This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Today, were excited to announce the general availability of Amazon Bedrock Data Automation , a powerful, fully managed feature within Amazon Bedrock that automate the generation of useful insights from unstructured multimodal content such as documents, images, audio, and video for your AI-powered applications. billion in 2025 to USD 66.68
In this post, we focus on one such complex workflow: document processing. Rule-based systems or specialized machine learning (ML) models often struggle with the variability of real-world documents, especially when dealing with semi-structured and unstructured data.
Organizations across industries want to categorize and extract insights from high volumes of documents of different formats. Manually processing these documents to classify and extract information remains expensive, error prone, and difficult to scale. Categorizingdocuments is an important first step in IDP systems.
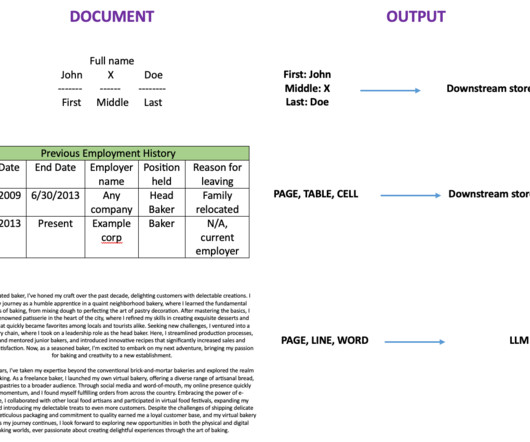
An intelligent document processing (IDP) project usually combines optical character recognition (OCR) and natural language processing (NLP) to read and understand a document and extract specific terms or words. This post focuses on the Cost Optimization pillar of the IDP solution.
In today’s information age, the vast volumes of data housed in countless documents present both a challenge and an opportunity for businesses. Traditional document processing methods often fall short in efficiency and accuracy, leaving room for innovation, cost-efficiency, and optimizations. However, the potential doesn’t end there.
Companies in sectors like healthcare, finance, legal, retail, and manufacturing frequently handle large numbers of documents as part of their day-to-day operations. These documents often contain vital information that drives timely decision-making, essential for ensuring top-tier customer satisfaction, and reduced customer churn.
Data classification, extraction, and analysis can be challenging for organizations that deal with volumes of documents. Traditional document processing solutions are manual, expensive, error prone, and difficult to scale. FMs are transforming the way you can solve traditionally complex document processing workloads.
Many companies across all industries still rely on laborious, error-prone, manual procedures to handle documents, especially those that are sent to them by email. Intelligent automation presents a chance to revolutionize document workflows across sectors through digitization and process optimization.
With this new feature, you can use your own identity provider (IdP) such as Okta , Azure AD , or Ping Federate to connect to Snowflake via Data Wrangler. Solution overview In the following sections, we provide steps for an administrator to set up the IdP, Snowflake, and Studio. Provide the users within the IdP access to Data Wrangler.
The following use cases are well-suited for prompt caching: Chat with document By caching the document as input context on the first request, each user query becomes more efficient, enabling simpler architectures that avoid heavier solutions like vector databases. Please follow these detailed instructions:" "nn1.
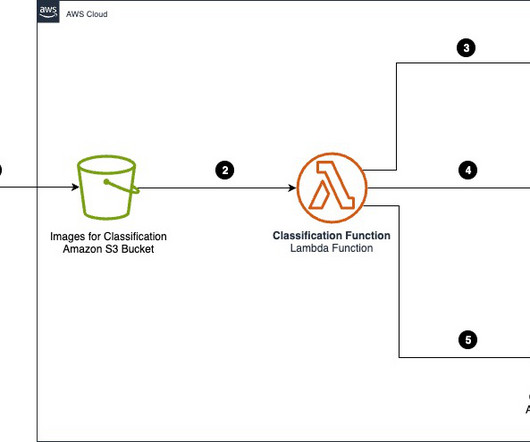
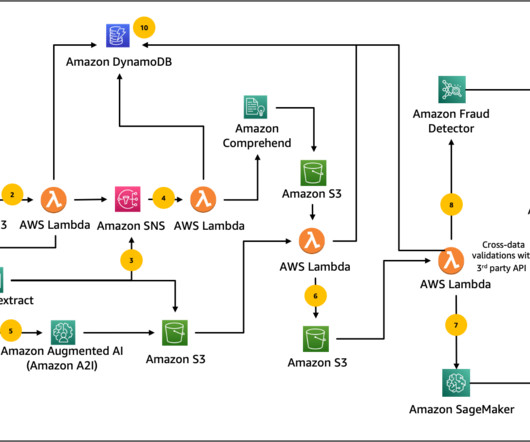
In this three-part series, we present a solution that demonstrates how you can automate detecting document tampering and fraud at scale using AWS AI and machine learning (ML) services for a mortgage underwriting use case. Fraudsters range from blundering novices to near-perfect masters when creating fraudulent loan application documents.
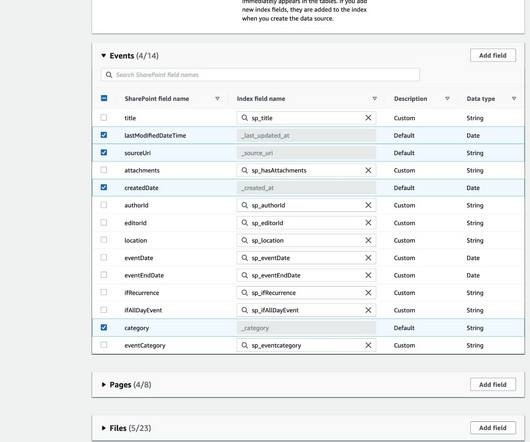
If you use an email ID with domain form IDP as the ACL setting, the LDAP server endpoint, search base, LDAP user name, and LDAP password are also required. You can also include or exclude documents by using regular expressions. In this next step, you can create field mappings to add an extra layer of metadata to your documents.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















Let's personalize your content