This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
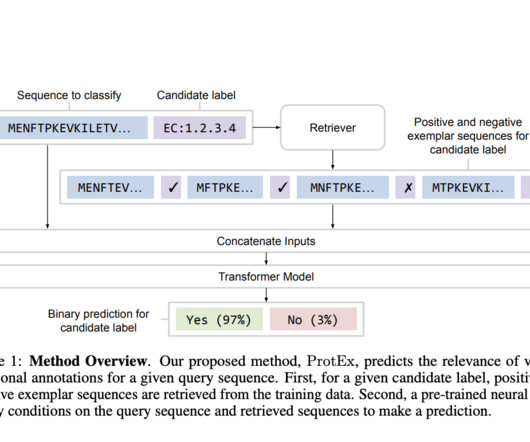
Functions are categorized using ontologies like Gene Ontology (GO) terms, Enzyme Commission (EC) numbers, and Pfam families. Techniques include homology-based methods, which use sequence alignment tools like BLAST to infer function, and deeplearning methods, which predict functions directly from sequences.
This article explores an innovative way to streamline the estimation of Scope 3 GHG emissions leveraging AI and Large Language Models (LLMs) to help categorize financial transaction data to align with spend-based emissions factors. Why are Scope 3 emissions difficult to calculate?
Natural Language Processing (NLP) is a rapidly growing field that deals with the interaction between computers and human language. As NLP continues to advance, there is a growing need for skilled professionals to develop innovative solutions for various applications, such as chatbots, sentiment analysis, and machine translation.
Based on this, it makes an educated guess about the importance of incoming emails, and categorizes them into specific folders. In addition to the smart categorization of emails, SaneBox also comes with a feature named SaneBlackHole, designed to banish unwanted emails.
Blockchain technology can be categorized primarily on the basis of the level of accessibility and control they offer, with Public, Private, and Federated being the three main types of blockchain technologies. Deeplearning frameworks can be classified into two categories: Supervised learning, and Unsupervised learning.
Be sure to check out his talk, “ Bagging to BERT — A Tour of Applied NLP ,” there! If a Natural Language Processing (NLP) system does not have that context, we’d expect it not to get the joke. In this post, I’ll be demonstrating two deeplearning approaches to sentiment analysis. deep” architecture).
They allow the network to focus on different aspects of complex input individually until the entire data set is categorized. This approach […] The post Learn Attention Models From Scratch appeared first on Analytics Vidhya. The goal is to break down complex tasks into smaller areas of attention that are processed sequentially.
Natural Language Processing (NLP) is integral to artificial intelligence, enabling seamless communication between humans and computers. This interdisciplinary field incorporates linguistics, computer science, and mathematics, facilitating automatic translation, text categorization, and sentiment analysis.
With nine times the speed of the Nvidia A100, these GPUs excel in handling deeplearning workloads. This advancement has spurred the commercial use of generative AI in natural language processing (NLP) and computer vision, enabling automated and intelligent data extraction.
Beyond the simplistic chat bubble of conversational AI lies a complex blend of technologies, with natural language processing (NLP) taking center stage. NLP translates the user’s words into machine actions, enabling machines to understand and respond to customer inquiries accurately. What makes a good AI conversationalist?
Sentiment analysis, also known as opinion mining, is the process of computationally identifying and categorizing the subjective information contained in natural language text. Deeplearning models can automatically learn features and representations from raw text data, making them well-suited for sentiment analysis tasks.
With advancements in deeplearning, natural language processing (NLP), and AI, we are in a time period where AI agents could form a significant portion of the global workforce. Neural Networks & DeepLearning : Neural networks marked a turning point, mimicking human brain functions and evolving through experience.
And retailers frequently leverage data from chatbots and virtual assistants, in concert with ML and natural language processing (NLP) technology, to automate users’ shopping experiences. A semi-supervised learning model might use unsupervised learning to identify data clusters and then use supervised learning to label the clusters.
NLP models in commercial applications such as text generation systems have experienced great interest among the user. These models have achieved various groundbreaking results in many NLP tasks like question-answering, summarization, language translation, classification, paraphrasing, et cetera.
This tagging structure categorizes costs and allows assessment of usage against budgets. ListTagsForResource : Fetches the tags associated with a specific Bedrock resource, helping users understand how their resources are categorized. He focuses on Deeplearning including NLP and Computer Vision domains.
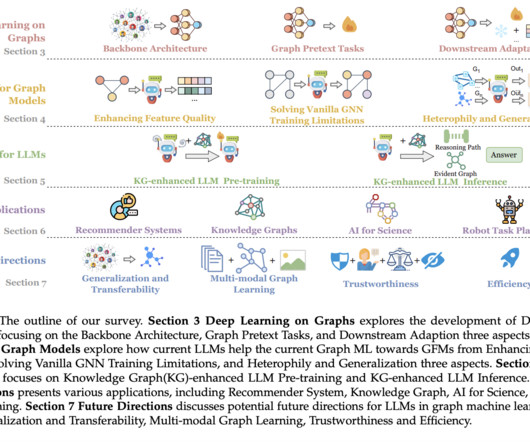
Graph Machine Learning (Graph ML), especially Graph Neural Networks (GNNs), has emerged to effectively model such data, utilizing deeplearning’s message-passing mechanism to capture high-order relationships. Foundation Models (FMs) have revolutionized NLP and vision domains in the broader AI spectrum.
Text mining —also called text data mining—is an advanced discipline within data science that uses natural language processing (NLP) , artificial intelligence (AI) and machine learning models, and data mining techniques to derive pertinent qualitative information from unstructured text data. What is text mining?
BERT by Google Summary In 2018, the Google AI team introduced a new cutting-edge model for Natural Language Processing (NLP) – BERT , or B idirectional E ncoder R epresentations from T ransformers. This model marked a new era in NLP with pre-training of language models becoming a new standard. Where to learn more about this research?
Third, the NLP Preset is capable of combining tabular data with NLP or Natural Language Processing tools including pre-trained deeplearning models and specific feature extractors. Finally, the CV Preset works with image data with the help of some basic tools.
It’s the underlying engine that gives generative models the enhanced reasoning and deeplearning capabilities that traditional machine learning models lack. They can also perform self-supervised learning to generalize and apply their knowledge to new tasks. That’s where the foundation model enters the picture.
Photo by Shubham Dhage on Unsplash Introduction Large language Models (LLMs) are a subset of DeepLearning. Some Terminologies related to Artificial Intelligence (Ai) DeepLearning is a technique used in artificial intelligence (AI) that teaches computers to interpret data in a manner modeled after the human brain.
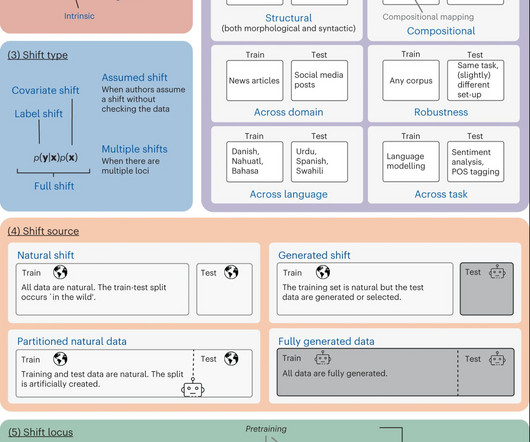
A model’s capacity to generalize or effectively apply its learned knowledge to new contexts is essential to the ongoing success of Natural Language Processing (NLP). To address that, a group of researchers from Meta has proposed a thorough taxonomy to describe and comprehend NLP generalization research.
Deeplearning is a branch of machine learning that makes use of neural networks with numerous layers to discover intricate data patterns. Deeplearning models use artificial neural networks to learn from data. It is a tremendous tool with the ability to completely alter numerous sectors.
now features deeplearning models for named entity recognition, dependency parsing, text classification and similarity prediction based on the architectures described in this post. You can now also create training and evaluation data for these models with Prodigy , our new active learning-powered annotation tool.
Natural language processing (NLP) can help with this. In this post, we’ll look at how natural language processing (NLP) may be utilized to create smart chatbots that can comprehend and reply to natural language requests. What is NLP? Sentiment analysis, language translation, and speech recognition are a few NLP applications.
Users can review different types of events such as security, connectivity, system, and management, each categorized by specific criteria like threat protection, LAN monitoring, and firmware updates. For example, the following screenshot shows a time filter for UTC.2024-10-{01/00:00:00--02/00:00:00}. 2024-10-{01/00:00:00--02/00:00:00}.
Now that artificial intelligence has become more widely accepted, some daring companies are looking at natural language processing (NLP) technology as the solution. Naturally, its high penetration rate has given way to exploration into machine learning subsets like deeplearning and NLP.
The identification of regularities in data can then be used to make predictions, categorize information, and improve decision-making processes. While explorative pattern recognition aims to identify data patterns in general, descriptive pattern recognition starts by categorizing the detected patterns. – Learn more.
This enhances the interpretability of AI systems for applications in computer vision and natural language processing (NLP). The introduction of the Transformer model was a significant leap forward for the concept of attention in deeplearning. Vaswani et al. It does this by applying self-attention to sequences of image patches.
A practical guide on how to perform NLP tasks with Hugging Face Pipelines Image by Canva With the libraries developed recently, it has become easier to perform deeplearning analysis. Hugging Face is a platform that provides pre-trained language models for NLP tasks such as text classification, sentiment analysis, and more.
Enter Natural Language Processing (NLP) and its transformational power. This is the promise of NLP: to transform the way we approach legal discovery. The seemingly impossible chore of sorting through mountains of legal documents can be accomplished with astonishing efficiency and precision using NLP.
It automatically categorizes, summarizes, and extracts actionable insights from customer calls, such as flagging questions and complaints. It uses state-of-the-art deeplearning models trained on diverse, large datasets to catch subtle patterns in speech that may indicate depression or anxiety. For example, Corti.ai
Large Language Models, or LLMs , are Machine Learning models that understand, generate, and interact with human language. Its AI Conversational Intelligence feature also helps its customers more efficiently process call data at scale by auto-scoring and categorizing key sections of customer calls.
Natural Language Processing ( NLP ) is changing the way the legal sector operates. According to a report, the NLP market size is expected to reach $27.6 NLP understands and predicts law, converts unstructured text into a meaningful format that computers can understand and analyze. billion by 2026. are entity categories.
The recent results of machine learning in drug discovery have been largely attributed to graph and geometric deeplearning models. Like other deeplearning techniques, they need a lot of training data to provide excellent modeling accuracy.
They are experts in machine learning, NLP, deeplearning, data engineering, MLOps, and data visualization. Learn more about a few of our ODSC East 2023 instructors, their backgrounds in education, and why they’re fit for imparting their knowledge. Dr. Jon Krohn Chief Data Scientist | Nebula.io
Achieving these feats is accomplished through a combination of sophisticated algorithms, natural language processing (NLP) and computer science principles. NLP techniques help them parse the nuances of human language, including grammar, syntax and context. Most experts categorize it as a powerful, but narrow AI model.
With courses ranging in skill level from beginner to advanced and covering topics such as machine learning, NLP, MLOps, data engineering, deeplearning, and much, much more, you’ll have the opportunity to craft a conference experience that matches your particular needs and interests.
Confirmed sessions include: Self-Supervised and Unsupervised Learning for Conversational AI and NLPNLP Fundamentals Applying Responsible AI with Open-Source Tools And more to come soon!
Voice-based queries use Natural Language Processing (NLP) and sentiment analysis for speech recognition. This communication can involve speech recognition, speech-to-text conversion, NLP, or text-to-speech. Reinforcement learning uses ML to train models to identify and respond to cyberattacks and detect intrusions.
Generative NLP Models in Customer Service: Evaluating Them, Challenges, and Lessons Learned in Banking Editor’s note: The authors are speakers for ODSC Europe this June. Be sure to check out their talk, “ Generative NLP models in customer service. Challenges and lessons learned in a real use case in banking ,” there!
A full one-third of consumers found their early customer support and chatbot experiences that use natural language processing (NLP) so disappointing that they didn’t want to engage with the technology again. And And the centrality of these experiences isn’t limited to B2C vendors.
Introduction In natural language processing, text categorization tasks are common (NLP). Deeplearning models with multilayer processing architecture are now outperforming shallow or standard classification models in terms of performance [5]. Ensemble deeplearning: A review. Uysal and Gunal, 2014).
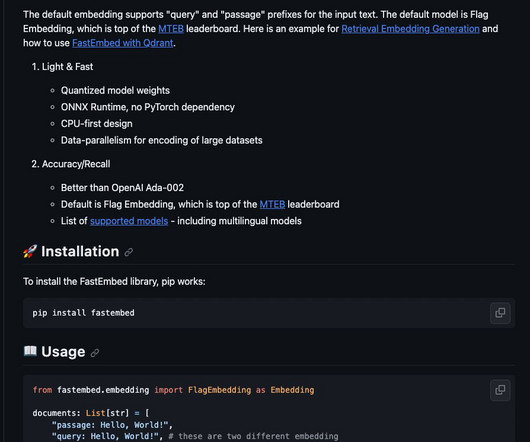
Words and phrases can be effectively represented as vectors in a high-dimensional space using embeddings, making them a crucial tool in the field of natural language processing (NLP). FastEmbed is a compact yet powerful library for generating embeddings in large databases. FastEmbed is as accurate as other embedding methods, if not more so.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content