
Unlocking Key Technologies in Document Parsing
Towards AI
NOVEMBER 7, 2024
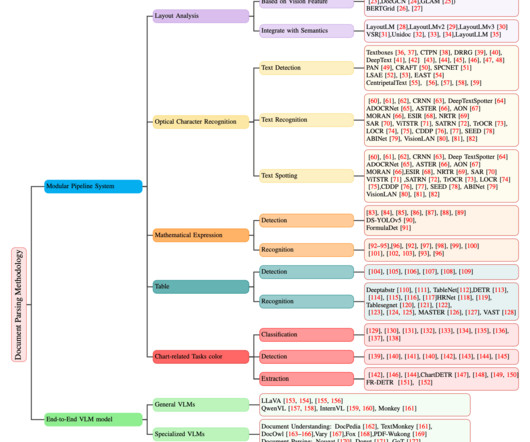
A large number of documents — including technical documentation, historical records, academic publications, and legal files — exist in scanned or image formats. This presents significant challenges for downstream tasks like Retrieval-Augmented Generation (RAG), information extraction, and document understanding.





































Let's personalize your content