This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Overview Setting up John Snow labs Spark-NLP on AWS EMR and using the library to perform a simple text categorization of BBC articles. The post Build Text Categorization Model with Spark NLP appeared first on Analytics Vidhya. Introduction.
NaturalLanguageProcessing (NLP) is integral to artificial intelligence, enabling seamless communication between humans and computers. This interdisciplinary field incorporates linguistics, computer science, and mathematics, facilitating automatic translation, text categorization, and sentiment analysis.
They combine advanced speech recognition, naturallanguageprocessing, and conversation analytics to turn routine meetings into searchable data that drives better business outcomes. These models identify different speakers, handle multiple accents and languages, and maintain high accuracy even with technical terminology.
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. For a multiclass classification problem such as support case root cause categorization, this challenge compounds many fold.
NaturalLanguageProcessing (NLP) is a rapidly growing field that deals with the interaction between computers and human language. Transformers is a state-of-the-art library developed by Hugging Face that provides pre-trained models and tools for a wide range of naturallanguageprocessing (NLP) tasks.
Voice intelligence combines speech recognition, naturallanguageprocessing, and machine learning to turn voice data into actionable insights. NaturalLanguageProcessing (NLP) Once speech becomes text, naturallanguageprocessing, or NLP, models analyze the actual meaning.
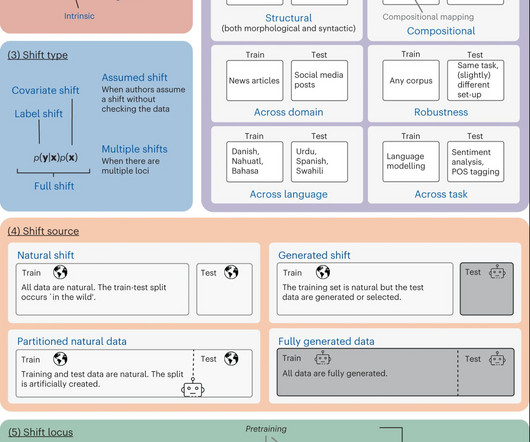
A model’s capacity to generalize or effectively apply its learned knowledge to new contexts is essential to the ongoing success of NaturalLanguageProcessing (NLP). Main Motivation: Studies are categorized along this axis according to their main goals or driving forces. Check out the Paper.
In addition, AI efficiently categorizes threats by assessing their potential severity, impact and damage. These chatbots have naturallanguageprocessing algorithms that allow them to read, interpret and comprehend languages. This will trigger the incident response team to jump in and protect coverage.
Through these wordclouds, we can see which areas the airline should look into and review their processes on. Topic modelling is a type of statistical modelling in NaturalLanguageProcessing to identify topics among a collection of documents. Moving on to topic modelling. The new distribution will be equal as such.
These innovative platforms combine advanced AI and naturallanguageprocessing (NLP) with practical features to help brands succeed in digital marketing, offering everything from real-time safety monitoring to sophisticated creator verification systems.
Plus, naturallanguageprocessing (NLP) and AI-driven search capabilities help businesses better understand user intent, enabling them to optimize product descriptions and attributes to match how customers actually search. to create those tailored product recommendations.
Overview Presenting 11 data science videos that will enhance and expand your current skillset We have categorized these videos into three fields – Natural. The post 11 Superb Data Science Videos Every Data Scientist Must Watch appeared first on Analytics Vidhya.
Each stone needs to be carefully examined, categorized and placed in the correct bucket, which takes about five minutes per stone. Streamlining government regulatory responses with naturallanguageprocessing, GenAI and text analytics was published on SAS Voices by Tom Sabo Fortunately, you’re not alone but part of [.]
Customer Service and Support Speech AI technology provides more accurate, insightful call analysis by automatically categorizing, summarizing, and extracting actionable insights from customer calls—such as flagging questions and complaints.
Users can set up custom streams to monitor keywords, hashtags, and mentions in real-time, while the platform's AI-powered sentiment analysis automatically categorizes mentions as positive, negative, or neutral, providing a clear gauge of public perception.
Based on this, it makes an educated guess about the importance of incoming emails, and categorizes them into specific folders. In addition to the smart categorization of emails, SaneBox also comes with a feature named SaneBlackHole, designed to banish unwanted emails.
This article explores an innovative way to streamline the estimation of Scope 3 GHG emissions leveraging AI and Large Language Models (LLMs) to help categorize financial transaction data to align with spend-based emissions factors. Why are Scope 3 emissions difficult to calculate? This is where LLMs come into play.
King’s College London researchers have highlighted the importance of developing a theoretical understanding of why transformer architectures, such as those used in models like ChatGPT, have succeeded in naturallanguageprocessing tasks.
Lettrias in-house team manually assessed the answers with a detailed evaluation grid, categorizing results as correct, partially correct (acceptable or not), or incorrect. An example multi-hop query in finance is Compare the oldest booked Amazon revenue to the most recent.
We have used machine learning models and naturallanguageprocessing (NLP) to train and identify distress signals. We have categorized the posts into two main categories– those seeking help and those that do not.
Sentiment analysis to categorize mentions as positive, negative, or neutral. It uses naturallanguageprocessing (NLP) algorithms to understand the context of conversations, meaning it's not just picking up random mentions! Clean and intuitive user interface that's easy to navigate. Easy reporting functionality.
AI algorithms can categorize emails more effectively than traditional filters, prioritizing important messages and reducing the clutter of less relevant ones. The Complexity of Contextual Understanding Despite advancements in naturallanguageprocessing, AI still struggles with understanding the nuances and context of human language fully.
With its intelligent search capabilities and advanced naturallanguageprocessing, Elicit helps researchers quickly identify the most relevant papers and understand their core ideas through automatically generated summaries.
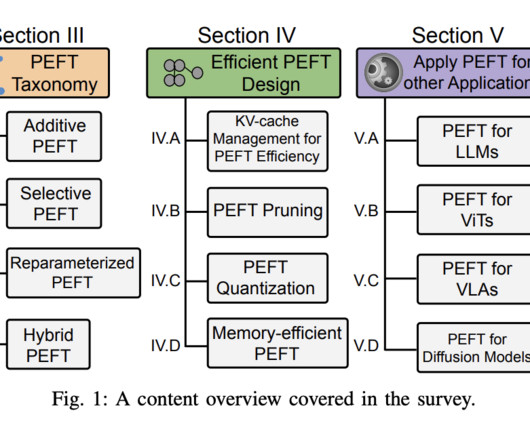
PEFT’s applicability extends beyond NaturalLanguageProcessing (NLP) to computer vision (CV), garnering interest in fine-tuning large-parameter vision models like Vision Transformers (ViT) and diffusion models, as well as interdisciplinary vision-language models.
Types of AI in ITSM AI in ITSM can be categorized into three types: automation, chatbots, and predictive analysis. Modern AI chatbots are equipped with NaturalLanguageProcessing ( NLP ) to understand and respond to user queries in a more human-like manner. Let's look into these more closely in the following sections.
And retailers frequently leverage data from chatbots and virtual assistants, in concert with ML and naturallanguageprocessing (NLP) technology, to automate users’ shopping experiences. Regression algorithms —predict output values by identifying linear relationships between real or continuous values (e.g.,
Next, Amazon Comprehend or custom classifiers categorize them into types such as W2s, bank statements, and closing disclosures, while Amazon Textract extracts key details. Additional processing is needed to standardize formats, manage JSON outputs, and align data fields, often requiring manual integration and multiple API calls.
Users can review different types of events such as security, connectivity, system, and management, each categorized by specific criteria like threat protection, LAN monitoring, and firmware updates. Presently, his main area of focus is state-of-the-art naturallanguageprocessing. 2024-10-{01/00:00:00--02/00:00:00}.
In computer vision, convolutional networks acquire a semantic understanding of images through extensive labeling provided by experts, such as delineating object boundaries in datasets like COCO or categorizing images in ImageNet. This approach has demonstrated effectiveness in naturallanguageprocessing and reinforcement learning.
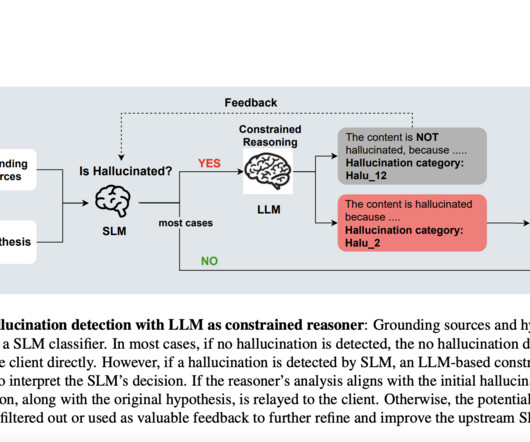
Large Language Models (LLMs) have demonstrated remarkable capabilities in various naturallanguageprocessing tasks. Categorized: Refines the flagging mechanism by incorporating granular hallucination categories, including a specific category (hallu12) to signal inconsistencies where the text is not a hallucination.
Consequently, there’s been a notable uptick in research within the naturallanguageprocessing (NLP) community, specifically targeting interpretability in language models, yielding fresh insights into their internal operations. Recent approaches automate circuit discovery, enhancing interpretability.
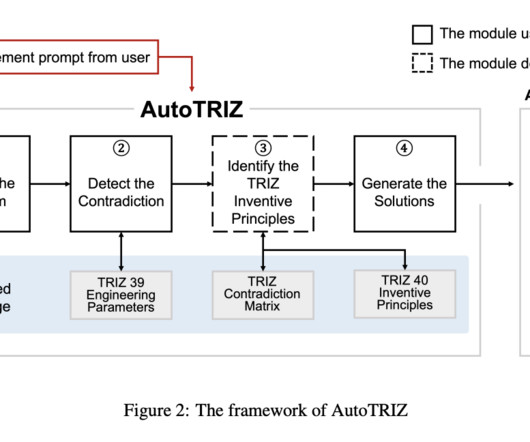
Recent advancements integrate machine learning and naturallanguageprocessing with TRIZ to streamline its reasoning process. AutoTRIZ emphasizes controlling the problem-solving process while drawing problem-related knowledge from the pre-trained large-scale corpora used to train the LLM.
Manually analyzing and categorizing large volumes of unstructured data, such as reviews, comments, and emails, is a time-consuming process prone to inconsistencies and subjectivity. Businesses can use LLMs to gain valuable insights, streamline processes, and deliver enhanced customer experiences. No explanation is required.
The abundance of web-scale textual data available has been a major factor in the development of generative language models, such as those pretrained as multi-purpose foundation models and tailored for particular NaturalLanguageProcessing (NLP) tasks.
It uses naturallanguageprocessing to identify and organize discussion points, decisions, and future tasks. It automatically categorizes, summarizes, and extracts actionable insights from customer calls, such as flagging questions and complaints. Fireflies.ai
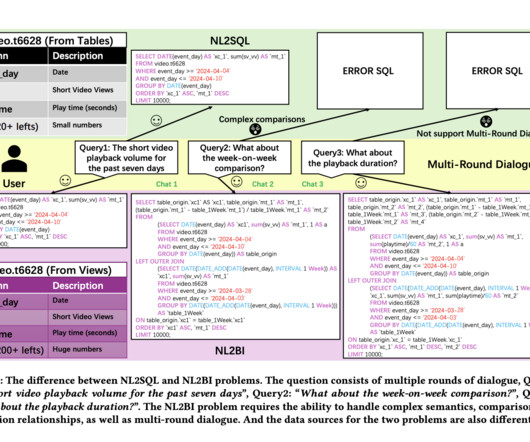
The rapid advancement of Large Language Models (LLMs) has sparked interest among researchers in academia and industry alike. Moreover, differences in data table structures between BI and traditional SQL contexts further complicate the translation process.
In NaturalLanguageProcessing (NLP) tasks, data cleaning is an essential step before tokenization, particularly when working with text data that contains unusual word separations such as underscores, slashes, or other symbols in place of spaces.
In a nutshell, Algolia NeuralSearch integrates keyword matching with vector-based naturallanguageprocessing , powered by LLMs, in a single API – an industry first. In September 2022, Search.io Moreover, Adaptive Learning based on user feedback fine-tunes intent understanding.
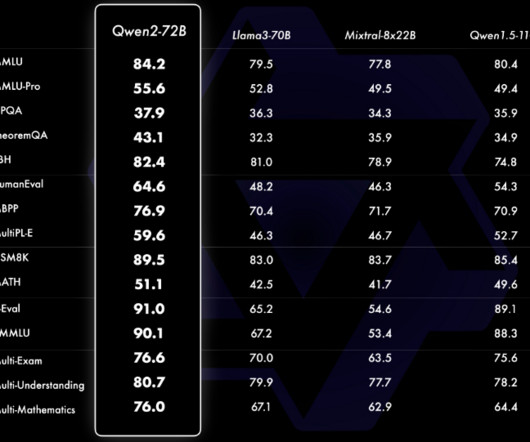
This multilingual training regimen includes languages from diverse regions such as Western Europe, Eastern and Central Europe, the Middle East , Eastern Asia and Southern Asia. By effectively processing extended contexts, Qwen2 can provide more accurate and comprehensive responses, unlocking new frontiers in naturallanguageprocessing.
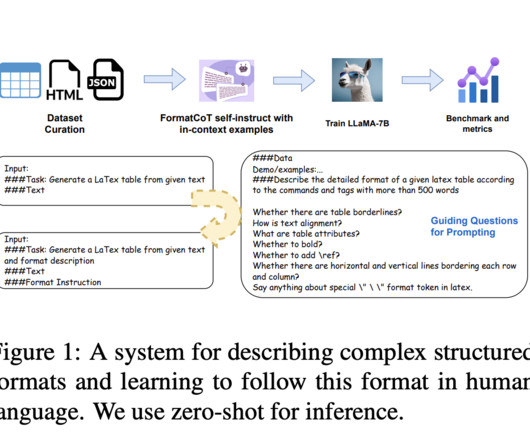
Developing and refining Large Language Models (LLMs) has become a focal point of cutting-edge research in the rapidly evolving field of artificial intelligence, particularly in naturallanguageprocessing. A significant innovation in this domain is creating a specialized tool to refine the dataset compilation process.
These platforms combine AI speech recognition, naturallanguageprocessing, and machine learning to analyze every customer conversation automatically. What is conversation intelligence? Conversation intelligence turns customer interactions into actionable business insights.
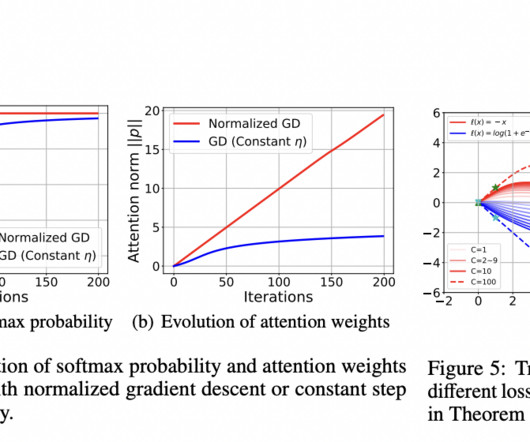
The attention mechanism has played a significant role in naturallanguageprocessing and large language models. The researchers emphasized that transformers utilize an old-school method similar to support vector machines (SVM) to categorize data into relevant and non-relevant information. Check out the Paper.
Photo by Shubham Dhage on Unsplash Introduction Large language Models (LLMs) are a subset of Deep Learning. Image by YouTube video “Introduction to large language models” on YouTube Channel “Google Cloud Tech” What are Large Language Models? NaturalLanguageProcessing (NLP) is a subfield of artificial intelligence.
Large Language Models (LLMs) have made significant progress in text creation tasks, among other naturallanguageprocessing tasks. Existing benchmarks frequently use simple objective metrics like word overlap to gauge how well the content produced by the machine is categorizing information.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content