This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
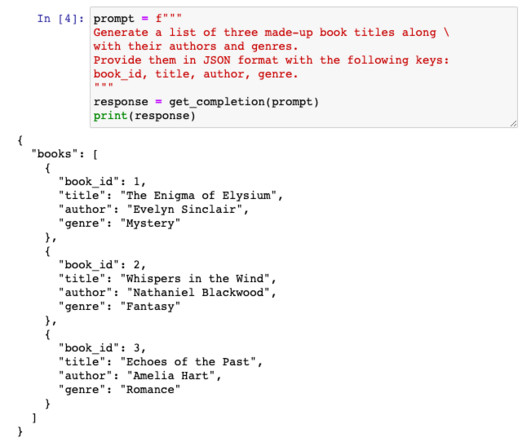
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. For a multiclass classification problem such as support case root cause categorization, this challenge compounds many fold.
In this collaboration, the Generative AI Innovation Center team created an accurate and cost-efficient generative AIbased solution using batch inference in Amazon Bedrock , helping GoDaddy improve their existing product categorization system. Moreover, employing an LLM for individual product categorization proved to be a costly endeavor.
The authors categorize traceable artifacts, propose key features for observability platforms, and address challenges like decision complexity and regulatory compliance. That said, AgentOps (the tool) offers developers insight into agent workflows with features like session replays, LLM cost tracking, and compliance monitoring.
Harnessing the full potential of AI requires mastering promptengineering. This article provides essential strategies for writing effective prompts relevant to your specific users. The strategies presented in this article, are primarily relevant for developers building large language model (LLM) applications.
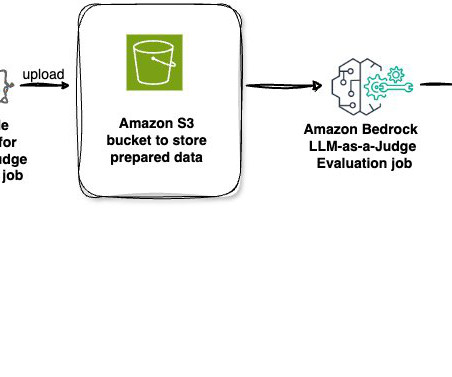
The evaluation of large language model (LLM) performance, particularly in response to a variety of prompts, is crucial for organizations aiming to harness the full potential of this rapidly evolving technology. Both features use the LLM-as-a-judge technique behind the scenes but evaluate different things.
Lettrias in-house team manually assessed the answers with a detailed evaluation grid, categorizing results as correct, partially correct (acceptable or not), or incorrect. Results are then used to augment the prompt and generate a more accurate response compared to standard vector-based RAG.
Next, Amazon Comprehend or custom classifiers categorize them into types such as W2s, bank statements, and closing disclosures, while Amazon Textract extracts key details. Additionally, large language model (LLM)-based analysis is applied to derive further insights, such as video summaries and classifications.
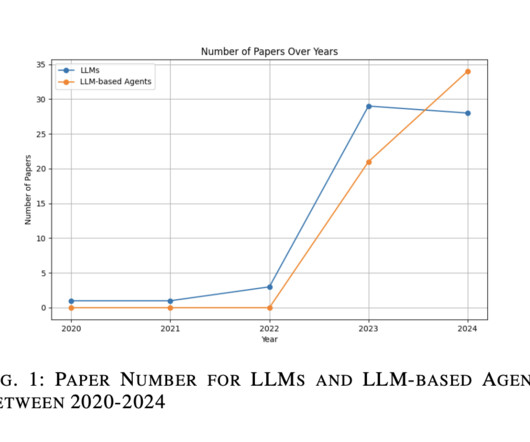
Despite this, LLMs’ use in requirement engineering has gradually increased, driven by advancements in contextual analysis and reasoning through promptengineering and Chain-of-Thought techniques. The field of LLM-based agents lacks standardized benchmarks, impeding effective performance evaluation.
We want to aggregate it, link it, filter it, categorize it, generate it and correct it. I don’t want to undersell how impactful LLMs are for this sort of use-case. You can give an LLM a group of comments and ask it to summarize the texts or identify key themes. Ask for it in the prompt. Need the data in some format?
Fine-tuning is a powerful approach in natural language processing (NLP) and generative AI , allowing businesses to tailor pre-trained large language models (LLMs) for specific tasks. By fine-tuning, the LLM can adapt its knowledge base to specific data and tasks, resulting in enhanced task-specific capabilities.
In this world of complex terminologies, someone who wants to explain Large Language Models (LLMs) to some non-tech guy is a difficult task. So that’s why I tried in this article to explain LLM in simple or to say general language. No training examples are needed in LLM Development but it’s needed in Traditional Development.
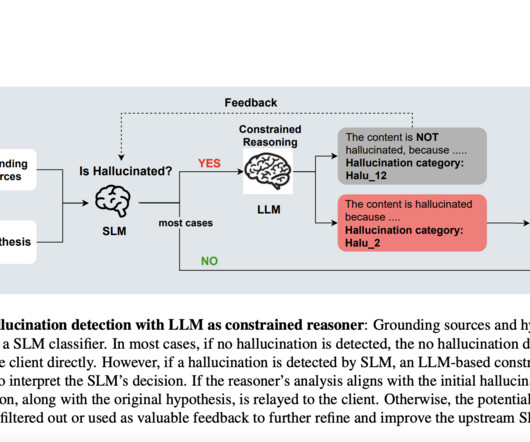
This approach aims to balance latency and interpretability by combining a small classification model, specifically a small language model (SLM), with a downstream LLM module called a “constrained reasoner.” ” The SLM performs initial hallucination detection, while the LLM module explains the detected hallucinations.
Manually analyzing and categorizing large volumes of unstructured data, such as reviews, comments, and emails, is a time-consuming process prone to inconsistencies and subjectivity. Operational efficiency Uses promptengineering, reducing the need for extensive fine-tuning when new categories are introduced.
Building a secure environment is essential to ensure the safe and reliable deployment of LLMs in various applications. Current methods to limit these LLM vulnerabilities include adversarial testing, red-teaming exercises, and manual promptengineering.
Synthetic Data Generation: Prompt the LLM with the designed prompts to generate hundreds of thousands of (query, document) pairs covering a wide variety of semantic tasks across 93 languages. Model Training: Fine-tune a powerful open-source LLM such as Mistral on the synthetic data using contrastive loss.
This post walks through examples of building information extraction use cases by combining LLMs with promptengineering and frameworks such as LangChain. We also examine the uplift from fine-tuning an LLM for a specific extractive task.
TL;DR Hallucinations are an inherent feature of LLMs that becomes a bug in LLM-based applications. Effective mitigation strategies involve enhancing data quality, alignment, information retrieval methods, and promptengineering. What are LLM hallucinations? In 2022, when GPT-3.5
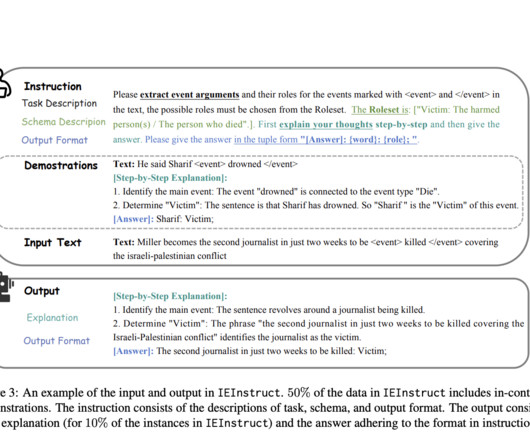
IE tasks compel models to discern and categorize text in formats that align with predefined structures, such as named entity recognition and relation classification. However, existing LLMs typically falter when tasked with the nuanced understanding and alignment necessary for effective IE.
LLM & Agents : At the core, the LLM processes these inputs, collaborating with specialized agents like Auto-GPT for thought chaining, AgentGPT for web-specific tasks, BabyAGI for task-specific actions, and HuggingGPT for team-based processing. Given an objective and a task, it prompts OpenAI's API and retrieves task outcomes.
You can use LLMs in one or all phases of IDP depending on the use case and desired outcome. In this architecture, LLMs are used to perform specific tasks within the IDP workflow. Document classification – In addition to using Amazon Comprehend , you can use an LLM to classify documents using few-shot prompting.
Taxonomy of Hallucination Mitigation Techniques Researchers have introduced diverse techniques to combat hallucinations in LLMs, which can be categorized into: 1. PromptEngineering This involves carefully crafting prompts to provide context and guide the LLM towards factual, grounded responses.
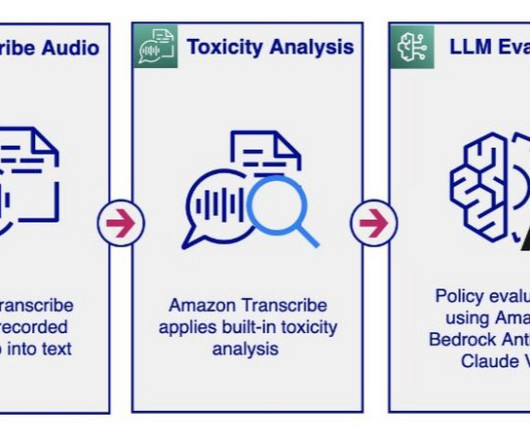
The LLM analysis provides a violation result (Y or N) and explains the rationale behind the model’s decision regarding policy violation. The audio moderation workflow activates the LLM’s policy evaluation only when the toxicity analysis exceeds a set threshold. The LLM model returns an analysis result based on the prompt instructions.
Some components are categorized in groups based on the type of functionality they exhibit. Prompt catalog – Crafting effective prompts is important for guiding large language models (LLMs) to generate the desired outputs. The standalone components are: The HTTPS endpoint is the entry point to the gateway.
As CTO of Humanloop , Peter has assisted companies such as Duolingo, Gusto, and Vanta in solving LLM evaluation challenges for AI applications with millions of daily users. Today, Peter shares his insights on LLM evaluations. This post is a shortened version of Peter’s original blog, titled 'Evaluating LLM Applications '.
Furthermore, we deep dive on the most common generative AI use case of text-to-text applications and LLM operations (LLMOps), a subset of FMOps. Operationalization journey per generative AI user type To simplify the description of the processes, we need to categorize the main generative AI user types, as shown in the following figure.
Document categorization or classification has significant benefits across business domains – Improved search and retrieval – By categorizing documents into relevant topics or categories, it makes it much easier for users to search and retrieve the documents they need. They can search within specific categories to narrow down results.
Learning Path to Building LLM-Based Solutions — For Practitioner Data Scientists As everyone would agree, the advent of LLM has transformed the technology industry, and technocrats have had a huge surge of interest in learning about LLMs. Langchain is very comprehensive, and its applications are evolving rapidly.
Additionally, generative AI with Large Language Models (LLM) is adding powerful capabilities to IDP solutions often bridging gaps that once existed even with highly trained ML models. We will discuss some of the cloud based AI services such as Amazon Comprehend , Amazon Textract , and LLM models via Amazon Bedrock.
The LLM race is also continuing to heat up, with Amazon announcing significant investment into Anthropic AI. It also looks set to beat Amazon’s Alexa to market with a LLM-powered text-to-speech chatbot. – Louie Peters — Towards AI Co-founder and CEO Hottest News 1.OpenAI Five 5-minute reads/videos to keep you learning 1.Adept.ai
Verisk’s evaluation involved three major parts: Promptengineering – Promptengineering is the process where you guide generative AI solutions to generate desired output. Verisk framed prompts using their in-house clinical experts’ knowledge on medical claims.
LARs are a type of embedding that can be used to represent high-dimensional categorical data in a lower-dimensional continuous space. Together AI released Llama-2-7B-32K-Instruct , a long-range LLM that can be used for a variety of tasks, including question answering, summarization, and code generation. takes corrective actions (e.g.
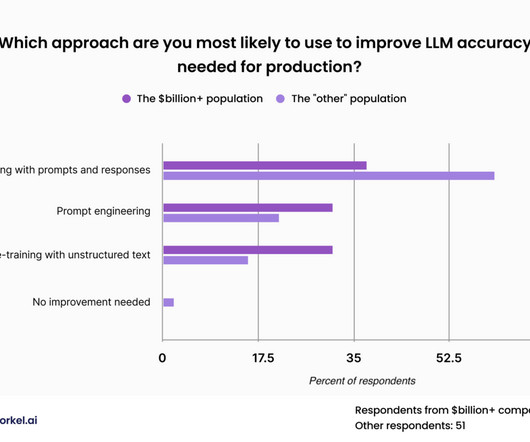
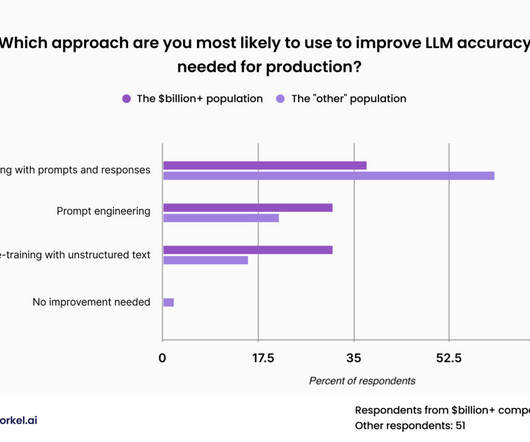
This approach was less popular among our attendees from the wealthiest of corporations, who expressed similar levels of interest in fine-tuning with prompts and responses, fine-tuning with unstructured data, and promptengineering.
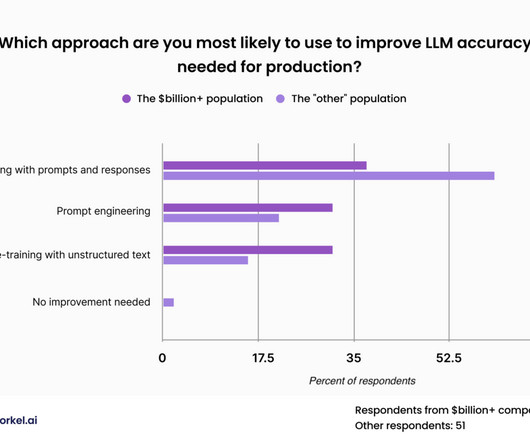
This approach was less popular among our attendees from the wealthiest of corporations, who expressed similar levels of interest in fine-tuning with prompts and responses, fine-tuning with unstructured data, and promptengineering.
Users can easily constrain an LLM’s output with clever promptengineering. That minimizes the chance that the prompt will overrun the context window, and also reduces the cost of high-volume runs. Its categorical power is brittle. Sends the prompt to the LLM. In-context learning.
Users can easily constrain an LLM’s output with clever promptengineering. That minimizes the chance that the prompt will overrun the context window, and also reduces the cost of high-volume runs. Its categorical power is brittle. Sends the prompt to the LLM. In-context learning.
Users can easily constrain an LLM’s output with clever promptengineering. That minimizes the chance that the prompt will overrun the context window, and also reduces the cost of high-volume runs. Its categorical power is brittle. Sends the prompt to the LLM. In-context learning.
The lack of explicit planning mechanisms means that although LLMs generate human-like responses, their internal decision-making remains opaque. As a result, users often rely on promptengineering to guide outputs, but this method lacks precision and does not provide insight into the model’s inherent response formulation.
The simplest RAG system consists of a vector database, an LLM, a user interface, and an orchestrator such as LlamaIndex or LangChain. This final prompt gives the LLM more context with which to answer the users question. This final prompt gives the LLM more context with which to answer the users question.
This, coupled with the challenges of understanding AI concepts and complex algorithms, contributes to the learning curve associated with developing applications using LLMs. Nevertheless, the integration of LLMs with other tools to form LLM-powered applications could redefine our digital landscape.
This approach was less popular among our attendees from the wealthiest of corporations, who expressed similar levels of interest in fine-tuning with prompts and responses, fine-tuning with unstructured data, and promptengineering.
Large language model (LLM)–based AI companions have evolved from simple chatbots into entities that users perceive as friends, partners, or even family members. Seven prevailing strategies were identified as user-driven alignment strategies, which were categorized into three broad approaches.
Classification techniques, such as image recognition and document categorization, remain essential for a wide range of industries. Classification techniques like random forests, decision trees, and support vector machines are among the most widely used, enabling tasks such as categorizing data and building predictive models.
The custom metadata helps organizations and enterprises categorize information in their preferred way. His focus area is AI/ML, and he helps customers with generative AI, large language models, and promptengineering. Recently, her focus has been on exploring the potential of Generative AI and LLM.
At inference time, users provide “prompts” to the LLM—snippets of text that the model uses as a jumping-off point. First, the model converts each token in the prompt into its embedding. The interactive chat simulator allowed non-technical users to prompt the LLM and quickly receive a response.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content