This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideo Book This article was published as a part of the DataScience Blogathon. The post How to Perform One-Hot Encoding For Multi Categorical Variables appeared first on Analytics Vidhya. In this article, we will learn about how can we.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction: Clustering is an unsupervised learning method whose task is to. The post KModes Clustering Algorithm for Categoricaldata appeared first on Analytics Vidhya.
Introduction The world of auditing data can be complex, with many challenges to overcome. One of the biggest challenges is handling categorical attributes while dealing with datasets. In this article, we will delve into the world of auditing data, anomaly detection, and the impact of encoding categorical attributes on models.
ArticleVideo Book This article was published as a part of the DataScience Blogathon. Introduction “Data is the fuel for Machine Learning algorithms” Real-world. The post How to Handle Missing Values of Categorical Variables? appeared first on Analytics Vidhya.
Overview Presenting 11 datascience videos that will enhance and expand your current skillset We have categorized these videos into three fields – Natural. The post 11 Superb DataScience Videos Every Data Scientist Must Watch appeared first on Analytics Vidhya.
Introduction In the bustling world of machine learning, categoricaldata is like the DNA of our datasets – essential yet complex. But how do we make this data comprehensible to our algorithms? Enter One Hot Encoding, the transformative process that turns categorical variables into a language that machines understand.
Introduction If enthusiastic learners want to learn datascience and machine learning, they should learn the boosted family. CatBoost is a machine […] The post CatBoost: A Solution for Building Model with CategoricalData appeared first on Analytics Vidhya.
We have all been seeing the transformation of datascience from being used extensively in technical domains for analysis to being used as an excellent tool for solving social and global issues. This advanced application of datascience for humanitarian aid would bring us closer to society and change the world.
This article was published as a part of the DataScience Blogathon. The heart and soul of this algorithm is the concept of Hyperplanes where these planes help to categorize the high dimensional data which are either […].
This article was published as a part of the DataScience Blogathon. Introduction AWS Glue helps Data Engineers to prepare data for other data consumers through the Extract, Transform & Load (ETL) Process. It provides organizations with […].
ArticleVideo Book This article was published as a part of the DataScience Blogathon. Overview introduction reduce execution time dataset reading dataset handling categorical. The post Train Machine Learning Models Using CPU Multi Cores appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Naive Bayes Classifier Overview Assume you wish to categorize user reviews. The post Performing Sentiment Analysis With Naive Bayes Classifier! appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Two popular types of categorization techniques are […]. Introduction Image classification is the process of classifying and recognizing groups of pixels inside an image in line with pre-established principles.
This article was published as a part of the DataScience Blogathon. Introduction Data Visualization is used to present the insights in a given dataset. With meaningful and eye-catching charts, it becomes easier to communicate data analysis findings.
This article was published as a part of the DataScience Blogathon Object detection is one of the popular applications of deep learning. Most of you would have used Google Photos in your phone, which automatically categorizes your photos into groups based on the objects present in them under […].
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction Classification algorithms are used to categorizedata into a class. The post 5 Classification Algorithms you should know – introductory guide! appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Introduction Consider the following scenario: you are a product manager who wants to categorize customer feedback into two categories: favorable and unfavorable.
This article was published as a part of the DataScience Blogathon Overview CATBOOST is an open-source machine learning library developed by a Russian search engine giant Yandex. One of the prominent aspects of catboost is its ability to handle missing data and categoricaldata without encoding but will get to that later.
This panel has designed the guidelines for annotating the wellness dimensions and categorized the posts into the six wellness dimensions based on the sensitive content of each post. What are wellness dimensions? Considering its structure, we have taken Halbert L. Dunns wellness model as a base for our MULTIWD dataset.
This article was published as a part of the DataScience Blogathon. Introduction A ledger is an accounting record that lists debits and credits for the categorized and condensed data from the journals. Another name for it is the second book of entries.
This article was published as a part of the DataScience Blogathon Introduction Quite often we have a requirement to visualize categoricaldata in a dataset.
ArticleVideo Book This article was published as a part of the DataScience Blogathon. Introduction The data consists of a two-dimensional array of categorical. The post Discovering the shades of Feature Selection Methods appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Audio classification is an Application of machine learning where different sound is categorized in certain categories. Hello, and welcome to a wonderful article on audio classification.
Introduction Logistic regression is a statistical technique used to model the probability of a binary (categorical variable that can take on two distinct values) outcome based on one or more predictor variables.
This is exactly what happens when you try to feed categoricaldata into a machine-learning model. Image generated by Dall-E In this hands-on tutorial, we’ll unravel the mystery of encoding categoricaldata so your models can process it with ease. Before we start transforming data, let’s get our definitions straight.
These are typical datascience interview questions every aspiring data scientist. What is One-Hot Encoding? When should you use One-Hot Encoding over Label Encoding? The post One-Hot Encoding vs. Label Encoding using Scikit-Learn appeared first on Analytics Vidhya.
Source: Image by the Author That’s exactly what converting numerical data into categoricaldata can do for you! By the end, you’ll know how to wrangle numerical data into meaningful categories with easy-to-follow code examples. Join thousands of data leaders on the AI newsletter. Sounds better, right?
Datascience has changed and shaped how organizations think about issues across various businesses as information has become more widely available thanks to technology. Whatever stage a company is at, data for good may assist it in establishing a data strategy for nonprofits.
Customer Service and Support Speech AI technology provides more accurate, insightful call analysis by automatically categorizing, summarizing, and extracting actionable insights from customer calls—such as flagging questions and complaints.
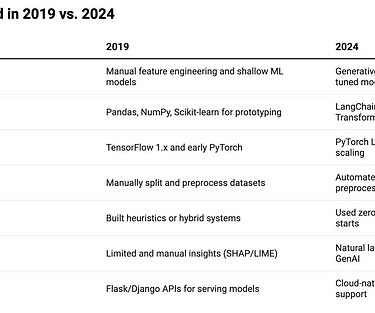
Let me walk you through a typical workflow I followed back then: Data Collection & Cleaning: I relied heavily on Pandas and SQL for data cleaning, merging, and feature extraction. Training involved long cycles of feature engineering everything from creating TF-IDF vectors for text features to manually generating embeddings.
Once AI integrates with a data ecosystem, it can help automate the processing of complex assets, such as legal documents, contracts, call center interactions, etc. AI can also help build knowledge graphs to organize unstructured data, making Gen AI capabilities more effective. AI enablement is an organization-wide endeavor.
DataScience is a popular as well as vast field; till date, there are a lot of opportunities in this field, and most people, whether they are working professionals or students, everyone want a transition in datascience because of its scope. How much to learn? What to do next?
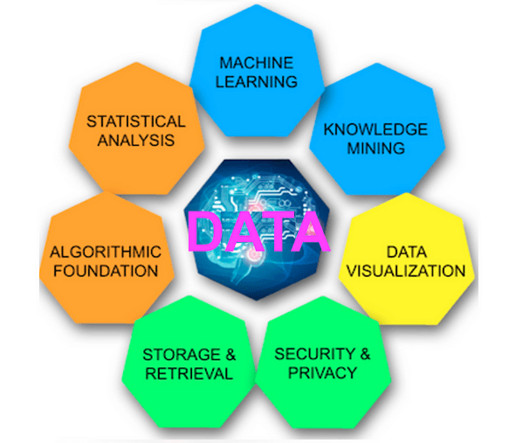
ML is a computer science, datascience and artificial intelligence (AI) subset that enables systems to learn and improve from data without additional programming interventions. Each type and sub-type of ML algorithm has unique benefits and capabilities that teams can leverage for different tasks. What is machine learning?
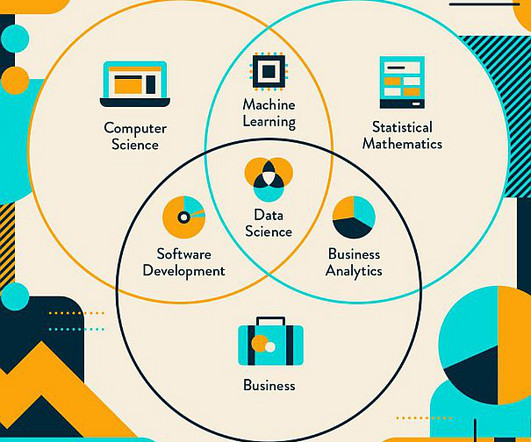
Datascience is a multidisciplinary field that relies on scientific methods, statistics, and Artificial Intelligence (AI) algorithms to extract knowledgable and meaningful insights from data. At its core, datascience is all about discovering useful patterns in data and presenting them to tell a story or make informed decisions.
A Comprehensive DataScience Guide to Preprocessing for Success: From Missing Data to Imbalanced Datasets This member-only story is on us. In just about any organization, the state of information quality is at the same low level – Olson, Data Quality Data is everywhere! Originally published on Towards AI.
Advanced Fraud Modeling & Anomaly Detection with Python & R Aric LaBarr, PhD | Associate Professor of Analytics, Institute for Advanced Analytics | NC State University During this course, you’ll examine the standard fraud framework at a company, where datascience can have an impact, and how to build an analytically advanced fraud system.
AI and datascience are advancing at a lightning-fast pace with new skills and applications popping up left and right. In this hands-on session, youll start with logistic regression and build up to categorical and ordered logistic models, applying them to real-world survey data.
Colner received his PhD in Political Science from the University of California, Davis in 2024, and has a keen interest in leveraging datascience to understand local political institutions. I’m excited to join NYU CDS and work at the intersection of datascience and local politics,” said Colner. “I
Summary: The DataScience and Data Analysis life cycles are systematic processes crucial for uncovering insights from raw data. Quality data is foundational for accurate analysis, ensuring businesses stay competitive in the digital landscape. Understanding their life cycles is critical to unlocking their potential.
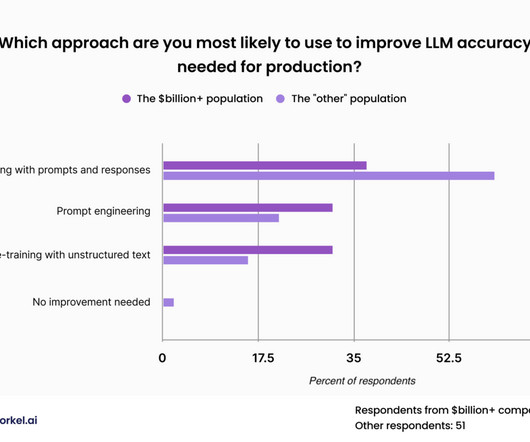
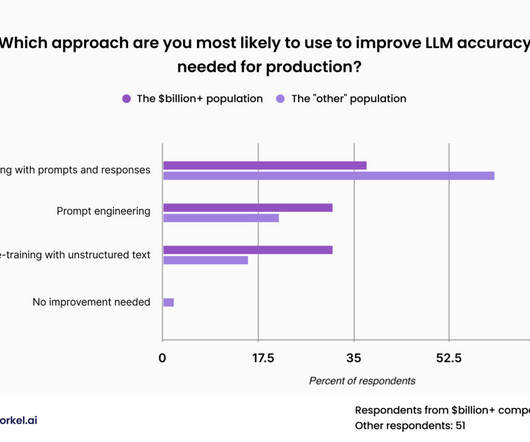
Labeled data remains biggest blocker More than a quarter of respondents said that the lack of high-quality labeled data presented the biggest blocker for enterprise AI projects. Labeling data” is when data scientists use an LLM to apply a categorical label to a document, such as categorizing an article as business or sports.
Labeled data remains biggest blocker More than a quarter of respondents said that the lack of high-quality labeled data presented the biggest blocker for enterprise AI projects. Labeling data” is when data scientists use an LLM to apply a categorical label to a document, such as categorizing an article as business or sports.
Summary : This article equips Data Analysts with a solid foundation of key DataScience terms, from A to Z. Introduction In the rapidly evolving field of DataScience, understanding key terminology is crucial for Data Analysts to communicate effectively, collaborate effectively, and drive data-driven projects.
Mathematics and DataScience: its role and relevance Mathematics and DataScience are discussed in the same breath. The reason behind this unbreakable bond is the role of mathematical equations in DataScience. Why DataScience? 650% growth in the data domain since 2012.
In a series of articles, we’d like to share the results so you too can learn more about what the datascience community is doing in machine learning. You can also get datascience training on-demand wherever you are with our Ai+ Training platform.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































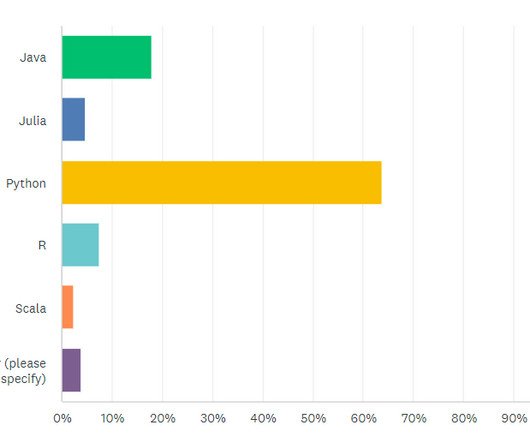






Let's personalize your content