This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Natural Language Processing (NLP) Once speech becomes text, natural language processing, or NLP, models analyze the actual meaning. NLP identifies sentence structure and maps relationships between statements. Healthcare operations Voice intelligence streamlines documentation while improving patient care.
Transformers in NLP In 2017, Cornell University published an influential paper that introduced transformers. These are deep learning models used in NLP. Hugging Face , started in 2016, aims to make NLP models accessible to everyone. This discovery fueled the development of large language models like ChatGPT.
Types of summarizations There are several techniques to summarize text, which are broadly categorized into two main approaches: extractive and abstractive summarization. Extractive summarization Extractive summarization is a technique used in NLP and text analysis to create a summary by extracting key sentences.
This article explores an innovative way to streamline the estimation of Scope 3 GHG emissions leveraging AI and Large Language Models (LLMs) to help categorize financial transaction data to align with spend-based emissions factors. Why are Scope 3 emissions difficult to calculate?
Natural Language Processing (NLP) is a rapidly growing field that deals with the interaction between computers and human language. As NLP continues to advance, there is a growing need for skilled professionals to develop innovative solutions for various applications, such as chatbots, sentiment analysis, and machine translation.
This advancement has spurred the commercial use of generative AI in natural language processing (NLP) and computer vision, enabling automated and intelligent data extraction. Named Entity Recognition ( NER) Named entity recognition (NER), an NLP technique, identifies and categorizes key information in text.
Based on this, it makes an educated guess about the importance of incoming emails, and categorizes them into specific folders. In addition to the smart categorization of emails, SaneBox also comes with a feature named SaneBlackHole, designed to banish unwanted emails.
The latest version of Legal NLP comes with a new classification model on Law Stack Exchange questions and Named-Entity Recognition on Subpoenas. setInputCols(["document", "token"]).setOutputCol("class") setOutputCol("class") ) With the model, questions can be categorized.
Natural Language Processing (NLP) is integral to artificial intelligence, enabling seamless communication between humans and computers. This interdisciplinary field incorporates linguistics, computer science, and mathematics, facilitating automatic translation, text categorization, and sentiment analysis.
Natural language processing ( NLP ), while hardly a new discipline, has catapulted into the public consciousness these past few months thanks in large part to the generative AI hype train that is ChatGPT. ‘Data-centric’ NLP With NLP one of the hot AI trends of the moment, Kern AI today announced that it has raised €2.7
In today’s information age, the vast volumes of data housed in countless documents present both a challenge and an opportunity for businesses. Traditional document processing methods often fall short in efficiency and accuracy, leaving room for innovation, cost-efficiency, and optimizations. However, the potential doesn’t end there.
We are delighted to announce a suite of remarkable enhancements and updates in our latest release of Healthcare NLP. setInputCols(["document"]).setOutputCol("sql") Text2SQL , module to translate text prompts into accurate SQL queries We are excited to introduce our latest innovation, the Text2SQL annotator.
In Natural Language Processing (NLP) tasks, data cleaning is an essential step before tokenization, particularly when working with text data that contains unusual word separations such as underscores, slashes, or other symbols in place of spaces. The post Is There a Library for Cleaning Data before Tokenization?
This NLP clinical solution collects data for administrative coding tasks, quality improvement, patient registry functions, and clinical research. Second, the information is frequently derived from natural language documents or a combination of structured, imaging, and document sources.
This blog post explores how John Snow Labs’ Healthcare NLP & LLM library is transforming clinical trials by using advanced NER models to efficiently filter through large datasets of patient records. link] John Snow Labs’ Healthcare NLP & LLM library offers a powerful solution to streamline this process.
The ability to effectively handle and process enormous amounts of documents has become essential for enterprises in the modern world. Due to the continuous influx of information that all enterprises deal with, manually classifying documents is no longer a viable option.
And retailers frequently leverage data from chatbots and virtual assistants, in concert with ML and natural language processing (NLP) technology, to automate users’ shopping experiences. K-means clustering is commonly used for market segmentation, document clustering, image segmentation and image compression.
Companies in sectors like healthcare, finance, legal, retail, and manufacturing frequently handle large numbers of documents as part of their day-to-day operations. These documents often contain vital information that drives timely decision-making, essential for ensuring top-tier customer satisfaction, and reduced customer churn.
This article will delve into the significance of NER (Named Entity Recognition) detection in OCR (Optical Character Recognition) and showcase its application through the John Snow Labs NLP library with visual features installed. How does Visual NLP come into action? What are the components that will be used for NER in Visual NLP?
In the evolving field of natural language processing (NLP), data labeling remains a critical step in training machine learning models. Consider key factors suchas: Accuracy : Does the model correctly categorize or extract information? For detailed steps, refer to Datasaurs LLM Sandbox documentation.
Text mining —also called text data mining—is an advanced discipline within data science that uses natural language processing (NLP) , artificial intelligence (AI) and machine learning models, and data mining techniques to derive pertinent qualitative information from unstructured text data. What is text mining?
BERT by Google Summary In 2018, the Google AI team introduced a new cutting-edge model for Natural Language Processing (NLP) – BERT , or B idirectional E ncoder R epresentations from T ransformers. This model marked a new era in NLP with pre-training of language models becoming a new standard. What is the goal? accuracy on SQuAD 1.1
Broadly, Python speech recognition and Speech-to-Text solutions can be categorized into two main types: open-source libraries and cloud-based services. Sphinx is relatively lightweight compared to other speech-to-text solutions, supports multiple languages, and offers extensive developer documentation and FAQs.
Foundation models can be trained to perform tasks such as data classification, the identification of objects within images (computer vision) and natural language processing (NLP) (understanding and generating text) with a high degree of accuracy. An open-source model, Google created BERT in 2018. All watsonx.ai
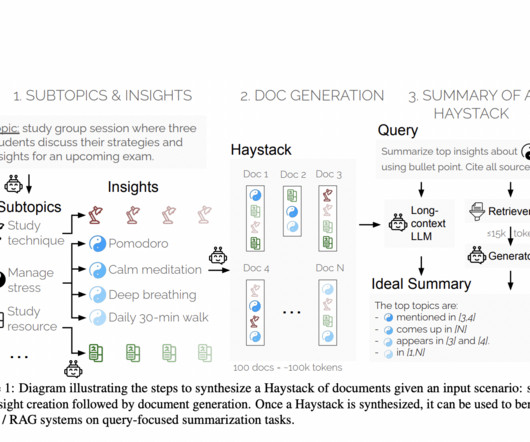
Natural language processing (NLP) in artificial intelligence focuses on enabling machines to understand and generate human language. One of the major challenges in NLP is effectively evaluating the performance of LLMs on tasks that require processing long contexts. The methodology involves several detailed steps.
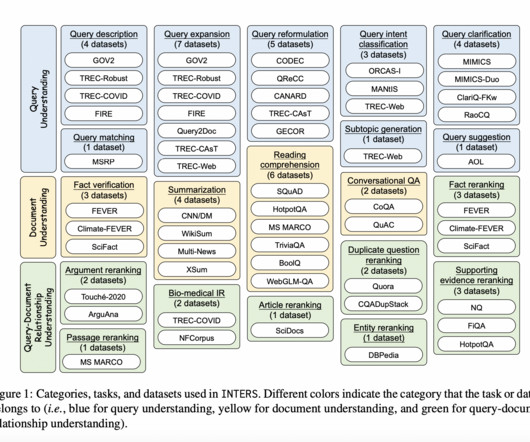
This dataset focuses on three pivotal aspects prevalent in search-related tasks: query understanding, document understanding, and the intricate relationship between queries and documents. In the context of search tasks, distinct from typical NLP tasks, the focus revolves around queries and documents.
AI-powered tools offer the capability to navigate vast databases, analyze clinical research data, streamline document searches, and access worldwide regulatory news. One notable innovation in regulatory monitoring is the integration of natural language processing (NLP) and machine learning algorithms.
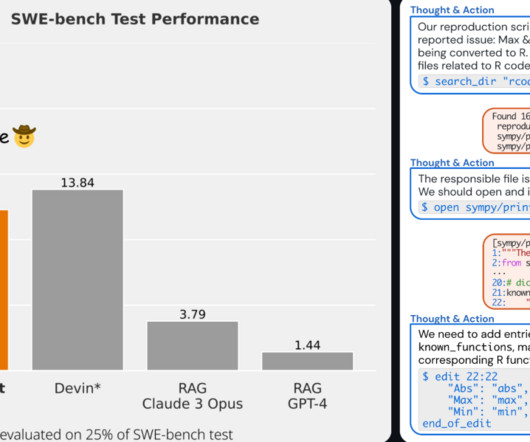
The emergence of AI-powered software engineers, such as SWE-Agent developed by Princeton University's NLP group, Devin AI, represents a groundbreaking shift in how software is designed, developed, and maintained. Described as an AI-powered programming companion, it presents auto-complete suggestions during code development.
Many companies across all industries still rely on laborious, error-prone, manual procedures to handle documents, especially those that are sent to them by email. Intelligent automation presents a chance to revolutionize document workflows across sectors through digitization and process optimization.
Amazon Comprehend is a natural-language processing (NLP) service that uses machine learning to uncover valuable insights and connections in text. Knowledge management – Categorizingdocuments in a systematic way helps to organize an organization’s knowledge base. politics, sports) that a document belongs to.
Where interpreting raw financial data has become easier NLP, it is also helping us make better predictions and financial decisions. NLP in finance includes semantic analysis, information extraction, and text analysis. Within NLP, data labeling allows machine learning models to isolate finance-related variables in different datasets.
Text embeddings are vector representations of words, sentences, paragraphs or documents that capture their semantic meaning. They serve as a core building block in many natural language processing (NLP) applications today, including information retrieval, question answering, semantic search and more.
Using Natural Language Processing (NLP) and the latest AI models, Perplexity AI moves beyond keyword matching to understand the meaning behind questions. Here's what Perplexity can do: Summarize content: Condense lengthy articles, documents, and webpages into concise summaries to grasp key points quickly.
Now that artificial intelligence has become more widely accepted, some daring companies are looking at natural language processing (NLP) technology as the solution. Naturally, its high penetration rate has given way to exploration into machine learning subsets like deep learning and NLP. What Is Compliance Monitoring in Banking?
Be sure to check out his talk, “ Bagging to BERT — A Tour of Applied NLP ,” there! If a Natural Language Processing (NLP) system does not have that context, we’d expect it not to get the joke. identifying the “emotional tone” of a particular document). identifying the “emotional tone” of a particular document).
Manually analyzing and categorizing large volumes of unstructured data, such as reviews, comments, and emails, is a time-consuming process prone to inconsistencies and subjectivity. By using the pre-trained knowledge of LLMs, zero-shot and few-shot approaches enable models to perform NLP with minimal or no labeled data.
Words and phrases can be effectively represented as vectors in a high-dimensional space using embeddings, making them a crucial tool in the field of natural language processing (NLP). For very large documents or vocabulary sizes, this matrix can become unmanageably enormous.
image source: stoodnt Time is important in the broad domain of legal discovery, where mountains of documents hide the answers to difficult cases. Every minute spent digesting jargon-filled texts and searching through mountains of legal documents delays justice and incurs significant costs.
Using natural language processing (NLP) and OpenAPI specs, Amazon Bedrock Agents dynamically manages API sequences, minimizing dependency management complexities. The policy agent accesses the Policy Information API to extract answers to insurance-related questions from unstructured policy documents such as PDF files.
Fine-tuning is a powerful approach in natural language processing (NLP) and generative AI , allowing businesses to tailor pre-trained large language models (LLMs) for specific tasks. This process involves updating the model’s weights to improve its performance on targeted applications.
These advances have fueled applications in document creation, chatbot dialogue systems, and even synthetic music composition. An example would be customizing T5 to generate summaries for documents in a specific industry. Recent Big-Tech decisions underscore its significance. How Are LLMs Used?
Natural Language Processing ( NLP ) is changing the way the legal sector operates. According to a report, the NLP market size is expected to reach $27.6 Organizing documents, and looking for specific information in huge amounts of documents can be frustrating for lawyers and their clients. billion by 2026.
Large language models (LLMs) have achieved amazing results in a variety of Natural Language Processing (NLP), Natural Language Understanding (NLU) and Natural Language Generation (NLG) tasks in recent years. The team has performed a thorough study and categorization of numerous contemporary research projects that make use of these tactics.
Introduction to Pretrained Zero-Shot NER for Healthcare NLP Named Entity Recognition (NER) is a cornerstone of NLP tasks, yet traditional NER approaches often require extensive domain-specific training to achieve high performance. Step 1: Set Up the Environment First, we need to set up the Spark NLP Healthcare library.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































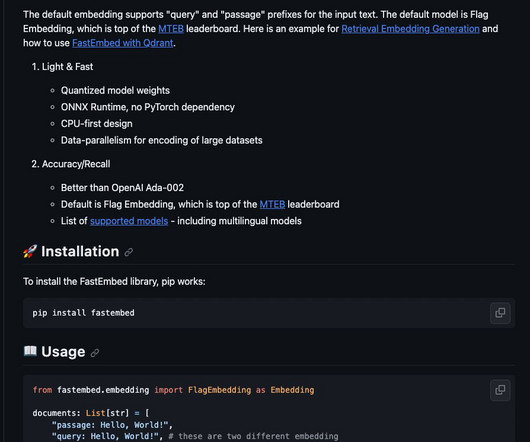












Let's personalize your content