment, where information flows at breakneck speed, determining the sentiment concealed inside textual data has become critical. On the other hand, Sentiment analysis is a method for automatically identifying, extracting, and categorizing subjective information from textual data. Daly, Peter T.
Different architectures show different layer-wise trends in terms of what information they capture ( Liu et al., The general setup in probing tasks used to study linguistic knowledge within contextual word representations ( Liu et al., On the whole, it is difficult to learn certain types of information from raw text.
This job brought me in close contact with a large number of IT researchers, and some of them happened to work in computationallinguistics and machine learning. It might be a bit too early for an informative answer, but what can students and professionals planning to move to Europe expect from personal and professional perspectives?
Picture by Anna Nekrashevich , Pexels.com Introduction Sentiment analysis is a natural language processing technique which identifies and extracts subjective information from source materials using computationallinguistics and text analysis.
Initiatives The Association for ComputationalLinguistics (ACL) has emphasized the importance of language diversity, with a special theme track at the main ACL 2022 conference on this topic. Practical data For new datasets, it is thus ever more important to create data that is informed by real-world usage.
Financial market participants are faced with an overload of information that influences their decisions, and sentiment analysis stands out as a useful tool to help separate out the relevant and meaningful facts and figures. In the main() function, you can call the run() function as shown in the following code.
Ines’ talk in the language track, “Practical Transfer Learning for NLP with spaCy and Prodigy” , focused on the increasing trend of initializing models with information from large raw-text corpora, and how you can use this type of technique in spaCy and Prodigy. Sep 4: spacy-transformers kept getting better as we released v0.4.0,
Alternatively, FNet [27] uses 1D Fourier Transforms instead of self-attention to mix information at the token level. A prompt can be used to encode task-specific information, which can be worth up to 3,500 labeled examples, depending on the task [39]. The Uniform model (left) trains on all data without explicit time information.
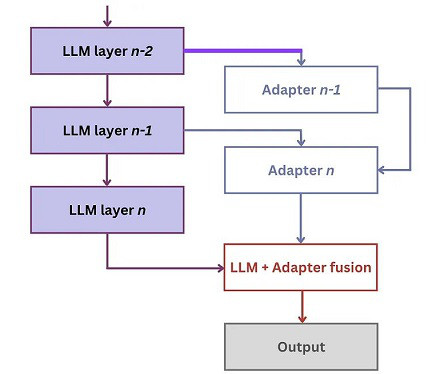
Instead of learning module parameters directly, they can be generated using an auxiliary model (a hypernetwork) conditioned on additional information and metadata. We provide a high-level overview of some of the trade-offs of the different computation functions below. Computer vision and cross-modal learning.
As people played around with them, many problems such as bias and mis-information became prevalent. The first computationallinguistics methods tried to bypass the immense complexity of human language learning by hard-coding syntax and grammar rules in their models. Some of this year’s breakthroughs created controversies.
It may inform discussion if we report one other statistic we’ve been able to retrieve thanks to data sharing by Emily Bender & Leon Derczynski, the program chairs for COLING 2018. One good reason to take our major conferences to new countries is to equalise the barrier of obtaining visas to attend.
Conference of the North American Chapter of the Association for ComputationalLinguistics. ↩ Devlin, J., Annual Meeting of the Association for ComputationalLinguistics. ↩ Brown et al. Neural Information Processing Systems. ↩ Finn, C., . ↩ Peters, M., Neumann, M., Gardner, M.,
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content