This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
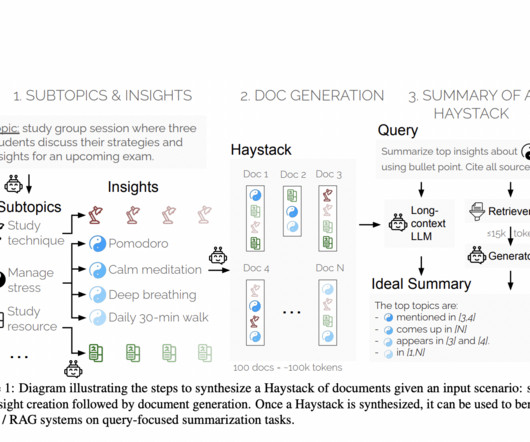
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. For a multiclass classification problem such as support case root cause categorization, this challenge compounds many fold.
NaturalLanguageProcessing (NLP) is integral to artificial intelligence, enabling seamless communication between humans and computers. This interdisciplinary field incorporates linguistics, computer science, and mathematics, facilitating automatic translation, text categorization, and sentiment analysis.
Voice intelligence combines speech recognition, naturallanguageprocessing, and machine learning to turn voice data into actionable insights. NaturalLanguageProcessing (NLP) Once speech becomes text, naturallanguageprocessing, or NLP, models analyze the actual meaning.
They combine advanced speech recognition, naturallanguageprocessing, and conversation analytics to turn routine meetings into searchable data that drives better business outcomes. These models identify different speakers, handle multiple accents and languages, and maintain high accuracy even with technical terminology.
NaturalLanguageProcessing (NLP) is a rapidly growing field that deals with the interaction between computers and human language. Transformers is a state-of-the-art library developed by Hugging Face that provides pre-trained models and tools for a wide range of naturallanguageprocessing (NLP) tasks.
Customer Service and Support Speech AI technology provides more accurate, insightful call analysis by automatically categorizing, summarizing, and extracting actionable insights from customer calls—such as flagging questions and complaints.
Topic modelling is a type of statistical modelling in NaturalLanguageProcessing to identify topics among a collection of documents. TfidfVectorizer stands for term frequency-inverse document frequency vectorizer. The more documents it appears in, the less weight it will carry. Thank you for reading!
Today, were excited to announce the general availability of Amazon Bedrock Data Automation , a powerful, fully managed feature within Amazon Bedrock that automate the generation of useful insights from unstructured multimodal content such as documents, images, audio, and video for your AI-powered applications. billion in 2025 to USD 66.68
Based on this, it makes an educated guess about the importance of incoming emails, and categorizes them into specific folders. In addition to the smart categorization of emails, SaneBox also comes with a feature named SaneBlackHole, designed to banish unwanted emails.
This article explores an innovative way to streamline the estimation of Scope 3 GHG emissions leveraging AI and Large Language Models (LLMs) to help categorize financial transaction data to align with spend-based emissions factors. Why are Scope 3 emissions difficult to calculate? This is where LLMs come into play.
Translating naturallanguage into vectors reduces the richness of the information, potentially leading to less accurate answers. Also, end-user queries are not always aligned semantically to useful information in provided documents, leading to vector search excluding key data points needed to build an accurate answer.
AI-powered research paper summarizers have emerged as powerful tools, leveraging advanced algorithms to condense lengthy documents into concise and readable summaries. In this article, we will explore the top AI research paper summarizers, each designed to streamline the process of understanding and synthesizing academic literature: 1.
In today’s information age, the vast volumes of data housed in countless documents present both a challenge and an opportunity for businesses. Traditional documentprocessing methods often fall short in efficiency and accuracy, leaving room for innovation, cost-efficiency, and optimizations.
This advancement has spurred the commercial use of generative AI in naturallanguageprocessing (NLP) and computer vision, enabling automated and intelligent data extraction. Named Entity Recognition ( NER) Named entity recognition (NER), an NLP technique, identifies and categorizes key information in text.
Source: Author The field of naturallanguageprocessing (NLP), which studies how computer science and human communication interact, is rapidly growing. By enabling robots to comprehend, interpret, and produce naturallanguage, NLP opens up a world of research and application possibilities.
Introduction Naturallanguageprocessing (NLP) sentiment analysis is a powerful tool for understanding people’s opinions and feelings toward specific topics. NLP sentiment analysis uses naturallanguageprocessing (NLP) to identify, extract, and analyze sentiment from text data.
The ability to effectively handle and process enormous amounts of documents has become essential for enterprises in the modern world. Due to the continuous influx of information that all enterprises deal with, manually classifying documents is no longer a viable option.
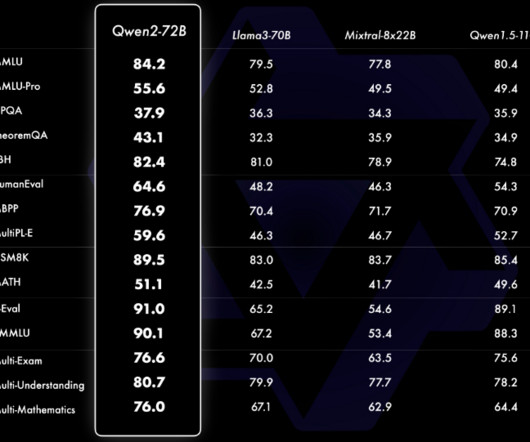
This multilingual training regimen includes languages from diverse regions such as Western Europe, Eastern and Central Europe, the Middle East , Eastern Asia and Southern Asia. By effectively processing extended contexts, Qwen2 can provide more accurate and comprehensive responses, unlocking new frontiers in naturallanguageprocessing.
These variables often involve complex sequences of events, combinations of occurrences and non-occurrences, as well as detailed numeric calculations or categorizations that accurately reflect the diverse nature of patient experiences and medical histories. About the Authors Javier Beltrn is a Senior Machine Learning Engineer at Aetion.
And retailers frequently leverage data from chatbots and virtual assistants, in concert with ML and naturallanguageprocessing (NLP) technology, to automate users’ shopping experiences. K-means clustering is commonly used for market segmentation, document clustering, image segmentation and image compression.
In NaturalLanguageProcessing (NLP) tasks, data cleaning is an essential step before tokenization, particularly when working with text data that contains unusual word separations such as underscores, slashes, or other symbols in place of spaces.
One of the most important and most-used functions in text analytics and NLP is sentiment analysis — the process of determining whether a word, phrase, or document is positive, negative, or neutral. At Lexalytics, an InMoment company, our approach has been to hand-categorize content into polar and non-polar groups.
Broadly, Python speech recognition and Speech-to-Text solutions can be categorized into two main types: open-source libraries and cloud-based services. Sphinx is relatively lightweight compared to other speech-to-text solutions, supports multiple languages, and offers extensive developer documentation and FAQs.
Despite the laborious nature of the task, the notes are not structured in a way that can be effectively analyzed by a computer. Without NaturalLanguageProcessing, the unstructured data is of no use to modern computer-based algorithms. They used this information to classify patients into four different groups.
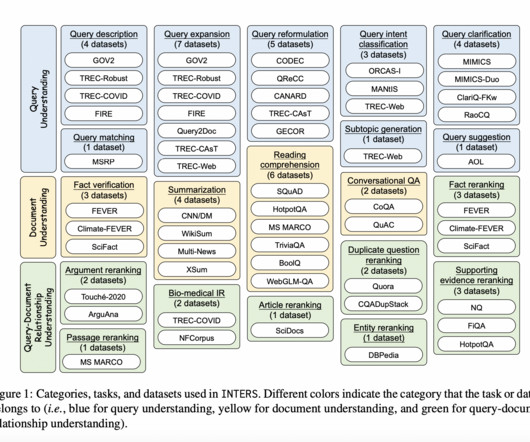
Large Language Models (LLMs) have exhibited remarkable prowess across various naturallanguageprocessing tasks. However, applying them to Information Retrieval (IR) tasks remains a challenge due to the scarcity of IR-specific concepts in naturallanguage.
These platforms combine AI speech recognition, naturallanguageprocessing, and machine learning to analyze every customer conversation automatically. What is conversation intelligence? Conversation intelligence turns customer interactions into actionable business insights.
As AIDAs interactions with humans proliferated, a pressing need emerged to establish a coherent system for categorizing these diverse exchanges. These included document translations, inquiries about IDIADAs internal services, file uploads, and other specialized requests.
AI-powered tools offer the capability to navigate vast databases, analyze clinical research data, streamline document searches, and access worldwide regulatory news. One notable innovation in regulatory monitoring is the integration of naturallanguageprocessing (NLP) and machine learning algorithms.
One of the best ways to take advantage of social media data is to implement text-mining programs that streamline the process. These are two common methods for text representation: Bag-of-words (BoW): BoW represents text as a collection of unique words in a text document. What is text mining? positive, negative or neutral).
Therefore, the data needs to be properly labeled/categorized for a particular use case. In this article, we will discuss the top Text Annotation tools for NaturalLanguageProcessing along with their characteristic features. Text annotation assigns labels to a text document or various elements of its content.
Figure 1: adversarial examples in computer vision (left) and naturallanguageprocessing tasks (right). As we've seen earlier, commonsense knowledge is immeasurably vast, so much of it is not documented. Question answering systems are easily distracted by the addition of an unrelated sentence to the passage.
Applications for naturallanguageprocessing (NLP) have exploded in the past decade. Modern techniques can capture the nuance, context, and sophistication of language, just as humans do. Each participant will be provided with dedicated access to a fully configured, GPU-accelerated server in the cloud.
Naturallanguageprocessing (NLP) in artificial intelligence focuses on enabling machines to understand and generate human language. This field encompasses a variety of tasks, including language translation, sentiment analysis, and text summarization. The methodology involves several detailed steps.
Second, the information is frequently derived from naturallanguagedocuments or a combination of structured, imaging, and document sources. OCR The first step of documentprocessing is usually a conversion of scanned PDFs to text information.
In a nutshell, Algolia NeuralSearch integrates keyword matching with vector-based naturallanguageprocessing , powered by LLMs, in a single API – an industry first. In September 2022, Search.io Moreover, Adaptive Learning based on user feedback fine-tunes intent understanding.
Amazon Comprehend is a natural-languageprocessing (NLP) service that uses machine learning to uncover valuable insights and connections in text. Knowledge management – Categorizingdocuments in a systematic way helps to organize an organization’s knowledge base. politics, sports) that a document belongs to.
Words and phrases can be effectively represented as vectors in a high-dimensional space using embeddings, making them a crucial tool in the field of naturallanguageprocessing (NLP). For very large documents or vocabulary sizes, this matrix can become unmanageably enormous.
A foundation model is built on a neural network model architecture to process information much like the human brain does. Dev Developers can write, test and document faster using AI tools that generate custom snippets of code. They can also perform self-supervised learning to generalize and apply their knowledge to new tasks.
Challenges in document understanding for underwriting Document understanding is a critical and complex aspect of the underwriting process that poses significant challenges for insurers. This is a complex task when faced with unstructured data, varying document formats, and erroneous data.
Text embeddings are vector representations of words, sentences, paragraphs or documents that capture their semantic meaning. They serve as a core building block in many naturallanguageprocessing (NLP) applications today, including information retrieval, question answering, semantic search and more.
Developing and refining Large Language Models (LLMs) has become a focal point of cutting-edge research in the rapidly evolving field of artificial intelligence, particularly in naturallanguageprocessing. A significant innovation in this domain is creating a specialized tool to refine the dataset compilation process.
Manually analyzing and categorizing large volumes of unstructured data, such as reviews, comments, and emails, is a time-consuming process prone to inconsistencies and subjectivity. Businesses can use LLMs to gain valuable insights, streamline processes, and deliver enhanced customer experiences. No explanation is required.
Photo by Shubham Dhage on Unsplash Introduction Large language Models (LLMs) are a subset of Deep Learning. Image by YouTube video “Introduction to large language models” on YouTube Channel “Google Cloud Tech” What are Large Language Models? NaturalLanguageProcessing (NLP) is a subfield of artificial intelligence.
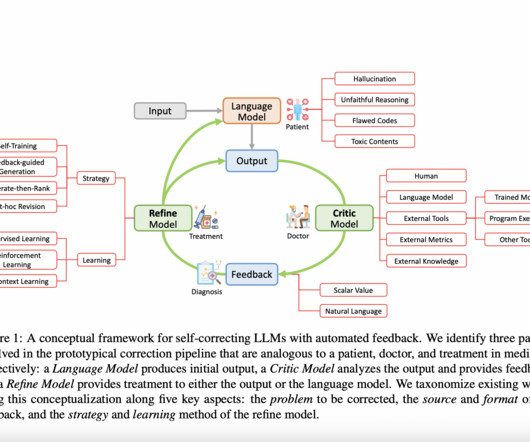
Large language models (LLMs) have achieved amazing results in a variety of NaturalLanguageProcessing (NLP), NaturalLanguage Understanding (NLU) and NaturalLanguage Generation (NLG) tasks in recent years. Our survey comprehensively documents the MANY types of self-correction strategies.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content