This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Dwell in the Beginning: How Language Models Embed Long Documents for Dense Retrieval João Coelho, Bruno Martins, João Magalhães, Jamie Callan, Chenyan Xiong. link] The paper investigates positional biases when encoding long documents into a vector for similarity-based retrieval. ComputationalLinguistics 2022. ArXiv 2024.
It’s Institute of ComputationalLinguistics , which includes the Phonetics Laboratory , lead by Martin Volk and Volker Dellwo, as well as the URPP Language and Space perform research in NLP topics, such as machine translation, sentiment analysis, speech recognition and dialect detection. University of St.
It combines statistics and mathematics with computationallinguistics. NLTK stands for Natural Language Toolkit, comprising Python modules, datasets, corpora, and tutorials designed for Natural Language Processing (NLP). It stands as one of the most revered and recognized packages in Python, demonstrated by its impressive 12.6k
The goal of QA is to create models that can understand the nuances of a question and some given evidence documents to provide an accurate and concise answer. QA is a critical area of research in NLP, with numerous applications such as virtual assistants, chatbots, customer support, and educational platforms. Haritz Puerto is a Ph.D.
Are you looking to study or work in the field of NLP? For this series, NLP People will be taking a closer look at the NLP education & development landscape in different parts of the world, including the best sites for job-seekers and where you can go for the leading NLP-related education programs on offer.
This post expands on the NAACL 2019 tutorial on Transfer Learning in NLP. In the span of little more than a year, transfer learning in the form of pretrained language models has become ubiquitous in NLP and has contributed to the state of the art on a wide range of tasks. However, transfer learning is not a recent phenomenon in NLP.
As we’re moving into a phase with more options for contributions, we want to encourage them where they make the biggest difference: language data, interoperation, tests and documentation. Challenges for open-source NLP One of the biggest challenges for Natural Language Processing is dealing with fast-moving and unpredictable technologies.
2021) 2021 saw many exciting advances in machine learning (ML) and natural language processing (NLP). If CNNs are pre-trained the same way as transformer models, they achieve competitive performance on many NLP tasks [28]. Popularized by GPT-3 [32] , prompting has emerged as a viable alternative input format for NLP models.
Posted by Malaya Jules, Program Manager, Google This week, the 61st annual meeting of the Association for ComputationalLinguistics (ACL), a premier conference covering a broad spectrum of research areas that are concerned with computational approaches to natural language, is taking place online.
The test data consists of three different paragraphs, one on the Australian city of Adelaide from the first two paragraphs of it Wikipedia page , one regarding Amazon Elastic Block Store (Amazon EBS) from the Amazon EBS documentation , and one of Amazon Comprehend from the Amazon Comprehend documentation.
Picture by Anna Nekrashevich , Pexels.com Introduction Sentiment analysis is a natural language processing technique which identifies and extracts subjective information from source materials using computationallinguistics and text analysis. Spark NLP is a natural language processing library built on Apache Spark.
Source: Author The field of natural language processing (NLP), which studies how computer science and human communication interact, is rapidly growing. By enabling robots to comprehend, interpret, and produce natural language, NLP opens up a world of research and application possibilities.
Hundreds of researchers, students, recruiters, and business professionals came to Brussels this November to learn about recent advances, and share their own findings, in computationallinguistics and Natural Language Processing (NLP). BERT is a new milestone in NLP.
In here, the distinction is that base models want to complete documents(with a given context) where assistant models can be used/tricked into performing tasks with prompt engineering. Natural language processing (NLP) or computationallinguistics is one of the most important technologies of the information age.
Jan 15: The year started out with us as guests on the NLP Highlights podcast , hosted by Matt Gardner and Waleed Ammar of Allen AI. In the interview, Matt and Ines talked about Prodigy , where training corpora come from and the challenges of annotating data for an NLP system – with some ideas about how to make it easier. ?
At the same time, a wave of NLP startups has started to put this technology to practical use. I will be focusing on topics related to natural language processing (NLP) and African languages as these are the domains I am most familiar with. This post takes a closer look at how the AI community is faring in this endeavour.
Seeing the emergence of such multilingual multimodal approaches is particularly encouraging as it is an improvement over the previous year’s ACL where multimodal approaches mainly dealt with English (based on an analysis of “multi-dimensional” NLP research we did for an ACL 2022 Findings paper ). Hershcovich et al.
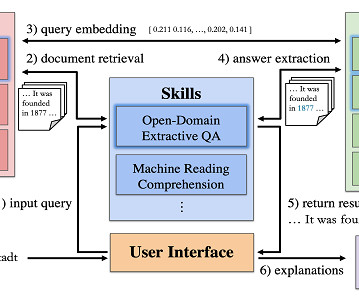
Open-Retrieval QA vs Reading Comprehension Open-retrieval QA focuses on the most general setting where given a question we first need to retrieve relevant documents from a large corpus such as Wikipedia. We then process these documents to identify the relevant answer as can be seen below. XQA ( Liu et al., TyDi QA ( Clark et al.,
OpenAI themselves have included some considerations for education in their ChatGPT documentation, acknowledging the chatbot’s use in academic dishonesty. A Chatbot Detector could pick up on the writing style of a human (since a human re-wrote the chatbot answer) and classify the document as human-written. Attention is not Explanation.
This means that an English-only NLP system can get away with some very useful simplifying assumptions. In the same way that a physicist might assume a frictionless surface or a spherical cow , sometimes it’s useful for computationallinguists to assume projective trees and context-free grammars. It’s a simplifying assumption.
You expect the search engine to retrieve the following documents: Figure 1: search results for the query "actor Scientology" that don't directly involve the word "actor" since they are talking about a certain actor (Tom Cruise or John Travolta) and Scientology. However, what if these documents don't contain the word actor ?
Apart from averaging the word vectors of all the words within a paper, there are also specialised approaches to learn embeddings for whole documents. Both LSA and doc2vec allow us to take documents of text and embed them in a vector space. In our case, we deliberately use the whole full-text of an ArXiv submission as the document.
The 57th Annual Meeting of the Association for ComputationalLinguistics (ACL 2019) is starting this week in Florence, Italy. We took the opportunity to review major research trends in the animated NLP space and formulate some implications from the business perspective. But what is the substance behind the buzz?
By integrating LLMs, the WxAI team enables advanced capabilities such as intelligent virtual assistants, natural language processing (NLP), and sentiment analysis, allowing Webex Contact Center to provide more personalized and efficient customer support.
For example, this blog post is published in a blog that largely discusses natural language processing, so if I write "NLP", you'd know I refer to natural language processing rather than to neuro-linguistic programming. Word Sense Disambiguation (WSD) is an NLP task aimed at disambiguating a word in context.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content