This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In a groundbreaking study published in Communications Biology, neuroscientists at the University of Pittsburgh have developed a machine-learning model that sheds light on how brains recognize and categorize different sounds.
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. This use case, solvable through ML, can enable support teams to better understand customer needs and optimize response strategies.
The points to cover in this article are as follows: Generating synthetic data to illustrate ML modelling for election outcomes. Model Fitting and Training: Various ML models trained on sub-patterns in data. We’ll use one-hot encoding to capture categorical distinctions effectively.
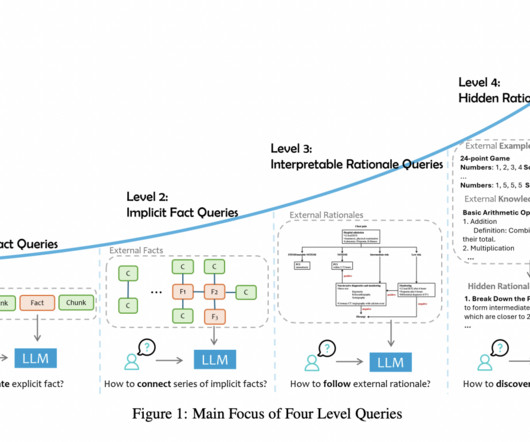
Researchers at Microsoft Research Asia introduced a novel method that categorizes user queries into four distinct levels based on the complexity and type of external data required. The categorization helps tailor the model’s approach to retrieving and processing data, ensuring it selects the most relevant information for a given task.
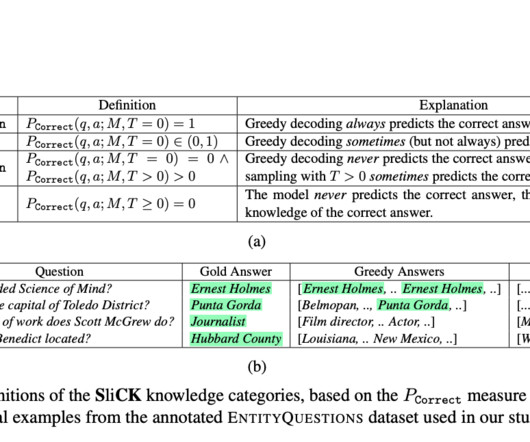
This methodology stands out by categorizing knowledge into distinct levels, ranging from HighlyKnown to Unknown, providing a granular analysis of how different types of information affect model performance. The study’s findings demonstrate the effectiveness of the SliCK categorization in enhancing the fine-tuning process.
However, with the help of AI and machine learning (ML), new software tools are now available to unearth the value of unstructured data. Additionally, we show how to use AWS AI/ML services for analyzing unstructured data. Understanding the data, categorizing it, storing it, and extracting insights from it can be challenging.
Sharing in-house resources with other internal teams, the Ranking team machine learning (ML) scientists often encountered long wait times to access resources for model training and experimentation – challenging their ability to rapidly experiment and innovate. If it shows online improvement, it can be deployed to all the users.
It often requires managing multiple machine learning (ML) models, designing complex workflows, and integrating diverse data sources into production-ready formats. Next, Amazon Comprehend or custom classifiers categorize them into types such as W2s, bank statements, and closing disclosures, while Amazon Textract extracts key details.
This system, the first Gym environment for ML tasks, facilitates the study of RL techniques for training AI agents. A six-level framework categorizes AI research agent capabilities, with MLGym-Bench focusing on Level 1: Baseline Improvement, where LLMs optimize models but lack scientific contributions.
Machine learning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computer vision , large language models (LLMs), speech recognition, self-driving cars and more. However, the growing influence of ML isn’t without complications.
With over 50 connectors, an intuitive Chat for data prep interface, and petabyte support, SageMaker Canvas provides a scalable, low-code/no-code (LCNC) ML solution for handling real-world, enterprise use cases. Afterward, you need to manage complex clusters to process and train your ML models over these large-scale datasets.
This article explores an innovative way to streamline the estimation of Scope 3 GHG emissions leveraging AI and Large Language Models (LLMs) to help categorize financial transaction data to align with spend-based emissions factors. Why are Scope 3 emissions difficult to calculate?
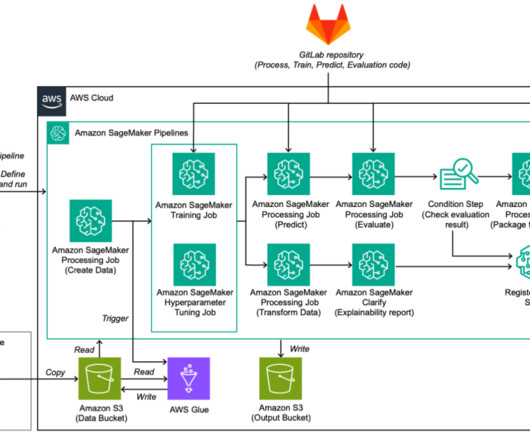
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
They focused on improving customer service using data with artificial intelligence (AI) and ML and saw positive results, with their Group AI Maturity increasing from 50% to 80%, according to the TM Forum’s AI Maturity Index. If there are features related to network issues, those users are categorized as network issue-based users.
They use real-time data and machine learning (ML) to offer customized loans that fuel sustainable growth and solve the challenges of accessing capital. It needed to intelligently categorize transactions based on their descriptions and other contextual factors about the business to ensure they are mapped to the appropriate classification.
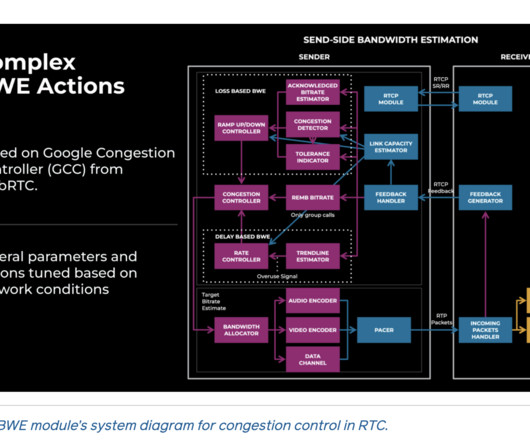
Researchers from Meta developed a machine learning (ML)-based approach to address the challenges of optimizing bandwidth estimation (BWE) and congestion control for real-time communication (RTC) across Meta’s family of apps. Meta’s ML-based approach involves two main components: offline ML model learning and parameter tuning.
That’s why today’s application analytics platforms rely on artificial intelligence (AI) and machine learning (ML) technology to sift through big data, provide valuable business insights and deliver superior data observability. AI- and ML-generated SaaS analytics enhance: 1. What are application analytics?
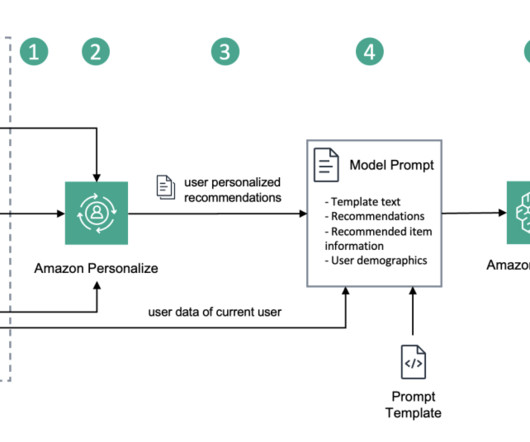
You can get started without any prior machine learning (ML) experience, and Amazon Personalize allows you to use APIs to build sophisticated personalization capabilities. For this example, we use the ml-latest-small dataset from the MovieLens dataset to simulate user-item interactions.
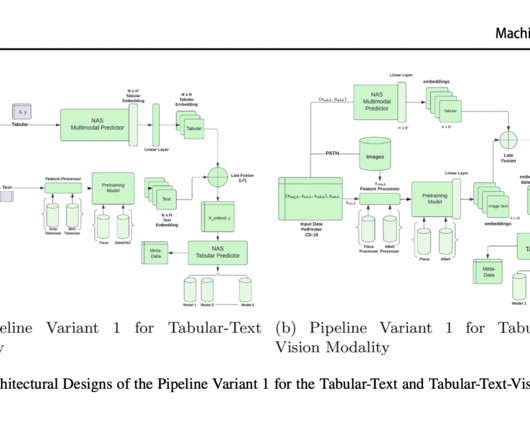
An improvement in AutoML for dealing with complicated data modalities, including tabular-text, text-vision, and vision-text-tabular configurations, the proposed method simplifies and guarantees the efficiency and adaptability of multimodal ML pipelines. The Sequential Model-Based Optimization (SMBO) approach uses it as a search space.
In this sense, it is an example of artificial intelligence that is, teaching computers to see in the same way as people do, namely by identifying and categorizing objects based on semantic categories. Another method for figuring out which category a detected object belongs to is object categorization.
This tagging structure categorizes costs and allows assessment of usage against budgets. ListTagsForResource : Fetches the tags associated with a specific Bedrock resource, helping users understand how their resources are categorized. At its core, the Amazon Bedrock resource tagging system spans multiple operational components.
Beginner’s Guide to ML-001: Introducing the Wonderful World of Machine Learning: An Introduction Everyone is using mobile or web applications which are based on one or other machine learning algorithms. Machine learning(ML) is evolving at a very fast pace. Machine learning(ML) is evolving at a very fast pace.
Fourteen behaviors were analyzed and categorized as self-referential (personhood claims, physical embodiment claims, and internal state expressions ) and relational (relationship-building behaviors). Also,feel free to follow us on Twitter and dont forget to join our 75k+ ML SubReddit. Check out the Paper.
The results produced through OpenCLIP provide label probabilities that indicate how relevant a given image or text input is to specific product labels, aiding in the accurate categorization and recommendation of products. Don’t Forget to join our 55k+ ML SubReddit. If you like our work, you will love our newsletter.
This post is part of an ongoing series on governing the machine learning (ML) lifecycle at scale. To start from the beginning, refer to Governing the ML lifecycle at scale, Part 1: A framework for architecting ML workloads using Amazon SageMaker. We use SageMaker Model Monitor to assess these models’ performance.
This tokenization scheme, used in frameworks such as TimesFM, Timer, and Moirai, embeds time series data into categorical token sequences, discarding fine-grained information, rigid representation learning, and potential quantization inconsistencies. Dont Forget to join our 75k+ ML SubReddit.
Experiments proceed iteratively, with results categorized as improvements, maintenance, or declines. Dont Forget to join our 65k+ ML SubReddit. It automatically generates and debugs code using an exception-traceback-guided process. This involves analyzing error messages and their related code structure to make corrections efficiently.
Solution overview SageMaker Canvas brings together a broad set of capabilities to help data professionals prepare, build, train, and deploy ML models without writing any code. SageMaker Canvas provides ML data transforms to clean, transform, and prepare your data for model building without having to write code.
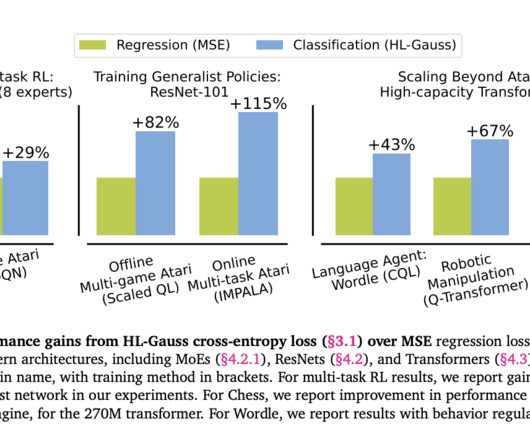
This shift involves converting real-valued targets to categorical labels and minimizing categorical cross-entropy. Their work extensively examines methods for training value functions with categorical cross-entropy loss in deep RL. Join our 38k+ ML SubReddit , 41k+ Facebook Community, Discord Channel , and LinkedIn Gr oup.
It’s ideal for workloads that aren’t latency sensitive, such as obtaining embeddings, entity extraction, FM-as-judge evaluations, and text categorization and summarization for business reporting tasks. With a strong background in AI/ML, Ishan specializes in building Generative AI solutions that drive business value.
This interdisciplinary field incorporates linguistics, computer science, and mathematics, facilitating automatic translation, text categorization, and sentiment analysis. RALMs’ language models are categorized into autoencoder, autoregressive, and encoder-decoder models. Also, don’t forget to follow us on Twitter.
While personalization is nothing new to brands, AI and ML technology allows brands to enter new levels of customer personalization to meet the high consumer expectations. A good product search and discovery experience relies on products being accurately tagged, categorized, and syndicated to the right channels.
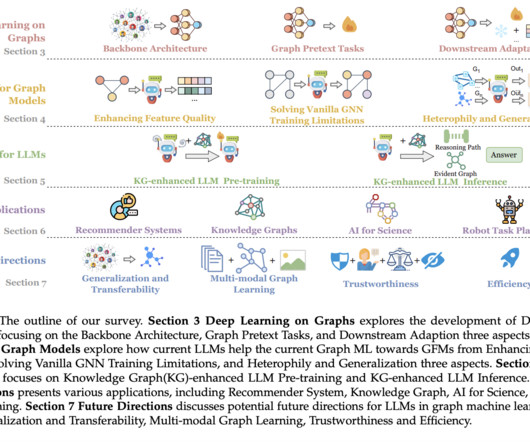
Graph Machine Learning (Graph ML), especially Graph Neural Networks (GNNs), has emerged to effectively model such data, utilizing deep learning’s message-passing mechanism to capture high-order relationships. The researcher also discussed the applications of Graph ML in various fields, such as robot task planning and AI for science.
Machine learning (ML) and deep learning (DL) form the foundation of conversational AI development. ML algorithms understand language in the NLU subprocesses and generate human language within the NLG subprocesses. DL, a subset of ML, excels at understanding context and generating human-like responses.
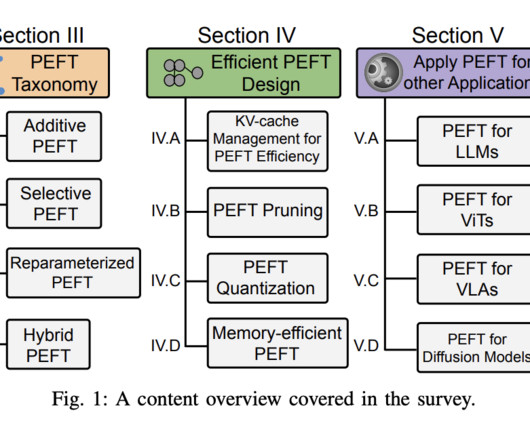
The researchers categorized PEFT algorithms into additive, selective, reparameterized, and hybrid fine-tuning based on their operations. Selective fine-tuning is categorized based on the grouping of chosen parameters: Unstructural Masking and Structural Masking. Also, don’t forget to follow us on Twitter.
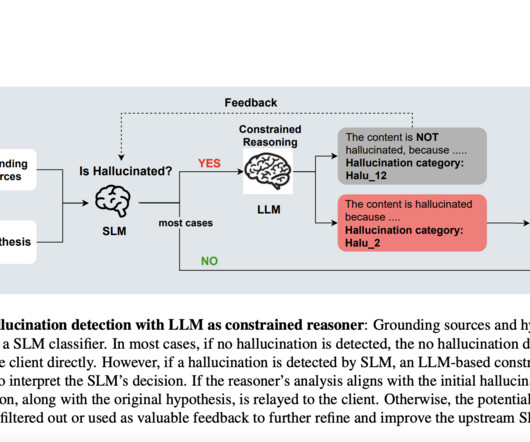
Categorized: Refines the flagging mechanism by incorporating granular hallucination categories, including a specific category (hallu12) to signal inconsistencies where the text is not a hallucination. Compared to the Fallback approach, which showed high precision but poor recall, the Categorized method excelled in both metrics.
The proposed approach was explained by analyzing neural network architectures, particularly transformers, from a categorical perspective, specifically utilizing topos theory. While traditional neural networks can be embedded in pretopos categories, transformers necessarily reside in a topos completion.
The recent development in the fields of Artificial Intelligence (AI) and Machine Learning (ML) models has turned the discussion of Artificial General Intelligence (AGI) into a matter of immediate practical importance. This framework has introduced three important dimensions: autonomy, generality, and performance. Check out the Paper.
By adopting technologies like artificial intelligence (AI) and machine learning (ML), companies can give a boost to their customer segmentation efforts. CRM Readiness: Because ML is such an incipient technology, many CRM (customer relationship management) systems are not equipped to handle it.
This study categorizes existing collaboration strategies, highlights their advantages, and proposes future directions for advancing modular multi-LLM systems. The study categorizes existing multi-LLM collaboration methods into a hierarchy based on information exchange levels, including API, text, logit, and weight-level collaboration.
These solutions categorize and convert data into readable dashboards that anyone in a company can analyze. Data warehouse is the base architecture for artificial intelligence and machine learning (AI/ML) solutions as well.
Users can review different types of events such as security, connectivity, system, and management, each categorized by specific criteria like threat protection, LAN monitoring, and firmware updates. Daniel Pienica is a Data Scientist at Cato Networks with a strong passion for large language models (LLMs) and machine learning (ML).
Data scientists and engineers frequently collaborate on machine learning ML tasks, making incremental improvements, iteratively refining ML pipelines, and checking the model’s generalizability and robustness. To build a well-documented ML pipeline, data traceability is crucial. Check out the Paper.
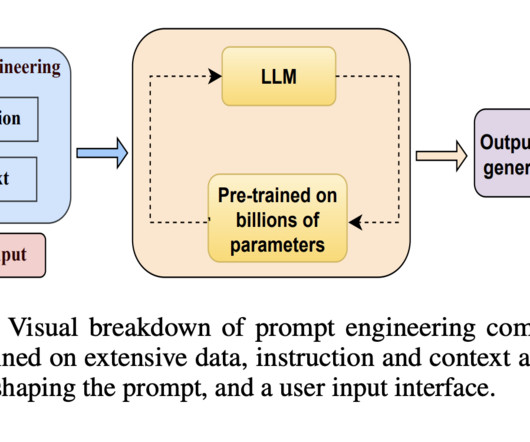
This survey by researchers from the Indian Institute of Technology Patna, Stanford University, and Amazon AI endeavors to bridge this gap by offering a structured overview of the recent advancements in prompt engineering, categorized by application area. Check out the Paper. Also, don’t forget to follow us on Twitter and Google News.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content