This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Risks of training LLM models on sensitive data Large language models can be trained on proprietary data to fulfill specific enterprise use cases. For example, a company could take ChatGPT and create a private model that is trained on the company’s CRM sales data.
Managing and delivering data for AI Data is fundamental to AI, from building AI models with the right data sets to tuning AI models with industry-specific enterprise data to using vectorized embeddings to build RAG AI applications (including chatbots, personalized recommendation systems and image similarity search applications).
A chatbot for taking notes, an editor for creating images from text, and a tool for summarising customer comments can all be made with a basic understanding of programming and a couple of hours. Prototyping AI-driven systems has always been more complex. Zeno is made available to the public via a Python script.
One of the hardest things about MLOps today is that a lot of data scientists aren’t native software engineers, but it may be possible to lower the bar to software engineering. So data is really important for those still. Like not everybody needs a chatbot, not everybody needs to have autocomplete of text or something like that.
With a bit of programming knowledge and a couple of hours, you can spin up a chatbot for your notes , a text-based image editor , or a tool for summarizing customer feedback. While chatbot A might sound more human-like, a practitioner will deploy chatbot B if it produces concise and accurate answers that customers prefer.
A Streamlit application is hosted in Amazon Elastic Container Service (Amazon ECS) as a task, which provides a chatbot UI for users to submit queries against the knowledge base in Amazon Bedrock. The table only exists in the Data Catalog. This powerful solution opens up exciting possibilities for enterprise datadiscovery and insights.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



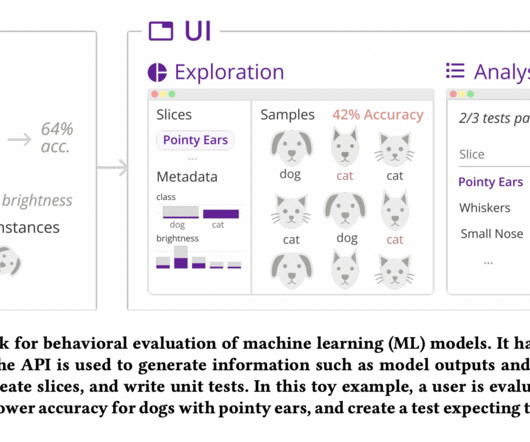

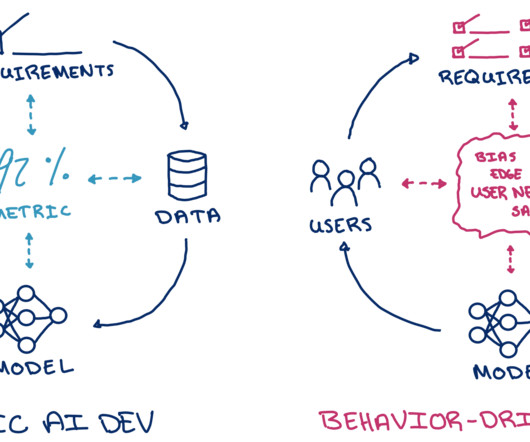







Let's personalize your content