This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
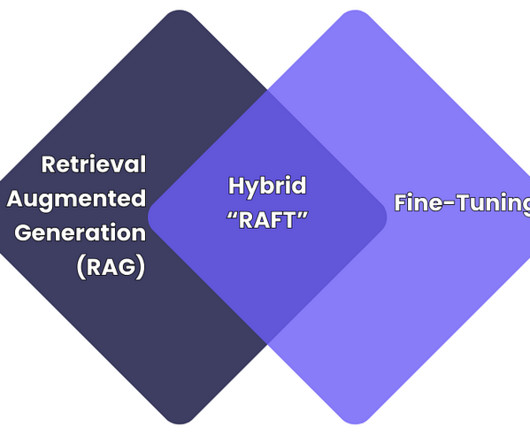
legal document review) It excels in tasks that require specialised terminologies or brand-specific responses but needs a lot of computational resources and may become obsolete with new data. Example: A customer support chatbot using RAG can fetch the real time policy from internal databases to answer the queries accurately.
Biased training data can lead to discriminatory outcomes, while datadrift can render models ineffective and labeling errors can lead to unreliable models. The readily available nature of open-source AI also raises security concerns; malicious actors could leverage the same tools to manipulate outcomes or create harmful content.
Baseline job datadrift: If the trained model passes the validation steps, baseline stats are generated for this trained model version to enable monitoring and the parallel branch steps are run to generate the baseline for the model quality check. Monitoring (datadrift) – The datadrift branch runs whenever there is a payload present.
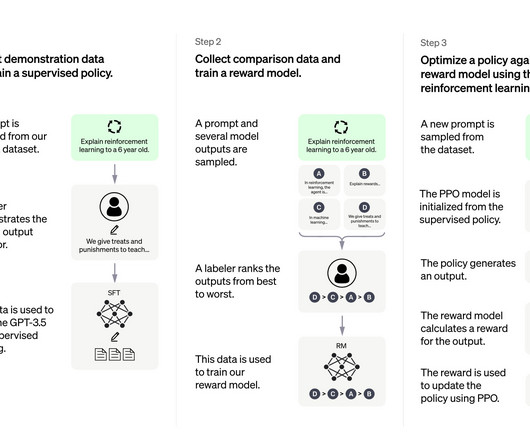
An excellent example is in the following where the chatbot helps the engineer to debug a problem. You can interact with the chatbot in the following website: [link] Some of the limitations are in the following: ChatGPT sometimes writes plausible-sounding but incorrect or nonsensical answers.
Monitoring Monitor model performance for datadrift and model degradation, often using automated monitoring tools. In applications like customer support chatbots, content generation, and complex task performance, prompt engineering techniques ensure LLMs understand the specific task at hand and respond accurately.
Adaptability over time To use Text2SQL in a durable way, you need to adapt to datadrift, i. the changing distribution of the data to which the model is applied. For example, let’s assume that the data used for initial fine-tuning reflects the simple querying behaviour of users when they start using the BI system.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











Let's personalize your content