This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
But what if I tell you there’s a goldmine: a repository packed with over 400+ datasets, meticulously categorised across five essential dimensions—Pre-training Corpora, Fine-tuning Instruction Datasets, Preference Datasets, Evaluation Datasets, and Traditional NLP Datasets and more?
LargeLanguageModels (LLMs) signify a revolutionary leap in numerous application domains, facilitating impressive accomplishments in diverse tasks. With billions of parameters, these models demand extensive computational resources for operation. Yet, their immense size incurs substantial computational expenses.
This article explores an innovative way to streamline the estimation of Scope 3 GHG emissions leveraging AI and LargeLanguageModels (LLMs) to help categorize financial transaction data to align with spend-based emissions factors. Why are Scope 3 emissions difficult to calculate?
They serve as a core building block in many natural language processing (NLP) applications today, including information retrieval, question answering, semantic search and more. For text embeddings, contrastive pre-training provides negligible gains over just fine-tuning models like Mistral that already have trillion-scale pre-training.
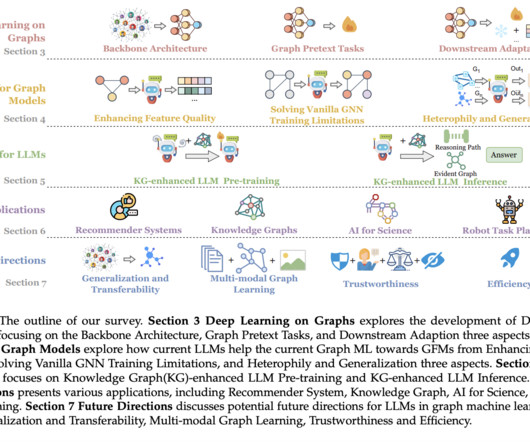
Graph Machine Learning (Graph ML), especially Graph Neural Networks (GNNs), has emerged to effectively model such data, utilizing deep learning’s message-passing mechanism to capture high-order relationships. Foundation Models (FMs) have revolutionized NLP and vision domains in the broader AI spectrum.
In this world of complex terminologies, someone who wants to explain LargeLanguageModels (LLMs) to some non-tech guy is a difficult task. So that’s why I tried in this article to explain LLM in simple or to say general language. A transformer architecture is typically implemented as a Largelanguagemodel.
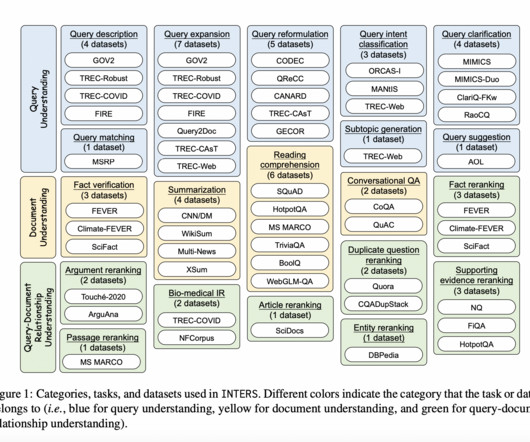
LargeLanguageModels (LLMs) have exhibited remarkable prowess across various natural language processing tasks. However, applying them to Information Retrieval (IR) tasks remains a challenge due to the scarcity of IR-specific concepts in natural language. If you like our work, you will love our newsletter.
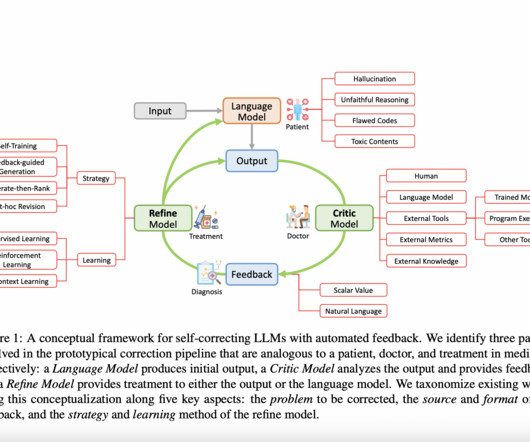
Largelanguagemodels (LLMs) have achieved amazing results in a variety of Natural Language Processing (NLP), Natural Language Understanding (NLU) and Natural Language Generation (NLG) tasks in recent years. Our survey comprehensively documents the MANY types of self-correction strategies.
Computer programs called largelanguagemodels provide software with novel options for analyzing and creating text. It is not uncommon for largelanguagemodels to be trained using petabytes or more of text data, making them tens of terabytes in size. rely on LanguageModels as their foundation.
Developing and refining LargeLanguageModels (LLMs) has become a focal point of cutting-edge research in the rapidly evolving field of artificial intelligence, particularly in natural language processing. A significant innovation in this domain is creating a specialized tool to refine the dataset compilation process.
Natural Language Processing (NLP) is integral to artificial intelligence, enabling seamless communication between humans and computers. This interdisciplinary field incorporates linguistics, computer science, and mathematics, facilitating automatic translation, text categorization, and sentiment analysis.
This advancement has spurred the commercial use of generative AI in natural language processing (NLP) and computer vision, enabling automated and intelligent data extraction. Named Entity Recognition ( NER) Named entity recognition (NER), an NLP technique, identifies and categorizes key information in text.
The benchmark, MLGym-Bench, includes 13 open-ended tasks spanning computer vision, NLP, RL, and game theory, requiring real-world research skills. A six-level framework categorizes AI research agent capabilities, with MLGym-Bench focusing on Level 1: Baseline Improvement, where LLMs optimize models but lack scientific contributions.
Lettrias in-house team manually assessed the answers with a detailed evaluation grid, categorizing results as correct, partially correct (acceptable or not), or incorrect. An example multi-hop query in finance is Compare the oldest booked Amazon revenue to the most recent.
Counselling session by a therapist In our work on medical diagnosis, we have focused on identifying conditions such as depression and anxiety for suicide risk detection using largelanguagemodels (LLMs). Dunns wellness model as a base for our MULTIWD dataset. What are wellness dimensions?
The Logic of Transformers: William Merrill’s Step Towards Understanding LargeLanguageModels’ Limits and Hallucinations The advent of largelanguagemodels (LLMs) based on transformer architecture, which drives products like ChatGPT, has revolutionized machine learning.
This tagging structure categorizes costs and allows assessment of usage against budgets. ListTagsForResource : Fetches the tags associated with a specific Bedrock resource, helping users understand how their resources are categorized. He focuses on Deep learning including NLP and Computer Vision domains.
If you’d like to skip around, here are the languagemodels we featured: BERT by Google GPT-3 by OpenAI LaMDA by Google PaLM by Google LLaMA by Meta AI GPT-4 by OpenAI If this in-depth educational content is useful for you, you can subscribe to our AI research mailing list to be alerted when we release new material. What is the goal?
With advancements in deep learning, natural language processing (NLP), and AI, we are in a time period where AI agents could form a significant portion of the global workforce. Transformers and Advanced NLPModels : The introduction of transformer architectures revolutionized the NLP landscape.
NLPmodels in commercial applications such as text generation systems have experienced great interest among the user. These models have achieved various groundbreaking results in many NLP tasks like question-answering, summarization, language translation, classification, paraphrasing, et cetera.
Beyond the simplistic chat bubble of conversational AI lies a complex blend of technologies, with natural language processing (NLP) taking center stage. NLP translates the user’s words into machine actions, enabling machines to understand and respond to customer inquiries accurately. What makes a good AI conversationalist?
Machine learning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computer vision , largelanguagemodels (LLMs), speech recognition, self-driving cars and more. temperature, salary).
This blog post explores how John Snow Labs Healthcare NLP & LLM library revolutionizes oncology case analysis by extracting actionable insights from clinical text. Summarization and Question-Answering with LLMs: Largelanguagemodels have proven their utility in making clinical text more accessible.
This blog post explores how John Snow Labs’ Healthcare NLP & LLM library is transforming clinical trials by using advanced NER models to efficiently filter through large datasets of patient records. link] John Snow Labs’ Healthcare NLP & LLM library offers a powerful solution to streamline this process.
What are LargeLanguageModels (LLMs)? In generative AI, human language is perceived as a difficult data type. If a computer program is trained on enough data such that it can analyze, understand, and generate responses in natural language and other forms of content, it is called a LargeLanguageModel (LLM).
LargeLanguageModels (LLMs) are revolutionizing how humans and Artificial Intelligence (AI) interact. In this article, we’ll explore what Conversation Intelligence platforms and LargeLanguageModels are before examining the top benefits of integrating LLMs for Conversation Intelligence platforms.
In Natural Language Processing (NLP) tasks, data cleaning is an essential step before tokenization, particularly when working with text data that contains unusual word separations such as underscores, slashes, or other symbols in place of spaces. The post Is There a Library for Cleaning Data before Tokenization?
Largelanguagemodels (LLMs) have made significant leaps in natural language processing, demonstrating remarkable generalization capabilities across diverse tasks. However, due to inconsistent adherence to instructions, these models face a critical challenge in generating accurately formatted outputs, such as JSON.
Since the public unveiling of ChatGPT, largelanguagemodels (or LLMs) have had a cultural moment. But what are largelanguagemodels? Table of contents What are largelanguagemodels (LLMs)? Their new model combined several ideas into something surprisingly simple and powerful.
Since the public unveiling of ChatGPT, largelanguagemodels (or LLMs) have had a cultural moment. But what are largelanguagemodels? Table of contents What are largelanguagemodels (LLMs)? Their new model combined several ideas into something surprisingly simple and powerful.
In this presentation, I’ll demonstrate how the BioGPT generative languagemodel, along with some fine-tuning, can be used for tasks like extracting biomedical relationships, addressing queries, categorizing documents, and creating definitions for biomedical terms.
Foundation models can be trained to perform tasks such as data classification, the identification of objects within images (computer vision) and natural language processing (NLP) (understanding and generating text) with a high degree of accuracy. An open-source model, Google created BERT in 2018. All watsonx.ai
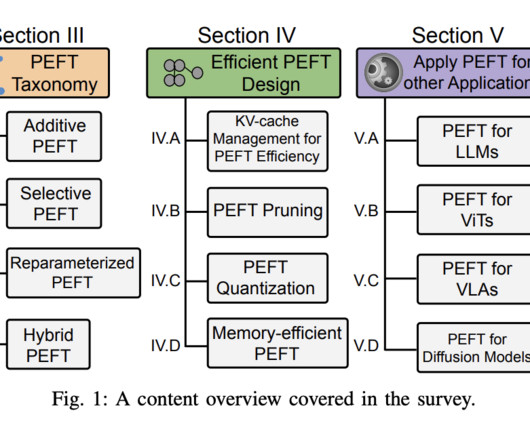
Owing to its robust performance and broad applicability when compared to other methods, LoRA or Low-Rank Adaption is one of the most popular PEFT or Parameter Efficient Fine-Tuning methods for fine-tuning a largelanguagemodel.
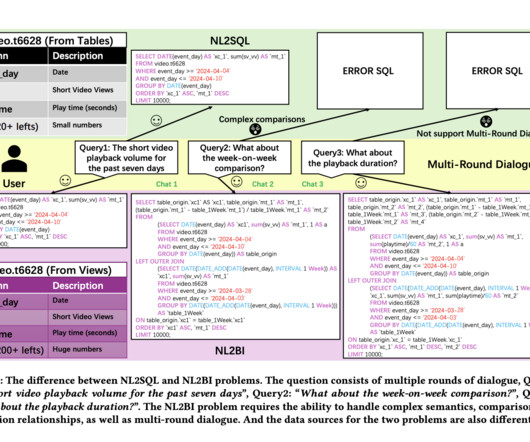
The rapid advancement of LargeLanguageModels (LLMs) has sparked interest among researchers in academia and industry alike. Moreover, differences in data table structures between BI and traditional SQL contexts further complicate the translation process.
Extending weak supervision to non-categorical problems Our research presented in our paper “ Universalizing Weak Supervision ” aimed to extend weak supervision beyond its traditional categorical boundaries to more complex, non-categorical problems where rigid categorization isn’t practical.
Industry Anomaly Detection and Large Vision LanguageModels Existing IAD frameworks can be categorized into two categories. Moving ahead, we have Large Vision LanguageModels or LVLMs. The BLIP-2 framework leverages Q-former to input visual features from Vision Transformer into the Flan-T5 model.
Natural language processing (NLP) in artificial intelligence focuses on enabling machines to understand and generate human language. This field encompasses a variety of tasks, including language translation, sentiment analysis, and text summarization.
Manually analyzing and categorizinglarge volumes of unstructured data, such as reviews, comments, and emails, is a time-consuming process prone to inconsistencies and subjectivity. Largelanguagemodels (LLMs) have transformed the way we engage with and process natural language.
Fast forward to the present, the realm of Natural Language Processing (NLP) has been dominated by transformer models, celebrated for their prowess in understanding and generating human language. However, a lingering question has been their ability to achieve Turing Completeness.
The development of LargeLanguageModels (LLMs), such as GPT and BERT, represents a remarkable leap in computational linguistics. Training these models, however, is challenging. The system’s error detection mechanism is designed to identify and categorize failures during execution promptly.
Users can review different types of events such as security, connectivity, system, and management, each categorized by specific criteria like threat protection, LAN monitoring, and firmware updates. Daniel Pienica is a Data Scientist at Cato Networks with a strong passion for largelanguagemodels (LLMs) and machine learning (ML).
Consequently, there’s been a notable uptick in research within the natural language processing (NLP) community, specifically targeting interpretability in languagemodels, yielding fresh insights into their internal operations.
High-quality labeled data are necessary for many NLP applications, particularly for training classifiers or assessing the effectiveness of unsupervised models. Crowd employees are far more affordable and adaptable, but the quality might be better, especially for difficult activities and languages other than English.
This blog post explores how John Snow Labs’ Healthcare NLPmodels are revolutionizing the extraction of critical insights on opioid use disorder. Here, NLP offers a powerful solution. Let us start with a short Spark NLP introduction and then discuss the details of opioid drugs analysis with some solid results.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content