This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
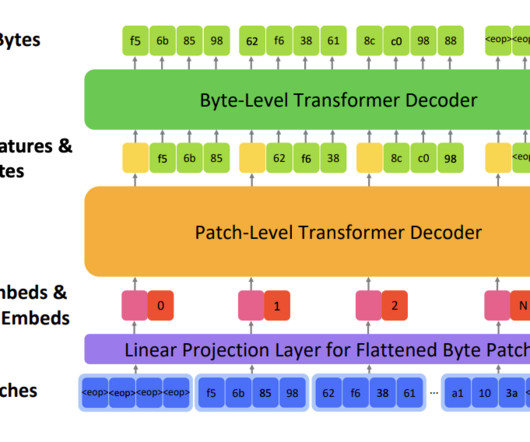
DeepLearning models have revolutionized our ability to process and understand vast amounts of data. However, a vast portion of the digital world comprises binary data, the fundamental building block of all digital information, which still needs to be explored by current deep-learning models.
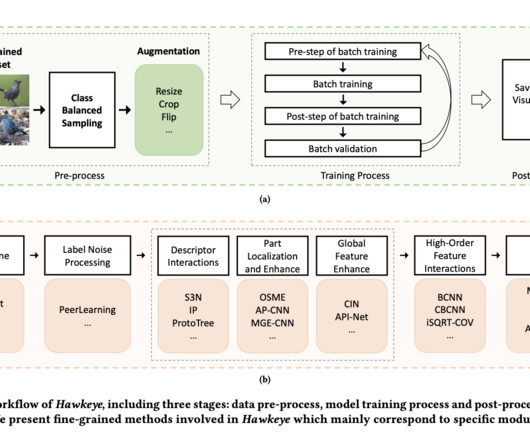
In recent years, notable advancements in the design and training of deeplearning models have led to significant improvements in image recognition performance, particularly on large-scale datasets. With its deeplearning capabilities, Hawkeye offers a comprehensive solution tailored specifically for FGIR tasks.
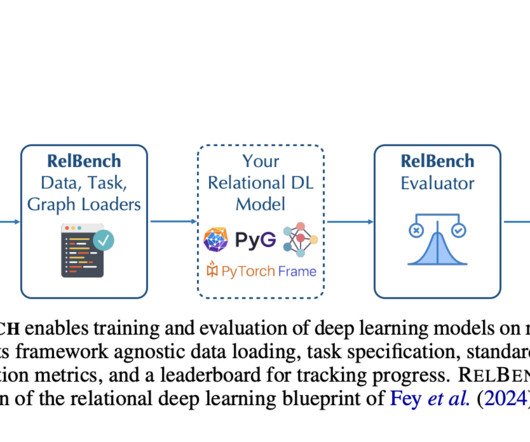
However, the richness of relational information in these databases is often underutilized due to the complexity of handling multiple interconnected tables. While simplifying data structure, this process leads to a substantial loss of predictive information and necessitates the creation of complex data extraction pipelines.
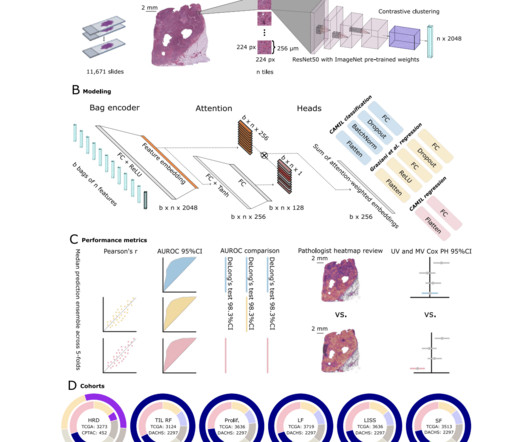
Deeplearning models process WSI by breaking them into smaller regions or tiles and aggregating features to predict biomarkers. However, current methods primarily focus on categorical classification despite many continuous biomarkers. Regression analysis offers a more suitable approach, yet it must be explored.
Blockchain technology can be categorized primarily on the basis of the level of accessibility and control they offer, with Public, Private, and Federated being the three main types of blockchain technologies. Ethereum is a decentralized blockchain platform that upholds a shared ledger of information collaboratively using multiple nodes.
In the age of information overload, managing emails can be a daunting task. Here's a deep dive into the top 10 AI email inbox management tools: 1. Based on this, it makes an educated guess about the importance of incoming emails, and categorizes them into specific folders.
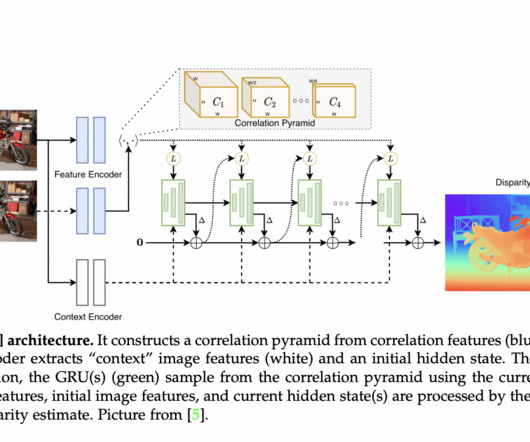
According to their cost-volume computation and optimization methodologies, existing surveys categorize end-to-end architectures into 2D and 3D classes. New approaches and paradigms have emerged in the field since then, spurred by innovations in other branches of deeplearning, and the domain has seen tremendous growth since then.
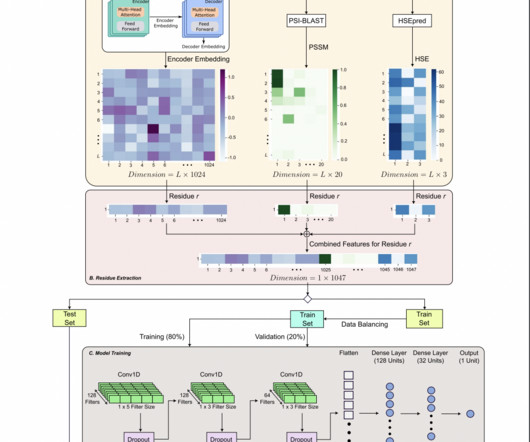
PepCNN, a deeplearning model developed by researchers from Griffith University, RIKEN Center for Integrative Medical Sciences, Rutgers University, and The University of Tokyo, addresses the problem of predicting protein-peptide binding residues. These advancements highlight the effectiveness of the proposed method.
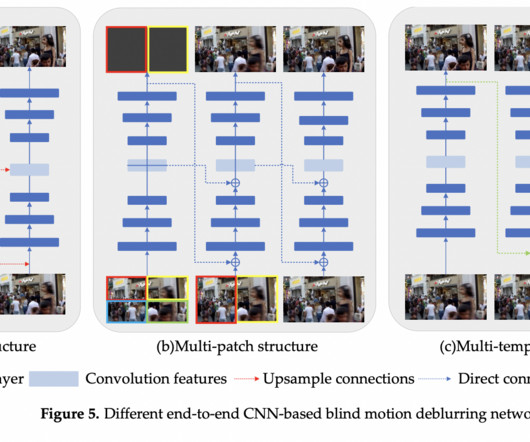
There has been a meteoric rise in the use of deeplearning in image processing in the past several years. The robust feature learning and mapping capabilities of deeplearning-based approaches enable them to acquire intricate blur removal patterns from large datasets.
Although recent deeplearning methods have improved forecasting precision, they require task-specific training and do not generalize across seen distributions. Current forecasting models can be roughly divided into two categories: statistical models and deeplearning-based models.
This article explores an innovative way to streamline the estimation of Scope 3 GHG emissions leveraging AI and Large Language Models (LLMs) to help categorize financial transaction data to align with spend-based emissions factors. Why are Scope 3 emissions difficult to calculate?
Each has a single representation for the word “well”, which combines the information for “doing well” with “wishing well”. In this post, I’ll be demonstrating two deeplearning approaches to sentiment analysis. Deeplearning refers to the use of neural network architectures, characterized by their multi-layer design (i.e.
It moves away from strict binary classifications, allowing models to learn in a way that reflects natural perception, recognizing subtle connections, adapting to new information, and doing so with improved efficiency. This allows AI models to process visual information with greater accuracy, adaptability, and efficiency.
With nine times the speed of the Nvidia A100, these GPUs excel in handling deeplearning workloads. This method involves hand-keying information directly into the target system. Named Entity Recognition ( NER) Named entity recognition (NER), an NLP technique, identifies and categorizes key information in text.
This tagging structure categorizes costs and allows assessment of usage against budgets. ListTagsForResource : Fetches the tags associated with a specific Bedrock resource, helping users understand how their resources are categorized. He focuses on Deeplearning including NLP and Computer Vision domains.
Why Gradient Boosting Continues to Dominate Tabular DataProblems Machine learning has seen the rise of deeplearning models, particularly for unstructured data such as images and text. Lucena attributes its dominance to the way gradient boosted decision trees (GBDTs) handle structured information. seasons, time ofday).
This interdisciplinary field incorporates linguistics, computer science, and mathematics, facilitating automatic translation, text categorization, and sentiment analysis. Sparse retrieval employs simpler techniques like TF-IDF and BM25, while dense retrieval leverages deeplearning to improve accuracy.
Sentiment analysis, also known as opinion mining, is the process of computationally identifying and categorizing the subjective information contained in natural language text. Deeplearning models can automatically learn features and representations from raw text data, making them well-suited for sentiment analysis tasks.
Dynamic content, including user-specific information, should be placed at the end of the prompt. Few-shot learning Including numerous high-quality examples and complex instructions, such as for customer service or technical troubleshooting, can benefit from prompt caching. The following diagram illustrates how cache hits work.
Text mining —also called text data mining—is an advanced discipline within data science that uses natural language processing (NLP) , artificial intelligence (AI) and machine learning models, and data mining techniques to derive pertinent qualitative information from unstructured text data. positive, negative or neutral).
Identifying & Flagging Hate Speech Using AI In the battle against hate speech, AI emerges as a formidable ally, with machine learning (ML) algorithms to identify and flag harmful content swiftly and accurately. To train AI models for accurate hate speech detection, supervised and unsupervised learning techniques are used.
With advancements in deeplearning, natural language processing (NLP), and AI, we are in a time period where AI agents could form a significant portion of the global workforce. Neural Networks & DeepLearning : Neural networks marked a turning point, mimicking human brain functions and evolving through experience.
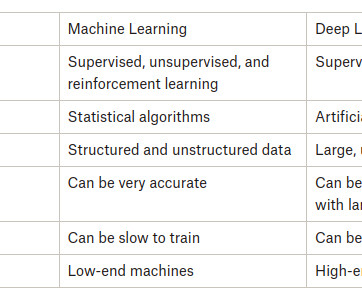
This process is known as machine learning or deeplearning. Two of the most well-known subfields of AI are machine learning and deeplearning. Supervised, unsupervised, and reinforcement learning : Machine learning can be categorized into different types based on the learning approach.
Machine learning (ML) and deeplearning (DL) form the foundation of conversational AI development. Well-known examples of virtual assistants include Apple’s Siri, Amazon Alexa and Google Assistant, primarily used for personal assistance, home automation, and delivering user-specific information or services.
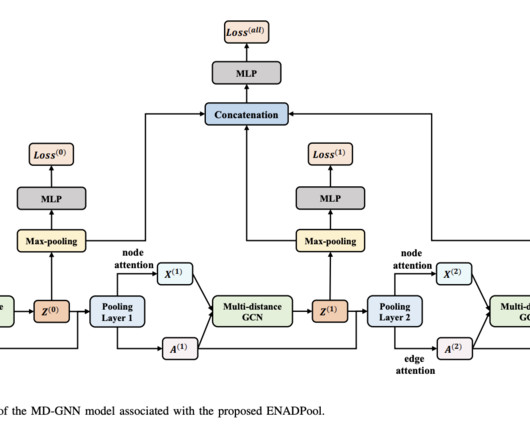
Effective graph pooling is essential for downsizing and learning representations, categorized into global and hierarchical pooling. Hierarchical methods, such as TopK-based and cluster-based strategies, aim to retain structural features but face challenges like potential information loss and over-smoothing. Check out the Paper.
For many years, gradient-boosting models and deep-learning solutions have won the lion's share of Kaggle competitions. XGBoost is not limited to machine learning tasks, as its incredible power can be harnessed when harmonized with deeplearning algorithms. " Nuclear Engineering and Technology 53, no.
Deeplearning is a branch of machine learning that makes use of neural networks with numerous layers to discover intricate data patterns. Deeplearning models use artificial neural networks to learn from data. It is a tremendous tool with the ability to completely alter numerous sectors.
To address this, AI technologies, especially machine learning and deeplearning, are being increasingly employed to streamline the process. AI in Medicine: Concepts and Applications: AI in medicine can be categorized into rule-based and machine-learning approaches.
TL;DR Deeplearning models exhibit excellent performance but require high computational resources. Deeplearning models continue to dominate the machine-learning landscape. Training and operating the deeplearning models is expensive and time-consuming and has a significant impact on the environment.
And sometimes that data includes sensitive information about people and organizations. This sparks public concerns about privacy, transparency, and control over personal information on the internet. As the demand for AI tools increases exponentially, tech giants are increasingly collecting vast amounts of data to train their models.
Beyond architecture, engineers are finding value in other methods, such as quantization , chips designed specifically for inference, and fine-tuning , a deeplearning technique that involves adapting a pretrained model for specific use cases. Hybrid architectures that use multiple types of models are also gaining traction.
They can provide valuable insights and forecasts to inform organizational decision-making in omnichannel commerce, enabling businesses to make more informed and data-driven decisions. Meanwhile, 43% are using the technology to inform strategic decisions. AI models analyze vast amounts of data quickly and accurately.
You’ll explore statistical and machine learning approaches to anomaly detection, as well as supervised and unsupervised approaches to fraud modeling. Intro to DeepLearning with PyTorch and TensorFlow Dr. Jon Krohn | Chief Data Scientist | Nebula.io
The identification of regularities in data can then be used to make predictions, categorizeinformation, and improve decision-making processes. While explorative pattern recognition aims to identify data patterns in general, descriptive pattern recognition starts by categorizing the detected patterns.
Currently chat bots are relying on rule-based systems or traditional machine learning algorithms (or models) to automate tasks and provide predefined responses to customer inquiries. Enterprise organizations (many of whom have already embarked on their AI journeys) are eager to harness the power of generative AI for customer service.
Photo by Almos Bechtold on Unsplash Deeplearning is a machine learning sub-branch that can automatically learn and understand complex tasks using artificial neural networks. Deeplearning uses deep (multilayer) neural networks to process large amounts of data and learn highly abstract patterns.
AGI, sometimes referred to as strong AI , is the science-fiction version of artificial intelligence (AI), where artificial machine intelligence achieves human-level learning, perception and cognitive flexibility. Most experts categorize it as a powerful, but narrow AI model.
Deeplearning for feature extraction, ensemble models, and more Photo by DeepMind on Unsplash The advent of deeplearning has been a game-changer in machine learning, paving the way for the creation of complex models capable of feats previously thought impossible.
Large Language Models, or LLMs , are Machine Learning models that understand, generate, and interact with human language. Its AI Conversational Intelligence feature also helps its customers more efficiently process call data at scale by auto-scoring and categorizing key sections of customer calls.
Though once the industry standard, accuracy of these classical models had plateaued in recent years, opening the door for new approaches powered by advanced DeepLearning technology that’s also been behind the progress in other fields such as self-driving cars. The data does not need to be force-aligned.
They categorized these experiments as Bag of Freebies (BoF) and Bag of Specials (BoS). This bottom-up path aggregates and passes features from lower levels back up through the network, which reinforces lower-level features with contextual information and enriches high-level features with spatial details.
It’s the underlying engine that gives generative models the enhanced reasoning and deeplearning capabilities that traditional machine learning models lack. A foundation model is built on a neural network model architecture to process information much like the human brain does.
LogAI provides a unified model interface for popular statistical, time-series, and deep-learning models, making it easy to benchmark deep-learning algorithms for log anomaly detection. Logs generated by computer systems contain essential information that helps developers understand system behavior and identify issues.
It’s built on top of popular deeplearning frameworks like PyTorch and TensorFlow, making it accessible to a broad audience of developers and researchers. It offers a variety of features, including tokenization, part-of-speech tagging, named entity recognition, dependency parsing, and text categorization.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content