This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
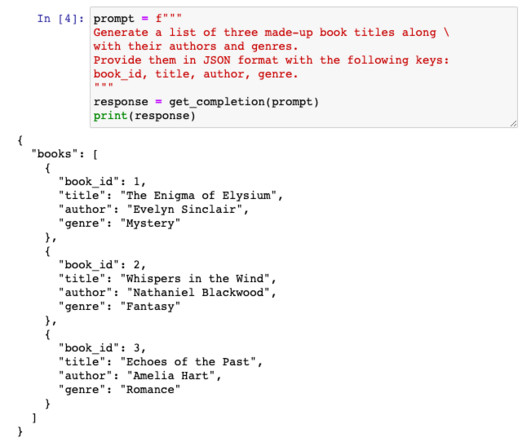
Harnessing the full potential of AI requires mastering promptengineering. This article provides essential strategies for writing effective prompts relevant to your specific users. Let’s explore the tactics to follow these crucial principles of promptengineering and other best practices.
Lettrias in-house team manually assessed the answers with a detailed evaluation grid, categorizing results as correct, partially correct (acceptable or not), or incorrect. Results are then used to augment the prompt and generate a more accurate response compared to standard vector-based RAG.
Users can review different types of events such as security, connectivity, system, and management, each categorized by specific criteria like threat protection, LAN monitoring, and firmware updates. For our specific task, weve found promptengineering sufficient to achieve the results we needed.
Manually analyzing and categorizing large volumes of unstructured data, such as reviews, comments, and emails, is a time-consuming process prone to inconsistencies and subjectivity. Operational efficiency Uses promptengineering, reducing the need for extensive fine-tuning when new categories are introduced.
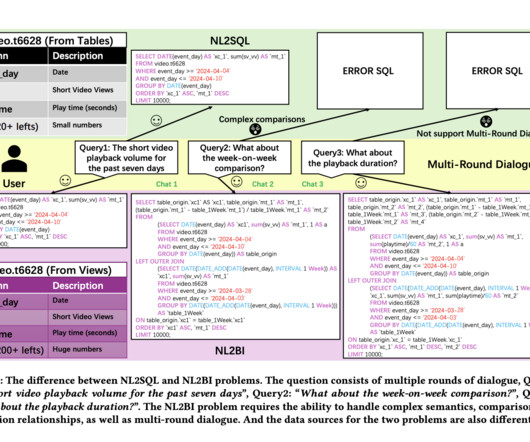
Both the Natural Language Processing (NLP) and database communities are exploring the potential of LLMs in tackling the Natural Language to SQL NL2SQL task, which involves converting natural language queries into executable SQL statements consistent with user intent.
With advancements in deep learning, natural language processing (NLP), and AI, we are in a time period where AI agents could form a significant portion of the global workforce. Transformers and Advanced NLP Models : The introduction of transformer architectures revolutionized the NLP landscape.
They serve as a core building block in many natural language processing (NLP) applications today, including information retrieval, question answering, semantic search and more. With further research intoprompt engineering and synthetic data quality, this methodology could greatly advance multilingual text embeddings.
Fine-tuning is a powerful approach in natural language processing (NLP) and generative AI , allowing businesses to tailor pre-trained large language models (LLMs) for specific tasks. This process involves updating the model’s weights to improve its performance on targeted applications. Sonnet across various tasks.
Natural Language Processing (NLP) is a subfield of artificial intelligence. Machine translation, summarization, ticket categorization, and spell-checking are among the examples. Prompts design is a process of creating prompts which are the instructions and context that are given to Large Language Models to achieve the desired task.
This post walks through examples of building information extraction use cases by combining LLMs with promptengineering and frameworks such as LangChain. PromptengineeringPromptengineering enables you to instruct LLMs to generate suggestions, explanations, or completions of text in an interactive way.
For instance, in ecommerce, image-to-text can automate product categorization based on images, enhancing search efficiency and accuracy. With millions of products listed, effective sorting and categorization poses a significant challenge. This is where the power of auto-tagging and attribute generation comes into its own.
Amazon Comprehend is a natural-language processing (NLP) service that uses machine learning to uncover valuable insights and connections in text. Knowledge management – Categorizing documents in a systematic way helps to organize an organization’s knowledge base. Amazon Comprehend custom classification can be useful in this situation.
But if you’re working on the same sort of Natural Language Processing (NLP) problems that businesses have been trying to solve for a long time, what’s the best way to use them? We want to aggregate it, link it, filter it, categorize it, generate it and correct it. We want to recommend people text based on other text they liked.
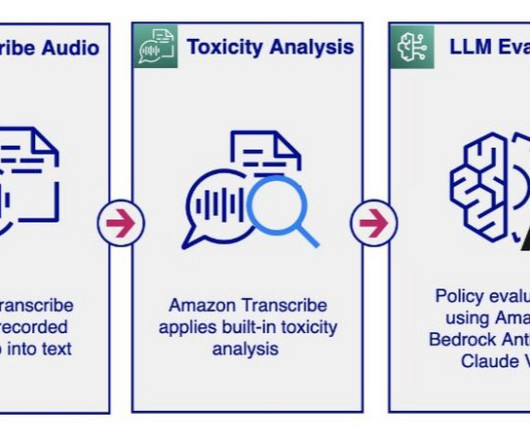
Use LLM promptengineering to accommodate customized policies The pre-trained Toxicity Detection models from Amazon Transcribe and Amazon Comprehend provide a broad toxicity taxonomy, commonly used by social platforms for moderating user-generated content in audio and text formats.
Amazon Comprehend is a natural language processing (NLP) service that uses ML to extract insights from text. When a new document type introduced in the IDP pipeline needs classification, the LLM can process text and categorize the document given a set of classes. You can also fine-tune them for specific document classes.
Operationalization journey per generative AI user type To simplify the description of the processes, we need to categorize the main generative AI user types, as shown in the following figure. They have deep end-to-end ML and natural language processing (NLP) expertise and data science skills, and massive data labeler and editor teams.
In this article, we will delve deeper into these issues, exploring the advanced techniques of promptengineering with Langchain, offering clear explanations, practical examples, and step-by-step instructions on how to implement them. Prompts play a crucial role in steering the behavior of a model.
The core idea behind this phase is automating the categorization or classification using AI. We use Amazon Textract’s document extraction abilities with LangChain to get the text from the document and then use promptengineering to identify the possible document category.
Natural Language Processing (NLP) has emerged as a dominant area, with tasks like sentiment analysis, machine translation, and chatbot development leading the way. Classification techniques, such as image recognition and document categorization, remain essential for a wide range of industries.
The custom metadata helps organizations and enterprises categorize information in their preferred way. His focus area is AI/ML, and he helps customers with generative AI, large language models, and promptengineering. For example, metadata can be used for filtering and searching.
Users can easily constrain an LLM’s output with clever promptengineering. That minimizes the chance that the prompt will overrun the context window, and also reduces the cost of high-volume runs. Its categorical power is brittle. The former will make the generative model’s outputs (mostly) fall into an expected range.
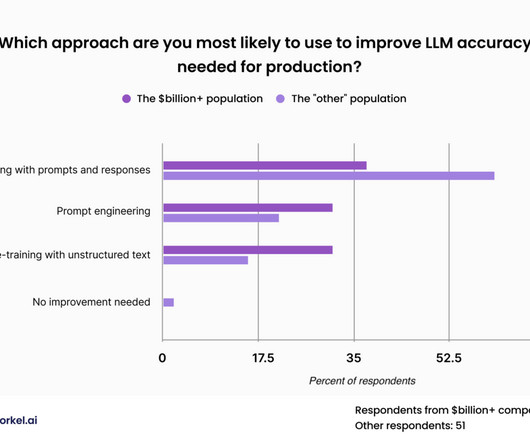
This approach was less popular among our attendees from the wealthiest of corporations, who expressed similar levels of interest in fine-tuning with prompts and responses, fine-tuning with unstructured data, and promptengineering.
Broad Streams of LLM Applications Though LLM applications are vast, we can broadly categorize the LLM applications into the following streams: PromptEngineering: This is the most basic and widely applicable one. Here, we primarily work with proprietary LLMs such as ChatGPT.
At its debut, BERT shattered the records for a suite of NLP benchmark tests. Within a short time, BERT became the standard tool for NLP tasks. From 2018 to the modern day, NLP researchers have engaged in a steady march toward ever-larger models. This is generally known as “prompt programming” or “promptengineering.”
At its debut, BERT shattered the records for a suite of NLP benchmark tests. Within a short time, BERT became the standard tool for NLP tasks. From 2018 to the modern day, NLP researchers have engaged in a steady march toward ever-larger models. This is generally known as “prompt programming” or “promptengineering.”
In short, EDS is the problem of the widespread lack of a rational approach to and methodology for the objective, automated and quantitative evaluation of performance in terms of generative model finetuning and promptengineering for specific downstream GenAI tasks related to practical business applications. There is a ‘but’, however.
In the image above, you can see on the left that categorical “overlap” is sometimes intentional. Many organizations pursue model-centric iteration, such as hyper-parameter tuning and promptengineering. During task formulation, the customer wanted to use an existing taxonomy for categorizing and labeling videos.
Transformers in NLP In 2017, Cornell University published an influential paper that introduced transformers. These are deep learning models used in NLP. Hugging Face , started in 2016, aims to make NLP models accessible to everyone. This discovery fueled the development of large language models like ChatGPT.
LaMDA Google 173 billion Not Open Source, No API or Download Trained on dialogue could learn to talk about virtually anything MT-NLG Nvidia/Microsoft 530 billion API Access by application Utilizes transformer-based Megatron architecture for various NLP tasks. How Are LLMs Used? However, relying on a single attention mechanism can be limiting.
Types of summarizations There are several techniques to summarize text, which are broadly categorized into two main approaches: extractive and abstractive summarization. Extractive summarization Extractive summarization is a technique used in NLP and text analysis to create a summary by extracting key sentences.
Key strengths of VLP include the effective utilization of pre-trained VLMs and LLMs, enabling zero-shot or few-shot predictions without necessitating task-specific modifications, and categorizing images from a broad spectrum through casual multi-round dialogues.
Led by Dwayne Natwick , CEO of Captain Hyperscaler, LLC, and a Microsoft Certified Trainer (MCT) Regional Lead & Microsoft Most Valuable Professional (MVP) , these sessions will provide practical insights and hands-on experience in promptengineering and generative AI development.
Traditional NLP pipelines and ML classification models Traditional natural language processing pipelines struggle with email complexity due to their reliance on rigid rules and poor handling of language variations, making them impractical for dynamic client communications. However, not all of them were effective for Parameta.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content