This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
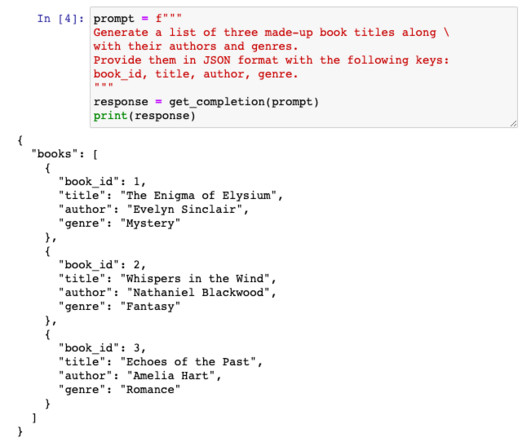
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. For a multiclass classification problem such as support case root cause categorization, this challenge compounds many fold.
Today, were excited to announce the general availability of Amazon Bedrock Data Automation , a powerful, fully managed feature within Amazon Bedrock that automate the generation of useful insights from unstructured multimodal content such as documents, images, audio, and video for your AI-powered applications. billion in 2025 to USD 66.68
Harnessing the full potential of AI requires mastering promptengineering. This article provides essential strategies for writing effective prompts relevant to your specific users. Let’s explore the tactics to follow these crucial principles of promptengineering and other best practices.
In today’s information age, the vast volumes of data housed in countless documents present both a challenge and an opportunity for businesses. Traditional document processing methods often fall short in efficiency and accuracy, leaving room for innovation, cost-efficiency, and optimizations. However, the potential doesn’t end there.
The key to the capability of the solution is the prompts we have engineered to instruct Anthropics Claude what to do. PromptengineeringPromptengineering is the process of carefully designing the input prompts or instructions that are given to LLMs and other generative AI systems.
Also, end-user queries are not always aligned semantically to useful information in provided documents, leading to vector search excluding key data points needed to build an accurate answer. Results are then used to augment the prompt and generate a more accurate response compared to standard vector-based RAG.
This post presents a solution for developing a chatbot capable of answering queries from both documentation and databases, with straightforward deployment. For documentation retrieval, Retrieval Augmented Generation (RAG) stands out as a key tool. Virginia) AWS Region. The following diagram illustrates the solution architecture.
Companies in sectors like healthcare, finance, legal, retail, and manufacturing frequently handle large numbers of documents as part of their day-to-day operations. These documents often contain vital information that drives timely decision-making, essential for ensuring top-tier customer satisfaction, and reduced customer churn.
Text embeddings are vector representations of words, sentences, paragraphs or documents that capture their semantic meaning. Synthetic Data Generation: Prompt the LLM with the designed prompts to generate hundreds of thousands of (query, document) pairs covering a wide variety of semantic tasks across 93 languages.
Fine-tuning Anthropic’s Claude 3 Haiku has demonstrated superior performance compared to few-shot promptengineering on base Anthropic’s Claude 3 Haiku, Anthropic’s Claude 3 Sonnet, and Anthropic’s Claude 3.5 Sonnet across various tasks. This decision should be based either on the provided context or your general knowledge and memory.
Manually analyzing and categorizing large volumes of unstructured data, such as reviews, comments, and emails, is a time-consuming process prone to inconsistencies and subjectivity. Operational efficiency Uses promptengineering, reducing the need for extensive fine-tuning when new categories are introduced.
Tasks such as routing support tickets, recognizing customers intents from a chatbot conversation session, extracting key entities from contracts, invoices, and other type of documents, as well as analyzing customer feedback are examples of long-standing needs. We also examine the uplift from fine-tuning an LLM for a specific extractive task.
Documentcategorization or classification has significant benefits across business domains – Improved search and retrieval – By categorizingdocuments into relevant topics or categories, it makes it much easier for users to search and retrieve the documents they need. politics, sports) that a document belongs to.
Furthermore, the knowledge base includes the referenced policy documents used by the evaluation, providing moderators with additional context. This enables you to manage the policy document flexibly, allowing the workflow to retrieve only the relevant policy segments for each input message.
Some components are categorized in groups based on the type of functionality they exhibit. Prompt catalog – Crafting effective prompts is important for guiding large language models (LLMs) to generate the desired outputs. Having a centralized prompt catalog is essential for storing, versioning, tracking, and sharing prompts.
It streamlines document review for anyone needing to identify medical information within records, including bodily injury claims adjusters and managers, nurse reviewers and physicians, administrative staff, and legal professionals. These medical records are mostly unstructured documents, often containing multiple dates of service.
Large language Models also intersect with Generative Ai, it can perform a variety of Natural Language Processing tasks, including generating and classifying text, question answering, and translating text from one language to another language, and Document summarization. What are large language models used for?
Curated judge models : Amazon Bedrock provides pre-selected, high-quality evaluation models with optimized promptengineering for accurate assessments. Users dont need to bring external judge models, because the Amazon Bedrock team maintains and updates a selection of judge models and associated evaluation judge prompts.
Taxonomy of Hallucination Mitigation Techniques Researchers have introduced diverse techniques to combat hallucinations in LLMs, which can be categorized into: 1. PromptEngineering This involves carefully crafting prompts to provide context and guide the LLM towards factual, grounded responses.
Enterprises may want to add custom metadata like document types (W-2 forms or paystubs), various entity types such as names, organization, and address, in addition to the standard metadata like file type, date created, or size to extend the intelligent search while ingesting the documents.
However, noise, ambiguity, and deviation in intent in user queries are often a hindrance to effective document retrieval. Query rewriting plays an important role in refining such inputs to ensure that retrieved documents more closely match the actual intent of the user. Don’t Forget to join our 55k+ ML SubReddit.
Operationalization journey per generative AI user type To simplify the description of the processes, we need to categorize the main generative AI user types, as shown in the following figure. Strong domain knowledge for tuning, including promptengineering, is required as well. We will cover monitoring in a separate post.
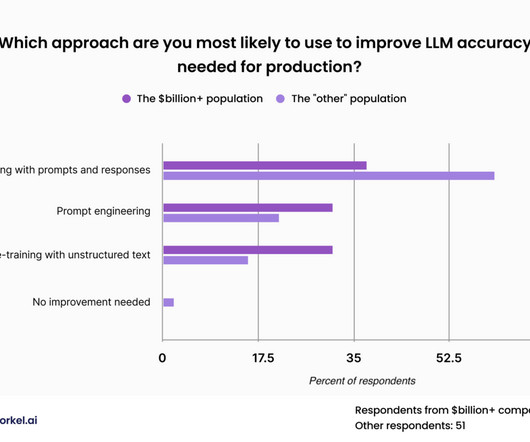
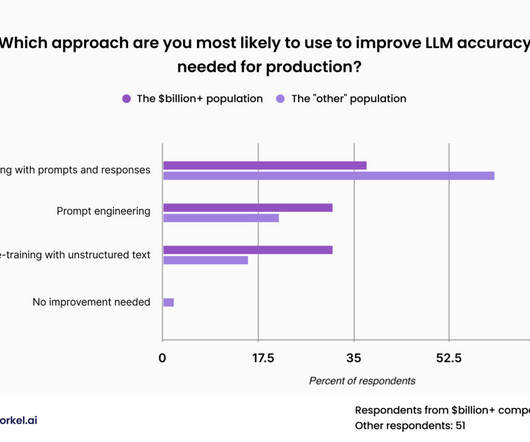
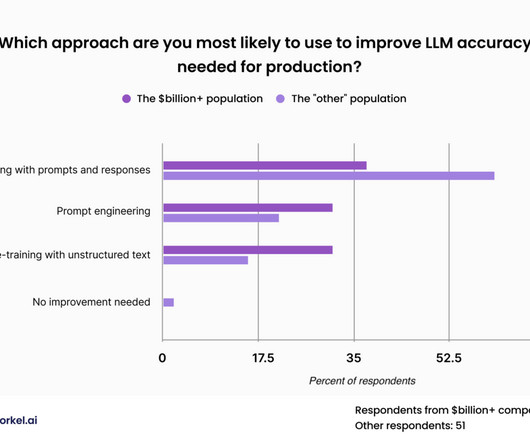
This approach was less popular among our attendees from the wealthiest of corporations, who expressed similar levels of interest in fine-tuning with prompts and responses, fine-tuning with unstructured data, and promptengineering. But this approach requires labeled data—and a fair amount of it.
This approach was less popular among our attendees from the wealthiest of corporations, who expressed similar levels of interest in fine-tuning with prompts and responses, fine-tuning with unstructured data, and promptengineering. But this approach requires labeled data—and a fair amount of it.
RAG systems combine the strengths of reliable source documents with the generative capability of large language models (LLMs). After a user enters their query, the system retrieves relevant documents or document chunks from the vector database and adds them to the initial request as context.
We have categorized them to make it easier to cover maximum tools. This allows Bard to serve as a personal AI assistant, aiding in tasks like email responses, content creation, document translation, and meeting note summarization. Mistral 7B : It is a powerful language model, boasting 7.3
OpenAI Announces DALL·E 3 OpenAI is launching DALL·E 3, an improved version that excels in following instructions, requires less promptengineering, and can communicate with ChatGPT. This integration enables users to refine DALL·E 3 prompts by describing their ideas to ChatGPT. Five 5-minute reads/videos to keep you learning 1.Adept.ai
Effective mitigation strategies involve enhancing data quality, alignment, information retrieval methods, and promptengineering. Broadly speaking, we can reduce hallucinations in LLMs by filtering responses, promptengineering, achieving better alignment, and improving the training data. In 2022, when GPT-3.5
In this article, we will delve deeper into these issues, exploring the advanced techniques of promptengineering with Langchain, offering clear explanations, practical examples, and step-by-step instructions on how to implement them. Prompts play a crucial role in steering the behavior of a model.
Turbo, including documentation, tutorials, and pre-trained models. LARs are a type of embedding that can be used to represent high-dimensional categorical data in a lower-dimensional continuous space. TypeChat replaces promptengineering with schema engineering.
This approach was less popular among our attendees from the wealthiest of corporations, who expressed similar levels of interest in fine-tuning with prompts and responses, fine-tuning with unstructured data, and promptengineering. But this approach requires labeled data—and a fair amount of it.
Users can easily constrain an LLM’s output with clever promptengineering. That minimizes the chance that the prompt will overrun the context window, and also reduces the cost of high-volume runs. Its categorical power is brittle. Building the prompt Each predictive task sent to an LLM starts with a prompt template.
Users can easily constrain an LLM’s output with clever promptengineering. That minimizes the chance that the prompt will overrun the context window, and also reduces the cost of high-volume runs. Its categorical power is brittle. Building the prompt Each predictive task sent to an LLM starts with a prompt template.
Users can easily constrain an LLM’s output with clever promptengineering. That minimizes the chance that the prompt will overrun the context window, and also reduces the cost of high-volume runs. Its categorical power is brittle. Building the prompt Each predictive task sent to an LLM starts with a prompt template.
Classification techniques, such as image recognition and documentcategorization, remain essential for a wide range of industries. Classification techniques like random forests, decision trees, and support vector machines are among the most widely used, enabling tasks such as categorizing data and building predictive models.
It quickly became the focal point for large language model research (you’ll see it referenced many times in this document), and served as the original underpinning of ChatGPT. Embeddings are also used to represent larger textual units, such as sentences, paragraphs, or entire documents. Most recently, OpenAI debuted GPT-4.
It quickly became the focal point for large language model research (you’ll see it referenced many times in this document), and served as the original underpinning of ChatGPT. Embeddings are also used to represent larger textual units, such as sentences, paragraphs, or entire documents. Most recently, OpenAI debuted GPT-4.
In the image above, you can see on the left that categorical “overlap” is sometimes intentional. For instance, you can first classify documents by type. Then, depending on the type, you can classify a smaller set of intents specifically for that document type. Both can produce unclear distinctions between classes.
In the image above, you can see on the left that categorical “overlap” is sometimes intentional. For instance, you can first classify documents by type. Then, depending on the type, you can classify a smaller set of intents specifically for that document type. Both can produce unclear distinctions between classes.
Types of summarizations There are several techniques to summarize text, which are broadly categorized into two main approaches: extractive and abstractive summarization. Given their versatile nature, these models require specific task instructions provided through input text, a practice referred to as promptengineering.
To install and import the library, use the following commands: pip install -q transformers from transformers import pipeline Having done that, you can execute NLP tasks starting with sentiment analysis, which categorizes text into positive or negative sentiments.
These advances have fueled applications in document creation, chatbot dialogue systems, and even synthetic music composition. An example would be customizing T5 to generate summaries for documents in a specific industry. Recent Big-Tech decisions underscore its significance.
These sources can be categorized into three types: textual documents (e.g., Techniques like Uprise and DaSLaM use lightweight retrievers or small models to optimize prompts, break down complex problems, or generate pseudo labels. KD methods can be categorized into white-box and black-box approaches.
Key strengths of VLP include the effective utilization of pre-trained VLMs and LLMs, enabling zero-shot or few-shot predictions without necessitating task-specific modifications, and categorizing images from a broad spectrum through casual multi-round dialogues. of OBELICS multimodal web documents. of image-text pairs and 30.7%
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content