This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. For a multiclass classification problem such as support case root cause categorization, this challenge compounds many fold.
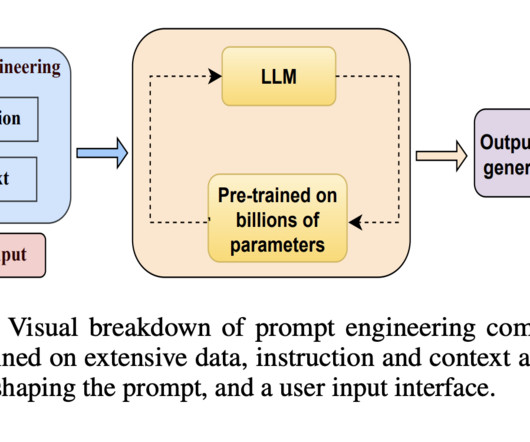
Promptengineering has burgeoned into a pivotal technique for augmenting the capabilities of large language models (LLMs) and vision-language models (VLMs), utilizing task-specific instructions or prompts to amplify model efficacy without altering core model parameters.
In this collaboration, the Generative AI Innovation Center team created an accurate and cost-efficient generative AIbased solution using batch inference in Amazon Bedrock , helping GoDaddy improve their existing product categorization system. Moreover, employing an LLM for individual product categorization proved to be a costly endeavor.
Customer sentiment analysis analyzes customer feedback, such as product reviews, chat transcripts, emails, and call center interactions, to categorize customers into happy, neutral, or unhappy. This categorization helps companies tailor their responses and strategies to enhance customer satisfaction.
Harnessing the full potential of AI requires mastering promptengineering. This article provides essential strategies for writing effective prompts relevant to your specific users. Let’s explore the tactics to follow these crucial principles of promptengineering and other best practices.
The authors categorize traceable artifacts, propose key features for observability platforms, and address challenges like decision complexity and regulatory compliance. Artifacts: Track intermediate outputs, memory states, and prompt templates to aid debugging.
Next, Amazon Comprehend or custom classifiers categorize them into types such as W2s, bank statements, and closing disclosures, while Amazon Textract extracts key details. With growing content libraries, media companies need efficient ways to categorize, search, and repurpose assets for production, distribution, and monetization.
The Three Pillars of the Product Alchemist To understand the evolution of a product manager, we can categorize their responsibilities into three distinct pillars: Ideation, Execution, and Alignment and Leading with Influence. This affects everything from ideation and execution to alignment with stakeholders and leading with influence.
The key to the capability of the solution is the prompts we have engineered to instruct Anthropics Claude what to do. PromptengineeringPromptengineering is the process of carefully designing the input prompts or instructions that are given to LLMs and other generative AI systems.
Lettrias in-house team manually assessed the answers with a detailed evaluation grid, categorizing results as correct, partially correct (acceptable or not), or incorrect. Results are then used to augment the prompt and generate a more accurate response compared to standard vector-based RAG.
Users can review different types of events such as security, connectivity, system, and management, each categorized by specific criteria like threat protection, LAN monitoring, and firmware updates. For our specific task, weve found promptengineering sufficient to achieve the results we needed.
Manually analyzing and categorizing large volumes of unstructured data, such as reviews, comments, and emails, is a time-consuming process prone to inconsistencies and subjectivity. Operational efficiency Uses promptengineering, reducing the need for extensive fine-tuning when new categories are introduced.
To install and import the library, use the following commands: pip install -q transformers from transformers import pipeline Having done that, you can execute NLP tasks starting with sentiment analysis, which categorizes text into positive or negative sentiments.
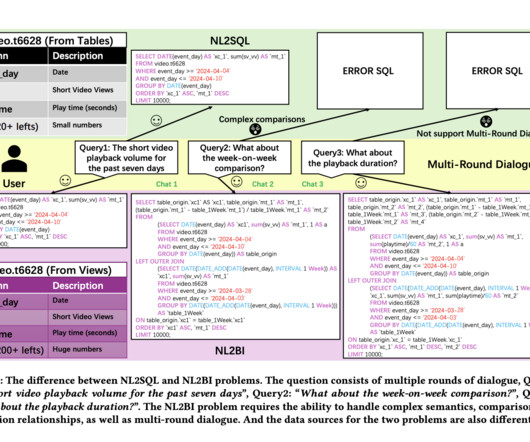
Researchers have primarily focused on enhancing NL2SQL methods, which can be categorized into pre-trained and Supervised Fine-Tuning (SFT) methods, promptengineering-based LLMs, and LLMs specifically trained for NL2SQL. The researchers propose novel solutions tailored to the NL2BI scenario to address these challenges.
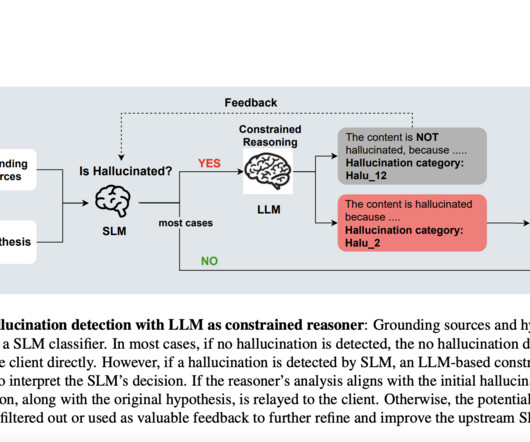
This includes careful promptengineering for the LLM and potential feedback loops where the LLM’s explanations can be used to refine the SLM’s detection criteria over time. The experimental results demonstrate the effectiveness of the proposed hallucination detection framework, particularly the Categorized approach.
Fine-tuning Anthropic’s Claude 3 Haiku has demonstrated superior performance compared to few-shot promptengineering on base Anthropic’s Claude 3 Haiku, Anthropic’s Claude 3 Sonnet, and Anthropic’s Claude 3.5 Sonnet across various tasks.
Information Retrieval: Using LLMs, such as BERT or GPT, as part of larger architectures to develop systems that can fetch and categorize information. This recent post demystifies Midjourney in a detailed guide, elucidating both the platform and its promptengineering intricacies.
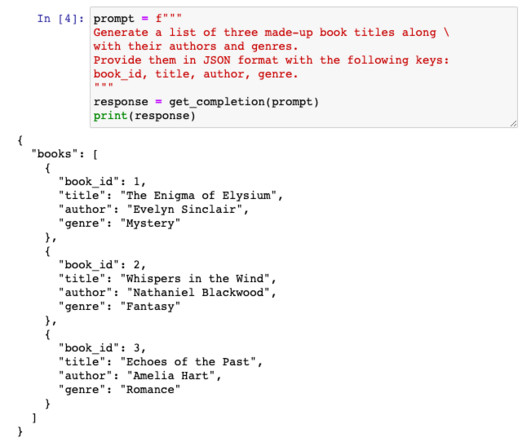
This post walks through examples of building information extraction use cases by combining LLMs with promptengineering and frameworks such as LangChain. PromptengineeringPromptengineering enables you to instruct LLMs to generate suggestions, explanations, or completions of text in an interactive way.
As the paper demonstrated, promptengineering allows creating training data for hundreds of thousands of embedding tasks. Yet, current prompt design practices remain more an art than science. However, critical research directions remain to translate this potential into real-world impact.
Software engineers have shown reluctance to use LLMs for higher-level design tasks due to concerns about complex requirement comprehension. Despite this, LLMs’ use in requirement engineering has gradually increased, driven by advancements in contextual analysis and reasoning through promptengineering and Chain-of-Thought techniques.
IE tasks compel models to discern and categorize text in formats that align with predefined structures, such as named entity recognition and relation classification. However, existing LLMs typically falter when tasked with the nuanced understanding and alignment necessary for effective IE.
For instance, in ecommerce, image-to-text can automate product categorization based on images, enhancing search efficiency and accuracy. With millions of products listed, effective sorting and categorization poses a significant challenge. This is where the power of auto-tagging and attribute generation comes into its own.
Machine translation, summarization, ticket categorization, and spell-checking are among the examples. Prompts design is a process of creating prompts which are the instructions and context that are given to Large Language Models to achieve the desired task. What are large language models used for?
Document categorization or classification has significant benefits across business domains – Improved search and retrieval – By categorizing documents into relevant topics or categories, it makes it much easier for users to search and retrieve the documents they need. They can search within specific categories to narrow down results.
Some components are categorized in groups based on the type of functionality they exhibit. Prompt catalog – Crafting effective prompts is important for guiding large language models (LLMs) to generate the desired outputs. Having a centralized prompt catalog is essential for storing, versioning, tracking, and sharing prompts.
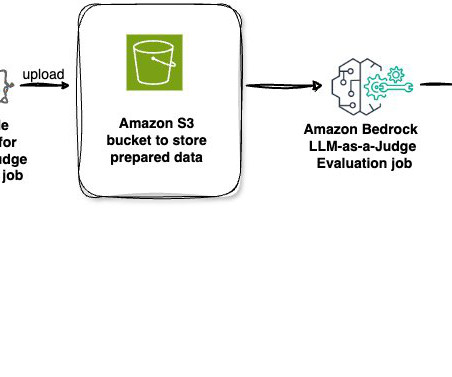
Curated judge models : Amazon Bedrock provides pre-selected, high-quality evaluation models with optimized promptengineering for accurate assessments. Users dont need to bring external judge models, because the Amazon Bedrock team maintains and updates a selection of judge models and associated evaluation judge prompts.
link] The process can be categorized into three agents: Execution Agent : The heart of the system, this agent leverages OpenAI’s API for task processing. Given an objective and a task, it prompts OpenAI's API and retrieves task outcomes.
Current methods to limit these LLM vulnerabilities include adversarial testing, red-teaming exercises, and manual promptengineering. The identified vulnerabilities are categorized based on their impact, severity, and potential exploitability, providing a structured approach to addressing risks.
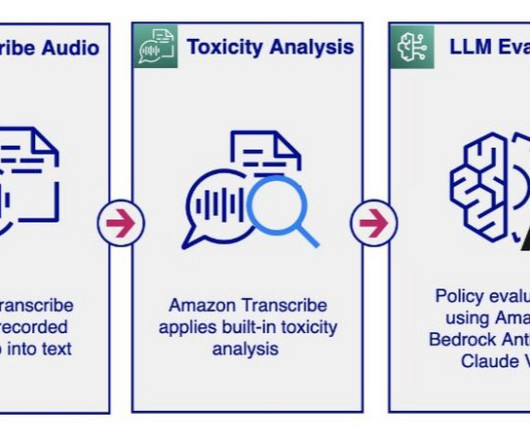
Use LLM promptengineering to accommodate customized policies The pre-trained Toxicity Detection models from Amazon Transcribe and Amazon Comprehend provide a broad toxicity taxonomy, commonly used by social platforms for moderating user-generated content in audio and text formats.
Taxonomy of Hallucination Mitigation Techniques Researchers have introduced diverse techniques to combat hallucinations in LLMs, which can be categorized into: 1. PromptEngineering This involves carefully crafting prompts to provide context and guide the LLM towards factual, grounded responses.
These sources can be categorized into three types: textual documents (e.g., Techniques like Uprise and DaSLaM use lightweight retrievers or small models to optimize prompts, break down complex problems, or generate pseudo labels. KD methods can be categorized into white-box and black-box approaches.
Types of summarizations There are several techniques to summarize text, which are broadly categorized into two main approaches: extractive and abstractive summarization. Given their versatile nature, these models require specific task instructions provided through input text, a practice referred to as promptengineering.
Verisk’s evaluation involved three major parts: Promptengineering – Promptengineering is the process where you guide generative AI solutions to generate desired output. Verisk framed prompts using their in-house clinical experts’ knowledge on medical claims.
Operationalization journey per generative AI user type To simplify the description of the processes, we need to categorize the main generative AI user types, as shown in the following figure. Strong domain knowledge for tuning, including promptengineering, is required as well. We will cover monitoring in a separate post.
When a new document type introduced in the IDP pipeline needs classification, the LLM can process text and categorize the document given a set of classes. For example, we can follow promptengineering best practices to fine-tune an LLM to format dates into MM/DD/YYYY format, which may be compatible with a database DATE column.
In this article, we will delve deeper into these issues, exploring the advanced techniques of promptengineering with Langchain, offering clear explanations, practical examples, and step-by-step instructions on how to implement them. Prompts play a crucial role in steering the behavior of a model.
It allows you to retrieve data from sources beyond the foundation model, enhancing prompts by integrating contextually relevant retrieved data. You can use promptengineering to prevent hallucination and make sure that the answer is grounded in the source documentations.
OpenAI Announces DALL·E 3 OpenAI is launching DALL·E 3, an improved version that excels in following instructions, requires less promptengineering, and can communicate with ChatGPT. This integration enables users to refine DALL·E 3 prompts by describing their ideas to ChatGPT. Five 5-minute reads/videos to keep you learning 1.Adept.ai
We have categorized them to make it easier to cover maximum tools. Built on ChatGPT, this version enhances user-friendliness by eliminating the need for complex promptengineering. Operating based on natural language inputs or prompts, the model generates accurate images corresponding to the provided descriptions.
LARs are a type of embedding that can be used to represent high-dimensional categorical data in a lower-dimensional continuous space. Promptengineering aims to solve these problems, but comes with a steep learning curve and increased fragility as the prompt increases in size.
The Send your feedback form provides the user the option to categorize the feedback and provide additional details for the administrator to review. For example, consider if a user asks about their vacation policy and no answer is returned. The user can then choose the thumbs down icon and send feedback to the administrator.
In-context learning, promptengineering, and model invocation We use in-context learning to be able to use a foundation model to accomplish this task. In-context learning is the ability for LLMs to learn the task using just what’s in the prompt without being pre-trained or fine-tuned for the particular task. and 1.0.
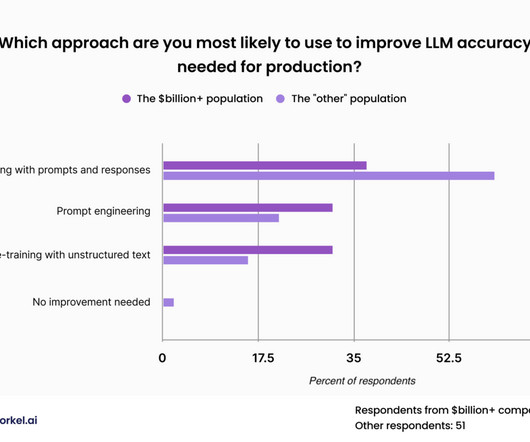
This approach was less popular among our attendees from the wealthiest of corporations, who expressed similar levels of interest in fine-tuning with prompts and responses, fine-tuning with unstructured data, and promptengineering.
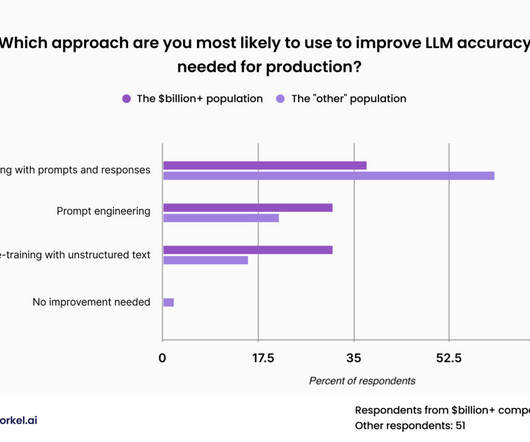
This approach was less popular among our attendees from the wealthiest of corporations, who expressed similar levels of interest in fine-tuning with prompts and responses, fine-tuning with unstructured data, and promptengineering.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content