This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. This use case, solvable through ML, can enable support teams to better understand customer needs and optimize response strategies.
It often requires managing multiple machine learning (ML) models, designing complex workflows, and integrating diverse data sources into production-ready formats. In a world whereaccording to Gartner over 80% of enterprise data is unstructured, enterprises need a better way to extract meaningful information to fuel innovation.
When trained on large datasets, these models often miss critical information from specialized domains, leading to hallucinations or inaccurate responses. By integrating relevant information, models become more precise and effective, significantly improving their performance. ” where the answer can be retrieved from external data.
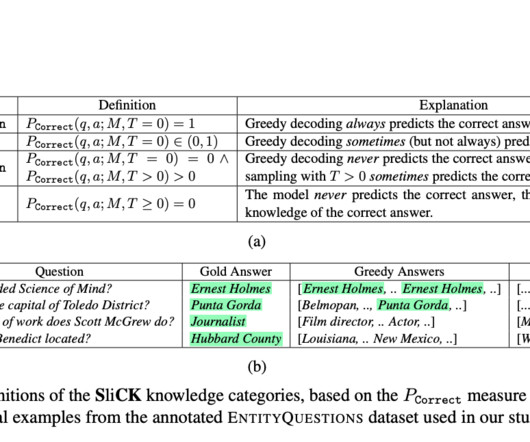
Research in computational linguistics continues to explore how large language models (LLMs) can be adapted to integrate new knowledge without compromising the integrity of existing information. The study’s findings demonstrate the effectiveness of the SliCK categorization in enhancing the fine-tuning process.
Akeneo is the product experience (PX) company and global leader in Product Information Management (PIM). How is AI transforming product information management (PIM) beyond just centralizing data? Akeneo is described as the “worlds first intelligent product cloud”what sets it apart from traditional PIM solutions?
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according to a preset data model. Unstructured information may have a little or a lot of structure but in ways that are unexpected or inconsistent. Additionally, we show how to use AWS AI/ML services for analyzing unstructured data.
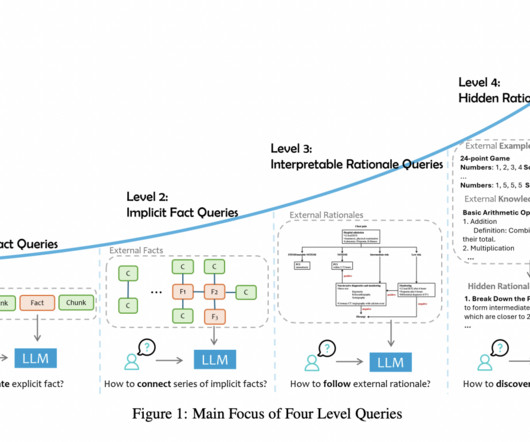
In a world where decisions are increasingly data-driven, the integrity and reliability of information are paramount. Capturing complex human queries with graphs Human questions are inherently complex, often requiring the connection of multiple pieces of information.
Large language models (LLMs) have unlocked new possibilities for extracting information from unstructured text data. SageMaker JumpStart is a machine learning (ML) hub with foundation models (FMs), built-in algorithms, and prebuilt ML solutions that you can deploy with just a few clicks.
Let’s delve into the methods and applications of CL, particularly focusing on its implementation within Information Retrieval (IR) systems presented by researchers from Renmin University of China. Also, don’t forget to follow us on Twitter and join our 46k+ ML SubReddit , 26k+ AI Newsletter, Telegram Channel , and LinkedIn Gr oup.
This article explores an innovative way to streamline the estimation of Scope 3 GHG emissions leveraging AI and Large Language Models (LLMs) to help categorize financial transaction data to align with spend-based emissions factors. Why are Scope 3 emissions difficult to calculate?
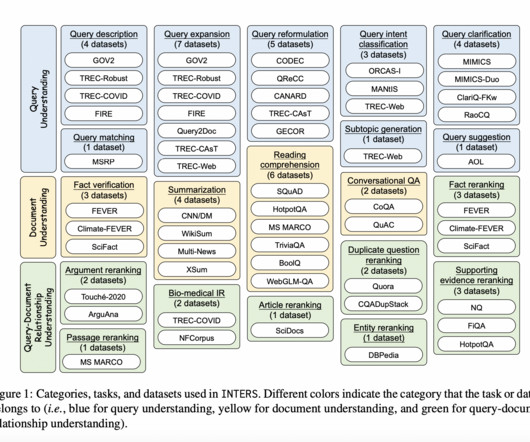
However, applying them to Information Retrieval (IR) tasks remains a challenge due to the scarcity of IR-specific concepts in natural language. This distinction prompts the categorization of tasks into query understanding, document understanding, and query-document relationship understanding.
Information extraction (IE) is a pivotal area of artificial intelligence that transforms unstructured text into structured, actionable data. IE tasks compel models to discern and categorize text in formats that align with predefined structures, such as named entity recognition and relation classification. Check out the Paper.
These systems extend the capabilities of LLMs by integrating an Information Retrieval (IR) phase, which allows them to access external data. Interestingly, the balance between relevance and the inclusion of seemingly unrelated information plays a significant role in the system’s overall performance. Check out the Paper.
The large volume of contacts creates a challenge for CSBA to extract key information from the transcripts that helps sellers promptly address customer needs and improve customer experience. We use multiple AWS AI/ML services, such as Contact Lens for Amazon Connect and Amazon SageMaker , and utilize a combined architecture.
Machine learning (ML) and deep learning (DL) form the foundation of conversational AI development. ML algorithms understand language in the NLU subprocesses and generate human language within the NLG subprocesses. DL, a subset of ML, excels at understanding context and generating human-like responses.
This tagging structure categorizes costs and allows assessment of usage against budgets. ListTagsForResource : Fetches the tags associated with a specific Bedrock resource, helping users understand how their resources are categorized. At its core, the Amazon Bedrock resource tagging system spans multiple operational components.
They focused on improving customer service using data with artificial intelligence (AI) and ML and saw positive results, with their Group AI Maturity increasing from 50% to 80%, according to the TM Forum’s AI Maturity Index. If there are features related to network issues, those users are categorized as network issue-based users.
It’s ideal for workloads that aren’t latency sensitive, such as obtaining embeddings, entity extraction, FM-as-judge evaluations, and text categorization and summarization for business reporting tasks. It stores information such as job ID, status, creation time, and other metadata.
In this sense, it is an example of artificial intelligence that is, teaching computers to see in the same way as people do, namely by identifying and categorizing objects based on semantic categories. Another method for figuring out which category a detected object belongs to is object categorization.
Pyspark MLlib | Classification using Pyspark ML In the previous sections, we discussed about RDD, Dataframes, and Pyspark concepts. In this article, we will discuss about Pyspark MLlib and Spark ML. Our final DataFrame containing the required information is as below: Let's split the data for training and testing.
Some components are categorized in groups based on the type of functionality they exhibit. Some applications may need to access data with personal identifiable information (PII) while others may rely on noncritical data. The standalone components are: The HTTPS endpoint is the entry point to the gateway.
Fourteen behaviors were analyzed and categorized as self-referential (personhood claims, physical embodiment claims, and internal state expressions ) and relational (relationship-building behaviors). Also,feel free to follow us on Twitter and dont forget to join our 75k+ ML SubReddit. Check out the Paper.
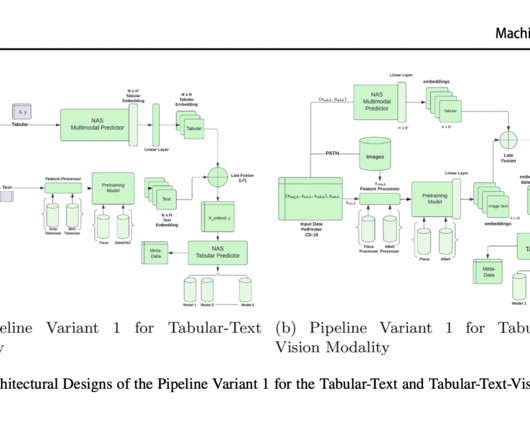
There are currently no systematic comparisons between different information fusion approaches and no generalized frameworks for multi-modality processing; these are the main obstacles to multimodal AutoML. It contains hierarchically structured components, including pre-trained models, feature processors, and classical ML models.
Rule-based systems or specialized machine learning (ML) models often struggle with the variability of real-world documents, especially when dealing with semi-structured and unstructured data. For more information, see Create a guardrail. Semi-structured document A health insurance card that contains essential coverage information.
Intuitivo, a pioneer in retail innovation, is revolutionizing shopping with its cloud-based AI and machine learning (AI/ML) transactional processing system. Our AI/ML research team focuses on identifying the best computer vision (CV) models for our system. Foundation models can make a significant difference in product labeling.
This tokenization scheme, used in frameworks such as TimesFM, Timer, and Moirai, embeds time series data into categorical token sequences, discarding fine-grained information, rigid representation learning, and potential quantization inconsistencies. Dont Forget to join our 75k+ ML SubReddit.
This interdisciplinary field incorporates linguistics, computer science, and mathematics, facilitating automatic translation, text categorization, and sentiment analysis. RALMs’ language models are categorized into autoencoder, autoregressive, and encoder-decoder models. Also, don’t forget to follow us on Twitter.
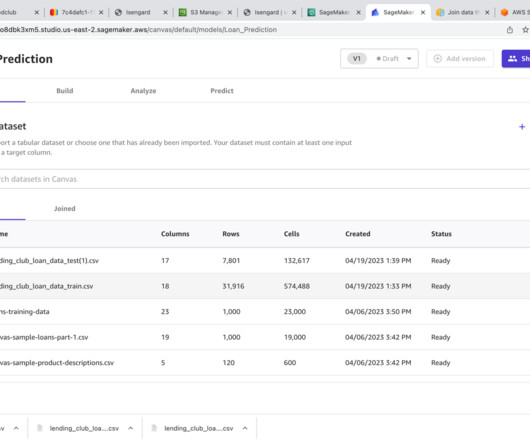
You can now retrain machine learning (ML) models and automate batch prediction workflows with updated datasets in Amazon SageMaker Canvas , thereby making it easier to constantly learn and improve the model performance and drive efficiency. An ML model’s effectiveness depends on the quality and relevance of the data it’s trained on.
Solution overview SageMaker Canvas brings together a broad set of capabilities to help data professionals prepare, build, train, and deploy ML models without writing any code. SageMaker Canvas provides ML data transforms to clean, transform, and prepare your data for model building without having to write code.
Beginner’s Guide to ML-001: Introducing the Wonderful World of Machine Learning: An Introduction Everyone is using mobile or web applications which are based on one or other machine learning algorithms. Machine learning(ML) is evolving at a very fast pace. Machine learning(ML) is evolving at a very fast pace. Models […]
By adopting technologies like artificial intelligence (AI) and machine learning (ML), companies can give a boost to their customer segmentation efforts. Because its segmentation process is run only by data, we can then learn about customer segments that we hadn’t thought about, and this uncovers unique information about our customers.
Machine learning (ML) projects are inherently complex, involving multiple intricate steps—from data collection and preprocessing to model building, deployment, and maintenance. To start our ML project predicting the probability of readmission for diabetes patients, you need to download the Diabetes 130-US hospitals dataset.
This post is part of an ongoing series on governing the machine learning (ML) lifecycle at scale. To start from the beginning, refer to Governing the ML lifecycle at scale, Part 1: A framework for architecting ML workloads using Amazon SageMaker. We use SageMaker Model Monitor to assess these models’ performance.
Why data warehousing is critical to a company’s success Data warehousing is the secure electronic information storage by a company or organization. These solutions categorize and convert data into readable dashboards that anyone in a company can analyze. Business success and the ability to remain competitive depended on it.
Quick iteration and faster time-to-value can be achieved by providing these analysts with a visual business intelligence (BI) tool for simple analysis, supported by technologies like machine learning (ML). For more information about prerequisites, see Getting started with using Amazon SageMaker Canvas. A QuickSight subscription.
a low-code enterprise graph machine learning (ML) framework to build, train, and deploy graph ML solutions on complex enterprise-scale graphs in days instead of months. With GraphStorm, we release the tools that Amazon uses internally to bring large-scale graph ML solutions to production. license on GitHub. GraphStorm 0.1
Manually analyzing and categorizing large volumes of unstructured data, such as reviews, comments, and emails, is a time-consuming process prone to inconsistencies and subjectivity. The following table compares the generative approach (generative AI) with the discriminative approach (traditional ML) across multiple aspects.
While Document AI (DocAI) has made significant strides in areas such as question answering, categorization, and extraction, real-world applications continue to face persistent hurdles related to accuracy, reliability, contextual understanding, and generalization to new domains. Check out the Paper.
Data scientists and engineers frequently collaborate on machine learning ML tasks, making incremental improvements, iteratively refining ML pipelines, and checking the model’s generalizability and robustness. To build a well-documented ML pipeline, data traceability is crucial.
For more information about this process, refer to New — Introducing Support for Real-Time and Batch Inference in Amazon SageMaker Data Wrangler. For more information, refer to Creating roles and attaching policies (console). In this step, we use some of these transformations to prepare the dataset for an ML model.
These tasks include summarization, classification, information retrieval, open-book Q&A, and custom language generation such as SQL. If the answer contradicts the information in context, it's incorrect. I'll check the table for information. Sonnet across various tasks.
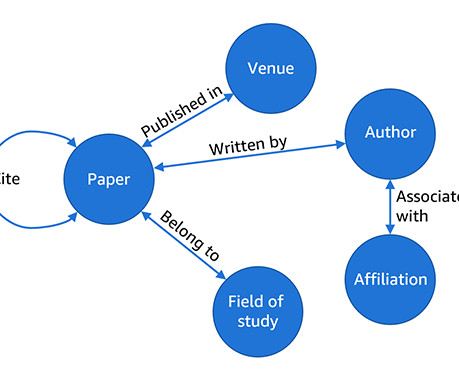
Although graphs have high utility, they have been criticized for intricate text-based queries and manual exploration, which obstruct the extraction of pertinent information. This article discusses the latest research that uses language models to streamline information extraction from graph databases.
Identifying & Flagging Hate Speech Using AI In the battle against hate speech, AI emerges as a formidable ally, with machine learning (ML) algorithms to identify and flag harmful content swiftly and accurately. It involves generating persuasive and informative content to promote empathy, understanding, and tolerance.
Text mining —also called text data mining—is an advanced discipline within data science that uses natural language processing (NLP) , artificial intelligence (AI) and machine learning models, and data mining techniques to derive pertinent qualitative information from unstructured text data. positive, negative or neutral).
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content