This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In a world whereaccording to Gartner over 80% of enterprise data is unstructured, enterprises need a better way to extract meaningful information to fuel innovation. IDP is powering critical workflows across industries and enabling businesses to scale with speed and accuracy. billion in 2025 to USD 66.68
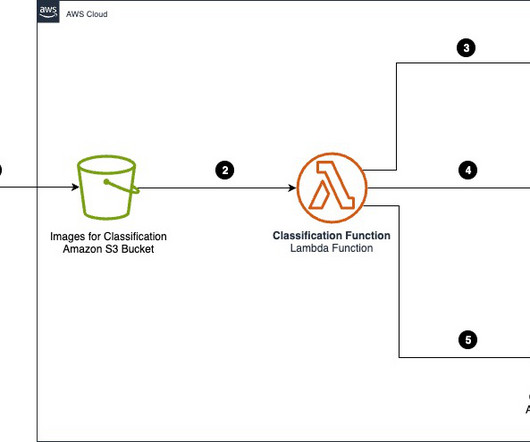
An intelligent document processing (IDP) project usually combines optical character recognition (OCR) and natural language processing (NLP) to read and understand a document and extract specific terms or words. It also provides guidance to tackle common challenges, enabling you to architect your IDP workloads according to best practices.
With this new feature, you can use your own identity provider (IdP) such as Okta , Azure AD , or Ping Federate to connect to Snowflake via Data Wrangler. Solution overview In the following sections, we provide steps for an administrator to set up the IdP, Snowflake, and Studio. Provide the users within the IdP access to Data Wrangler.
This represents a major opportunity for businesses to optimize this workflow, save time and money, and improve accuracy by modernizing antiquated manual document handling with intelligent document processing (IDP) on AWS. Finding relevant information that is necessary for business decisions is difficult.
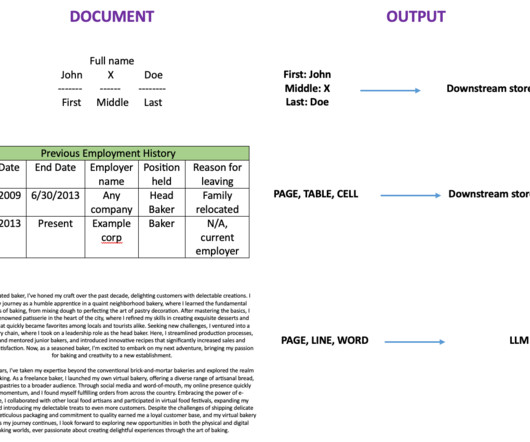
Organizations across industries want to categorize and extract insights from high volumes of documents of different formats. Manually processing these documents to classify and extract information remains expensive, error prone, and difficult to scale. Categorizing documents is an important first step in IDP systems.
Through a practical use case of processing a patient health package at a doctors office, you will see how this technology can extract and synthesize information from all three document types, potentially improving data accuracy and operational efficiency. For more information, see Create a guardrail.
In today’s information age, the vast volumes of data housed in countless documents present both a challenge and an opportunity for businesses. Document processing has witnessed significant advancements with the advent of Intelligent Document Processing (IDP). However, the potential doesn’t end there.
Dynamic content, including user-specific information, should be placed at the end of the prompt. How to use prompt caching When evaluating a use case to use prompt caching, its crucial to categorize the components of a given prompt into two distinct groups: the static and repetitive portion, and the dynamic portion. 2][3]'" "nn5.
These documents often contain vital information that drives timely decision-making, essential for ensuring top-tier customer satisfaction, and reduced customer churn. In this article, I briefly discuss the various phases of IDP and how generative AI is being utilized to augment existing IDP workloads or develop new IDP workloads.
AWS intelligent document processing (IDP), with AI services such as Amazon Textract , allows you to take advantage of industry-leading machine learning (ML) technology to quickly and accurately process data from any scanned document or image. In this post, we share how to enhance your IDP solution on AWS with generative AI.
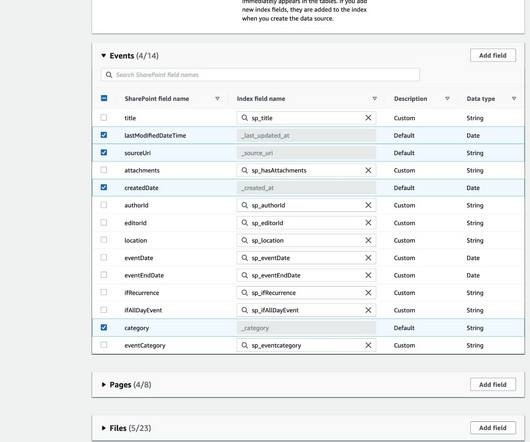
You can filter the search results based on the user and group information to ensure your search results are only shown based on user access rights. For more information, see Overview of access management: Permissions and policies. For more information, refer to SharePoint Configuration. You can now also choose OAuth 2.0
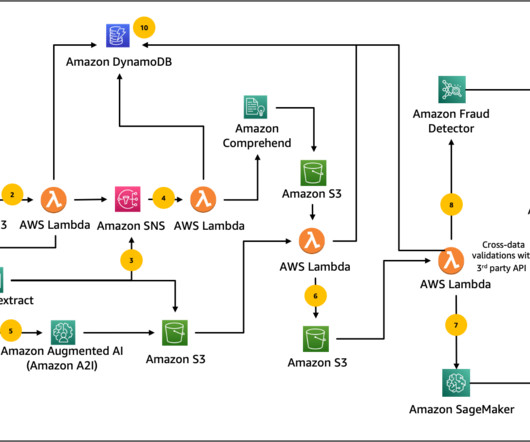
We provide concrete guidance on addressing this issue with AWS AI and ML services to detect document tampering, identify and categorize patterns for fraudulent scenarios, and integrate with business-defined rules while minimizing human expertise for fraud detection. These fraud attempts can be challenging for mortgage lenders to capture.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















Let's personalize your content