This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This post gives a brief overview of modularity in deeplearning. Fuelled by scaling laws, state-of-the-art models in machine learning have been growing larger and larger. We give an in-depth overview of modularity in our survey on Modular DeepLearning. Case studies of modular deeplearning.
Babbel Based in Berlin and New York, Babbel is a language learning platform, helping one learn a new language on the go. handles most common and repetitive questions in self-learning chat-based customer service. Their products are language-agnostic as they use deeplearning in the development of their algorithms.
Machine learning especially DeepLearning is the backbone of every LLM. Emergence and History of LLMs Artificial Neural Networks (ANNs) and Rule-based Models The foundation of these ComputationalLinguistics models (CL) dates back to the 1940s when Warren McCulloch and Walter Pitts laid the groundwork for AI.
70% of research papers published in a computationallinguistics conference only evaluated English.[ In Findings of the Association for ComputationalLinguistics: ACL 2022 , pages 2340–2354, Dublin, Ireland. Association for ComputationalLinguistics. Association for ComputationalLinguistics.
In the past, the DeepLearning community solved the data shortage with self-supervision — pre-training LLMs using next-token prediction, a learning signal that is available “for free” since it is inherent to any text. Association for ComputationalLinguistics. [2] Association for ComputationalLinguistics. [4]
Deeplearning has enabled improvements in the capabilities of robots on a range of problems such as grasping 1 and locomotion 2 in recent years. Deep contextualized word representations. Conference of the North American Chapter of the Association for ComputationalLinguistics. ↩ Devlin, J., Neumann, M.,
This post is partially based on a keynote I gave at the DeepLearning Indaba 2022. These include groups focusing on linguistic regions such as Masakhane for African languages, AmericasNLP for native American languages, IndoNLP for Indonesian languages, GhanaNLP and HausaNLP , among others. Vulić, I., & Søgaard, A.
Deeplearning face attributes in the wild. In Proceedings of the IEEE International Conference on ComputerVision, pp. In Association for ComputationalLinguistics (ACL), pp. SelectiveNet: A deep neural network with an integrated reject option. Selective classification for deep neural networks.
In computervision, supervised pre-trained models such as Vision Transformer [2] have been scaled up [3] and self-supervised pre-trained models have started to match their performance [4]. Transactions of the Association for ComputationalLinguistics, 9, 978–994. link] ↩︎ Hendricks, L.
2019 Annual Conference of the North American Chapter of the Association for ComputationalLinguistics. [7] 57th Annual Meeting of the Association for ComputationalLinguistics [9] C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Weigreffe, Y.
If the embedding vectors work as expected, computervision papers should be closer together in this space, and reinforcement learning (RL) papers close to other RL papers. vector: Probing sentence embeddings for linguistic properties. Simple, like with like. What you can cram into a single $ &!#* 2126–2136).
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

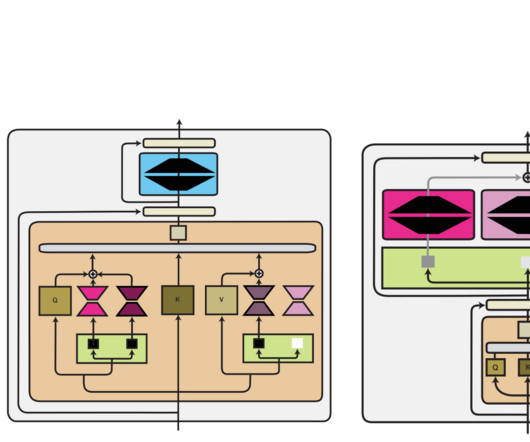



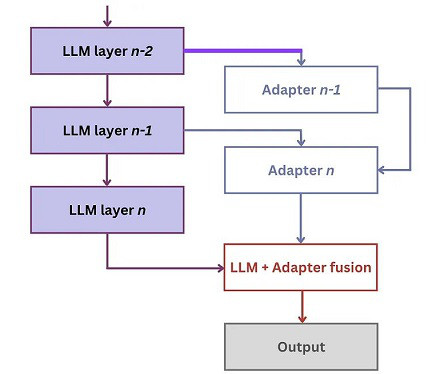











Let's personalize your content