This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
One of the best ways to take advantage of social media data is to implement text-mining programs that streamline the process. What is text mining? Data extraction Once you’ve assigned numerical values, you will apply one or more text-mining techniques to the structured data to extract insights from social media data.
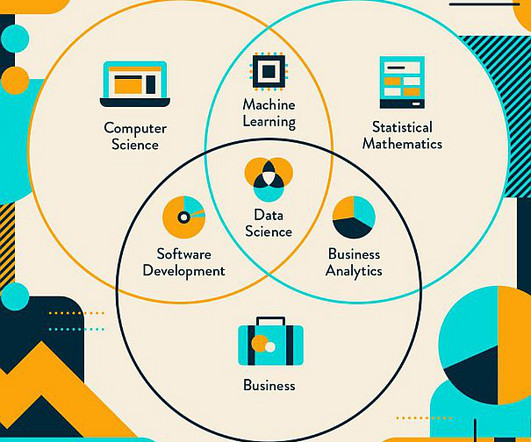
Datascience is a multidisciplinary field that relies on scientific methods, statistics, and Artificial Intelligence (AI) algorithms to extract knowledgable and meaningful insights from data. At its core, datascience is all about discovering useful patterns in data and presenting them to tell a story or make informed decisions.
MonkeyLearn’s use of machine learning to streamline business processes and analyze text eliminates the need for countless man-hours of data entry. The ability to automatically pull data from incoming requests is a popular feature in MonkeyLearn. The users can construct data analysis and transformation procedures.
Summary : This article equips Data Analysts with a solid foundation of key DataScience terms, from A to Z. Introduction In the rapidly evolving field of DataScience, understanding key terminology is crucial for Data Analysts to communicate effectively, collaborate effectively, and drive data-driven projects.
DataScience is a growing field and more and more people are emerging to take up DataScience as their career choice. While DataScience courses can be considered beneficial for development of conceptual knowledge, DataScience competitions help in skill development.
Hey guys, in this blog we will see some of the most asked DataScience Interview Questions by interviewers in [year]. Datascience has become an integral part of many industries, and as a result, the demand for skilled data scientists is soaring. What is DataScience?
Predictive analytics uses methods from datamining, statistics, machine learning, mathematical modeling, and artificial intelligence to make future predictions about unknowable events. It creates forecasts using historical data. Predictive analytics is a standard tool that we utilize without much thought.
Turi Create To add suggestions, object identification, picture classification, image similarity, or activity categorization to your app, you can be an expert in machine learning. It includes built-in streaming graphics to analyze your data and focuses on tasks rather than algorithms.
The surge of digitization and its growing penetration across the industry spectrum has increased the relevance of text mining in DataScience. Text mining is primarily a technique in the field of DataScience that encompasses the extraction of meaningful insights and information from unstructured textual data.
Source: Author Introduction Text classification, which involves categorizing text into specified groups based on its content, is an important natural language processing (NLP) task. This article will look at how R can be used to execute text categorization tasks efficiently. You can read more about the R language here.
Predictive analytics is a method of using past data to predict future outcomes. It relies on tools like datamining , machine learning , and statistics to help businesses make decisions. Classification Models : These models help businesses categorizedata, like whether a customer will stay or leave.
The goal of NER is to automatically identify and categorize specific information from vast amounts of text. In AI, entities refer to tangible and intangible elements like people, organizations, locations, and dates embedded in text data. DataMining : NER is used to identify key entities in large datasets, extracting valuable insights.
The advent of relational databases and data warehouses in the 1970s and 1980s set the stage for the next wave of advancements in data engineering, including the development of datamining techniques, the rise of big data, and the evolution of data storage and processing technologies.
The consortium trained models on billions of data points, consisting of over 20 million small molecules in over 40,000 biological assays. Based on experimental results, the collaborative models demonstrated a 4% improvement in categorizing molecules as either pharmacologically or toxicologically active or inactive.
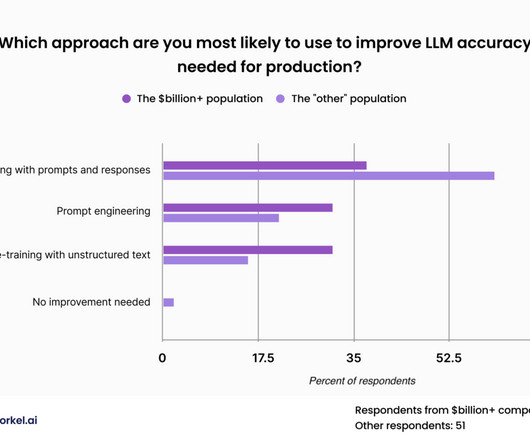
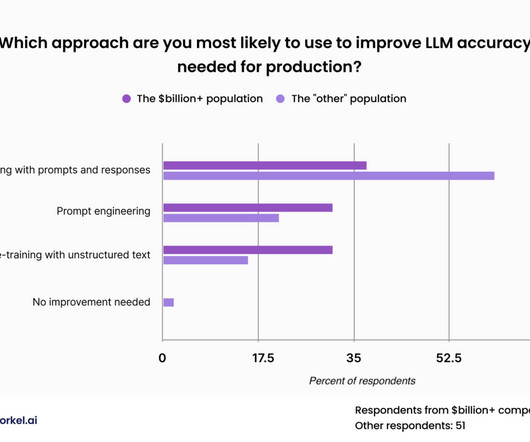
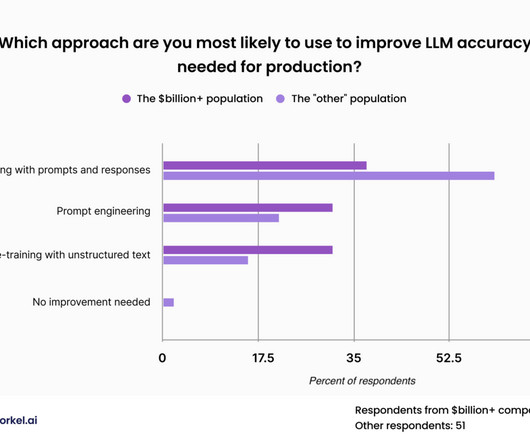
Most datascience leaders expect their companies to customize large language models for their enterprise applications, according to a recent survey , but the process of making LLMs work for your business and your use cases is still a fresh challenge. For a proprietary general-purpose model, such public data sets may be sufficient.
Role in Extracting Insights from Raw Data Raw data is often complex and unorganised, making it difficult to derive useful information. Data Analysis plays a crucial role in filtering and structuring this data. Median: The middle value in a dataset, helping to understand the data’s distribution.
Most datascience leaders expect their companies to customize large language models for their enterprise applications, according to a recent survey , but the process of making LLMs work for your business and your use cases is still a fresh challenge. For a proprietary general-purpose model, such public data sets may be sufficient.
Recommendation Techniques Datamining techniques are incredibly valuable for uncovering patterns and correlations within data. Figure 5 provides an overview of the various datamining techniques commonly used in recommendation engines today, and we’ll delve into each of these techniques in more detail.
Most datascience leaders expect their companies to customize large language models for their enterprise applications, according to a recent survey , but the process of making LLMs work for your business and your use cases is still a fresh challenge. For a proprietary general-purpose model, such public data sets may be sufficient.
Machine Learning is a subset of Artificial Intelligence and Computer Science that makes use of data and algorithms to imitate human learning and improving accuracy. Being an important component of DataScience, the use of statistical methods are crucial in training algorithms in order to make classification.
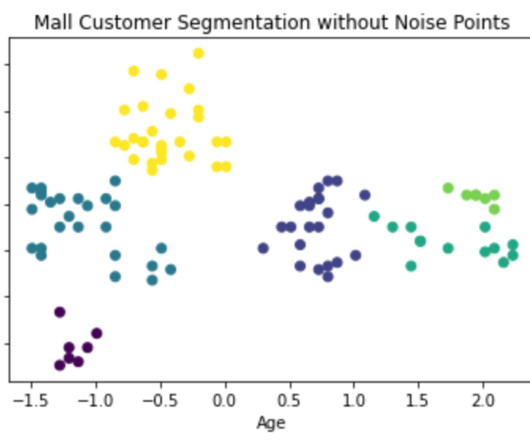
Core Points, Border Points & Noise Points:- So, in a given dataset, D = {Xi} with Min pts, eps as hyper-parameters we can categorize each and every point in the dataset as a “Core Point” , “Border Point” (or) a “Noise Point”. Basically, DBSCAN was created by the researchers in DataMining & Data Base community.
They’re the perfect fit for: Image, video, text, data & lidar annotation Audio transcription Sentiment analysis Content moderation Product categorization Image segmentation iMerit also specializes in extraction and enrichment for Computer Vision , NLP , data labeling, and other technologies. Digica Clutch rating: 4.7/5
Summary: Python for DataScience is crucial for efficiently analysing large datasets. Introduction Python for DataScience has emerged as a pivotal tool in the data-driven world. Key Takeaways Python’s simplicity makes it ideal for Data Analysis. in 2022, according to the PYPL Index.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content