This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This advancement has spurred the commercial use of generative AI in natural language processing (NLP) and computer vision, enabling automated and intelligent dataextraction. Businesses can now easily convert unstructured data into valuable insights, marking a significant leap forward in technology integration.
Content creators like bloggers and social media managers can use HARPA AI to generate content ideas, optimize posts for SEO, and summarize information from various sources. Researchers can use HARPA AI for dataextraction and analysis for market research or competitive analysis to gather insights.
In a world whereaccording to Gartner over 80% of enterprise data is unstructured, enterprises need a better way to extract meaningful information to fuel innovation. With Amazon Bedrock Data Automation, enterprises can accelerate AI adoption and develop solutions that are secure, scalable, and responsible.
Akeneo is the product experience (PX) company and global leader in Product Information Management (PIM). How is AI transforming product information management (PIM) beyond just centralizing data? Akeneo is described as the “worlds first intelligent product cloud”what sets it apart from traditional PIM solutions?
Large language models (LLMs) have unlocked new possibilities for extractinginformation from unstructured text data. This post walks through examples of building informationextraction use cases by combining LLMs with prompt engineering and frameworks such as LangChain.
Researchers can use simple search queries to find what they're looking for and compare responses across different sessions to identify patterns or outliers in the data. Beyond basic tagging and categorization, Speech AI can also help with more nuanced parameters, such as speaker identification, sentiment, and thematic content.
The explosion of content in text, voice, images, and videos necessitates advanced methods to parse and utilize this information effectively. Enter generative AI, a groundbreaking technology that transforms how we approach dataextraction. Generative AI models excel at extracting relevant features from vast amounts of text data.
Through a practical use case of processing a patient health package at a doctors office, you will see how this technology can extract and synthesize information from all three document types, potentially improving data accuracy and operational efficiency. For more information, see Create a guardrail.
Text mining —also called text data mining—is an advanced discipline within data science that uses natural language processing (NLP) , artificial intelligence (AI) and machine learning models, and data mining techniques to derive pertinent qualitative information from unstructured text data.
Moreover, we will utilise the information from our time-series model as regression features to strengthen our regression’s predictive power. Consequently, in our case, the initial step in performing feature engineering is to group our features into three groups: categorical features, temporal features, and numerical features.
To extract key information from high volumes of documents from emails and various sources, companies need comprehensive automation capable of ingesting emails, file uploads, and system integrations for seamless processing and analysis. Finding relevant information that is necessary for business decisions is difficult.
Compiling data from these disparate systems into one unified location. This is where data integration comes in! Data integration is the process of combining information from multiple sources to create a consolidated dataset. Data integration tools consolidate this data, breaking down silos. The challenge?
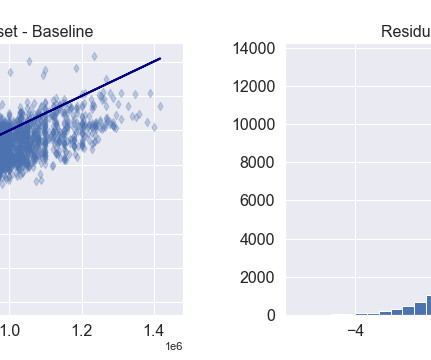
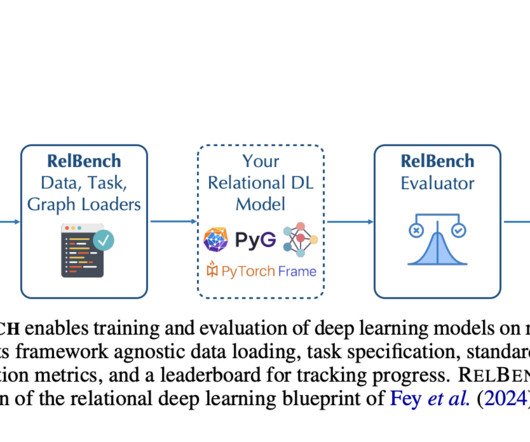
These databases underpin significant portions of the digital economy, efficiently organizing and retrieving data necessary for operations in diverse fields. However, the richness of relational information in these databases is often underutilized due to the complexity of handling multiple interconnected tables.
Compiling data from these disparate systems into one unified location. This is where data integration comes in! Data integration is the process of combining information from multiple sources to create a consolidated dataset. Data integration tools consolidate this data, breaking down silos. The challenge?
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according to a preset data model. Unstructured information may have a little or a lot of structure but in ways that are unexpected or inconsistent. Text, images, audio, and videos are common examples of unstructured data.
This blog post explores how John Snow Labs Healthcare NLP & LLM library revolutionizes oncology case analysis by extracting actionable insights from clinical text. Relation extraction is used to connect biomarkers to their respective results, enabling a detailed understanding of the role biomarkers play in cancer diagnosis.
The important information from an invoice may be extracted without resorting to templates or memorization, thanks to the hundreds of millions of invoices used to train the algorithms. Bookkeeping and other administrative costs can be reduced by digitizing financial data and automating procedures.
In the accounts payable department, AI can benefit payment processing, invoice capture, dataextraction, invoice workflow automation , and even fraud detection. Data literacy: Data has always been essential in finance, but especially so now that many financial processes have gone fully digital.
Underwriters must review and analyze a wide range of documents submitted by applicants, and the manual extraction of relevant information is a time-consuming and error-prone task. This is a complex task when faced with unstructured data, varying document formats, and erroneous data.
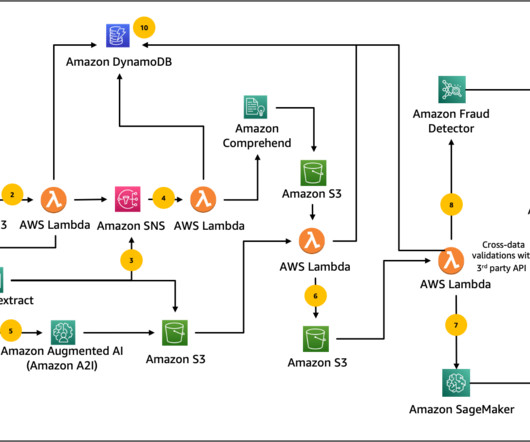
We provide concrete guidance on addressing this issue with AWS AI and ML services to detect document tampering, identify and categorize patterns for fraudulent scenarios, and integrate with business-defined rules while minimizing human expertise for fraud detection. These fraud attempts can be challenging for mortgage lenders to capture.
What is Clinical Data Abstraction Creating large-scale structured datasets containing precise clinical information on patient itineraries is a vital tool for medical care providers, healthcare insurance companies, hospitals, medical research, clinical guideline creation, and real-world evidence.
This is what data processing pipelines do for you. Automating myriad steps associated with pipeline data processing, helps you convert the data from its raw shape and format to a meaningful set of information that is used to drive business decisions. Provides data security using AI & blockchain technologies.
For instance, tasks involving dataextraction, transfer, or essential decision-making based on predefined rules might not require complex algorithms and custom AI software. It’s about ensuring that this data is handled ethically and legally. Before diving into the world of AI, first question if your business even needs it.
For instance, tasks involving dataextraction, transfer, or essential decision-making based on predefined rules might not require complex algorithms and custom AI software. It’s about ensuring that this data is handled ethically and legally. Before diving into the world of AI, first question if your business even needs it.
The key is to identify problem types that most closely match the task at hand when communicating with your AI and data science experts. InformationExtraction (IE) 6. Keyword Extraction 14. One of the goals of informationextraction is to fill templates using dataextracted from raw text.
These documents often contain vital information that drives timely decision-making, essential for ensuring top-tier customer satisfaction, and reduced customer churn. Traditionally, the extraction of data from documents is manual, making it slow, prone to errors, costly, and challenging to scale.
In this article, we will cover the third & fourth sections i.e. DataExtraction, Preprocessing & EDA & Machine Learning Model development Data collection : Automatically download the stock historical prices data in CSV format and save it to the AWS S3 bucket. And Deploy the final app on Streamlit Cloud.
Web scraping is a technique used to extractdata from websites. It allows us to gather information from web pages and use it for various purposes, such as data analysis, research, or building applications. This allows us to navigate and extractinformation from the HTML structure of the web page.
Medical records, rich with sensitive information, are invaluable for research and innovation but must be carefully managed to ensure compliance with regulations like HIPAA and GDPR. De-identification, the process of removing or obscuring personally identifiable information (PII) from medical data, lies at the heart of this effort.
Medical records, rich with sensitive information, are invaluable for research and innovation but must be carefully managed to ensure compliance with regulations like HIPAA and GDPR. Deidentification, the process of removing or obscuring personally identifiable information (PII) from medical data, lies at the heart of this effort.
Packages like dplyr and tidyr offer a wide range of functions for filtering, sorting, aggregating, merging, and reshaping data. These tools enable users to clean and preprocess data, extract relevant information, and create derived variables. · Reproducible Research: R promotes reproducible research through literate programming.
Developing a machine learning model requires a big amount of training data. Therefore, the data needs to be properly labeled/categorized for a particular use case. Companies can use high-quality human-powered data annotation services to enhance ML and AI implementations.
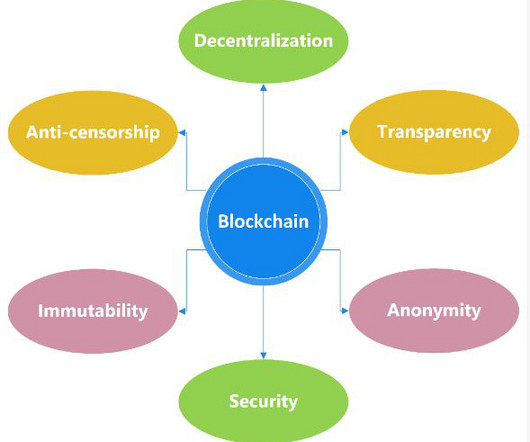
Blockchain is a distributed and immutable ledger that securely stores data and information in a decentralized and reliable manner. Therefore, the secure nature of blockchain guarantees the data to be tamper-proof. They utilized machine learning algorithms for dataextraction, pattern classification, and prescription prediction.
It employs a combination of technology, processes, and skilled personnel to maintain the confidentiality, integrity, and availability of information systems and data. This skill simplifies the dataextraction process, allowing security analysts to conduct investigations more efficiently without requiring deep technical knowledge.
A knowledge graph (semantic network) represents the information (storing not just data but also its meaning and context). This allows for deducing new, implicit knowledge from existing data, surpassing traditional databases. Knowledge Graph Fusion: Integrating information from multiple knowledge graphs.
When financial industry professionals need reliable over-the-counter (OTC) data solutions and advanced analytics, they can turn to Parameta Solutions , the data powerhouse behind TP ICAP. With a focus on data-led solutions, Parameta Solutions makes sure that these professionals have the insights they need to make informed decisions.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content