This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The gait is not biological, but the robot isnt biological, explains Farbod Farshidian , roboticist at the RAI Institute. The best Farshidian can categorize how Spot is moving is that its somewhat similar to a trotting gait, except with an added flight phase (with all four feet off the ground at once) that technically turns it into a run.
This approach eliminates the scalability constraints of prior models, such as the need for manual task categorization or reliance on dataset identifiers during training, aimed at preventing a one-to-many interference problem , typical of multi-task training scenarios.
This story explores CatBoost, a powerful machine-learning algorithm that handles both categorical and numerical data easily. CatBoost is a powerful, gradient-boosting algorithm designed to handle categorical data effectively. CatBoost automatically transforms them, making it ideal for datasets with many categorical variables.
Scope 3 emissions disclosure Envizi’s Scope 3 GHG Accounting and Reporting module enables the capture of upstream and downstream GHG emissions data, calculates emissions using a robust analytics engine and categorizes emissions by value chain supplier, data type, intensities and other metrics to support auditability.
The way it categorizes incoming emails automatically has also helped me maintain that elusive “inbox zero” I could only dream about. It also supports 18 different writing styles categorized into four groups. It explains why something might need changing! But it doesn't just flag issues.
Summary: This blog explains the differences between one-way ANOVA vs two-way ANOVA, their definitions, assumptions, and applications. Step 3: Organise Your Data Structure your data with: One categorical independent variable (e.g., Step 3: Organise Your Data Set up your dataset with: Two categorical independent variables (e.g.,
Additionally, by displaying the potential transformations between several tables, DATALORE’s LLM-based data transformation generation can substantially enhance the return results’ explainability, particularly useful for users interested in any connected table. Check out the Paper. Also, don’t forget to follow us on Twitter.
Bookkeeping involves the meticulous scanning of receipts, methodically tracking all income and expenses, and categorizing expenditures. However, now, you need to categorize it for tax purposes. Imagine this scenario: you’ve purchased a printer for your home office, and it turns out to be of great help.
This article explores an innovative way to streamline the estimation of Scope 3 GHG emissions leveraging AI and Large Language Models (LLMs) to help categorize financial transaction data to align with spend-based emissions factors. Why are Scope 3 emissions difficult to calculate?
Artificial intelligence (AI) technologies, particularly Vision Transformers (ViTs), have shown immense promise in their ability to identify and categorize objects in images. Now, a group of researchers has developed a breakthrough solution: a novel methodology known as “Patch-to-Cluster attention” (PaCa). .
Introduction Classification algorithms are at the heart of data science, helping us categorize and organize data into pre-defined classes. It is for this reason that those new to data science must know about […] The post 5 Essential Classification Algorithms Explained for Beginners appeared first on MachineLearningMastery.com.
OpenAI engineer Wojciech Zaremba explained on a podcast that year that the company had determined there was not enough real-world data of how to move in the real world to keep making progress on the robot. A task, notably, is not the same as a job or occupation. But is it possible to be more systematic?
In their paper, the researchers aim to propose a theory that explains how transformers work, providing a definite perspective on the difference between traditional feedforward neural networks and transformers. Despite their widespread usage, the theoretical foundations of transformers have yet to be fully explored.
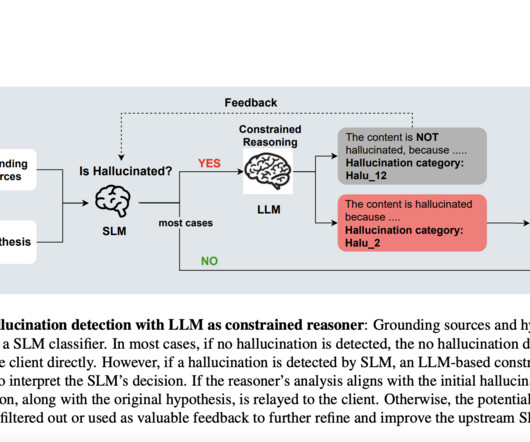
” The SLM performs initial hallucination detection, while the LLM module explains the detected hallucinations. The reasoner is “constrained” in the sense that it focuses solely on explaining the SLM’s decision, rather than performing an open-ended analysis. The methodology focuses on three primary approaches: 1.
Bias in AI typically can be categorized into algorithmic bias and data-driven bias. Explainable AI tools make spotting and correcting biases in real time easier. Consequently, the foundational design of AI systems often fails to include the diversity of global cultures and languages, leaving vast regions underrepresented.
Snorkel AI has thoroughly explained weak supervision elsewhere, but I will explain the concept briefly here. Expanding weak supervision to new frontiers Addressing non-categorical problems through weak supervision, particularly in ranking scenarios, underscores the versatility and power of this approach.
Snorkel AI has thoroughly explained weak supervision elsewhere, but I will explain the concept briefly here. Expanding weak supervision to new frontiers Addressing non-categorical problems through weak supervision, particularly in ranking scenarios, underscores the versatility and power of this approach.
In this post, we explore why GraphRAG is more comprehensive and explainable than vector RAG alone, and how you can use this approach using AWS services and Lettria. Lettrias in-house team manually assessed the answers with a detailed evaluation grid, categorizing results as correct, partially correct (acceptable or not), or incorrect.
RL algorithms can be generally categorized into two groups i.e., value-based and policy-based methods. Policy Gradient Method As explained above, Policy Gradient (PG) methods are algorithms that aim to learn the optimal policy function directly in a Markov Decision Processes setting (S, A, P, R, γ).
Although both RAG and fine-tuning have their pros and cons, RAG is the best approach for building a PAAS AI on the PAAS platform, given Verisks needs for real-time accuracy, explainability, and configurability. Issue categorization After an issue is identified, its categorized based on its nature.
We have categorized the posts into two main categories– those seeking help and those that do not. These misclassifications and errors explain that the models can sometimes misinterpret strong language when used along with the updates as urgent help-seeking posts.
It turns out that almost all of these LLMs (open-sourced) and projects deal with major security concerns, which the experts have categorized as follows: 1. A New Research Explains The Risk Factors Associated With Open-Source LLMs appeared first on MarkTechPost.
Lucena explained how random forests first introduced the power of ensembles, but gradient boosting takes it a step further by focusing on the residual errors from previous trees. CatBoost : Specialized in handling categorical variables efficiently. LightGBM : Optimized for speed and scalability, making it useful for large datasets.
In this post, I will discuss the common problems with existing solutions, explain why I am no longer a fan of Kaggle, propose a better solution, and outline a personalized prediction approach. As shown in the profile of the dataset, there are both integer and categorical features. Product_Category_1 to _3: Category of the product.
Many graphical models are designed to work exclusively with continuous or categorical variables, limiting their applicability to data that spans different types. Moreover, specific restrictions, such as continuous variables not being allowed as parents of categorical variables in directed acyclic graphs (DAGs), can hinder their flexibility.
Give an explantion on why each tool was used and if you are not using a tool, explain why it was not used as well" + "Think step by step.") Sonnet to analyze and categorize each page of the uploaded document into three main types: intake forms, insurance cards, and doctors notes: # from document_classifier.py
To find the relationship between a numeric variable (like age or income) and a categorical variable (like gender or education level), we first assign numeric values to the categories in a way that allows them to best predict the numeric variable. Linear categorical to categorical correlation is not supported.
The author explains how to design meaningful visualizations by first understanding the data behind the same. It covers topics like plotting continuous and categorical variables, grouping, summarizing, and transforming data for plotting, creating maps, and refining plots to make them more understandable.
Get ranked applicant results, categorize candidates, and automate pre-screening Q&A collecting to deliver actionable insights. To summarize Serra, a candidate search engine powered by artificial intelligence, explains the challenges recruiters face and how it plans to address them.
When it comes to implementing any ML model, the most difficult question asked is how do you explain it. Suppose, you are a data scientist working closely with stakeholders or customers, even explaining the model performance and feature selection of a Deep learning model is quite a task. How can we explain it in simple terms?
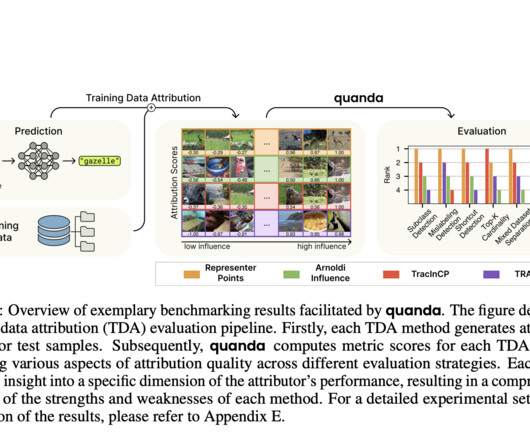
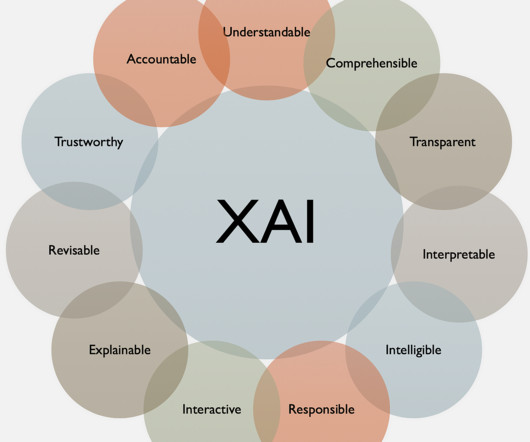
XAI, or Explainable AI, brings about a paradigm shift in neural networks that emphasizes the need to explain the decision-making processes of neural networks, which are well-known black boxes. Quanda differs from its contemporaries, like Captum, TransformerLens, Alibi Explain, etc.,
Manually analyzing and categorizing large volumes of unstructured data, such as reviews, comments, and emails, is a time-consuming process prone to inconsistencies and subjectivity. Explainability Provides explanations for its predictions through generated text, offering insights into its decision-making process.
The AI Act takes a risk-based approach, meaning that it categorizes applications according to their potential risk to fundamental rights and safety. Depending on which role you have as a company, you will need to comply with different requirements,” Simons explains. Or are you actually fine-tuning the model quite a bit?
As Argonne postdoctoral researcher James (Jay) Horwath explains, “The way we understand how materials move and change over time is by collecting X-ray scattering data.” ” This ability to recognize and categorize patterns without human intervention allows for a more comprehensive and unbiased analysis of material behavior.
It explains how GNNs interpret nodes and edges, using examples like cities connected by roads. It defines AI agents, categorizing them by type and architectural topology, and outlines their characteristics and developmental stages within an enterprise context.
In the ever-evolving landscape of machine learning and artificial intelligence, understanding and explaining the decisions made by models have become paramount. Enter Comet , that streamlines the model development process and strongly emphasizes model interpretability and explainability. Why Does It Matter?
In this hands-on session, youll start with logistic regression and build up to categorical and ordered logistic models, applying them to real-world survey data. Explainable AI for Decision-Making Applications Patrick Hall, Assistant Professor at GWSB and Principal Scientist at HallResearch.ai
However, the challenge lies in integrating and explaining multimodal data from various sources, such as sensors and images. AI models are often sensitive to small changes, necessitating a focus on trustworthy AI that emphasizes explainability and robustness.
Text Classification : Categorizing text into predefined categories based on its content. It is used to automatically detect and categorize posts or comments into various groups such as ‘offensive’, ‘non-offensive’, ‘spam’, ‘promotional’, and others. It’s ‘trained’ on labeled data and then used to categorize new, unseen data.
Through a runtime process that includes preprocessing and postprocessing steps, the agent categorizes the user’s input. Technical Info: Provide part specifications, features, and explain component functions. At this stage, the agent employs guardrails to make sure it stays within its defined scope and capabilities.
Existing surveys detail a range of techniques utilized in Explainable AI analyses and their applications within NLP. The LM interpretability approaches discussed are categorized based on two dimensions: localizing inputs or model components for predictions and decoding information within learned representations.
This post explains a generative artificial intelligence (AI) technique to extract insights from business emails and attachments. It examines how AI can optimize financial workflow processes by automatically summarizing documents, extracting data, and categorizing information from email attachments. pip install unstructured !pip
Evaluate and categorize the components of procurement costs, from direct costs—such as the costs of goods and services—to indirect costs—such as administrative expenses and overhead. Communicate the opportunities these changes bring and explain their benefits for stakeholders. Be flexible.
This tutorial will explain how to quickly transcribe audio or video files in Python applications using the Best and Nano tiers with our Speech-to-Text API. Next, there are many further features that AssemblyAI offers beyond transcription to explore, such as: Entity detection to automatically identify and categorize key information.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content