This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This advancement has spurred the commercial use of generative AI in natural language processing (NLP) and computer vision, enabling automated and intelligent dataextraction. Businesses can now easily convert unstructured data into valuable insights, marking a significant leap forward in technology integration.
In this post, we focus on one such complex workflow: document processing. This serves as an example of how generative AI can streamline operations that involve diverse data types and formats. We demonstrate how generative AI along with external tool use offers a more flexible and adaptable solution to this challenge.
Today, were excited to announce the general availability of Amazon Bedrock Data Automation , a powerful, fully managed feature within Amazon Bedrock that automate the generation of useful insights from unstructured multimodal content such as documents, images, audio, and video for your AI-powered applications.
Researchers can use HARPA AI for dataextraction and analysis for market research or competitive analysis to gather insights. The way it categorizes incoming emails automatically has also helped me maintain that elusive “inbox zero” I could only dream about. The quality of translations is surprisingly good, too.
Companies in sectors like healthcare, finance, legal, retail, and manufacturing frequently handle large numbers of documents as part of their day-to-day operations. These documents often contain vital information that drives timely decision-making, essential for ensuring top-tier customer satisfaction, and reduced customer churn.
Many companies across all industries still rely on laborious, error-prone, manual procedures to handle documents, especially those that are sent to them by email. Intelligent automation presents a chance to revolutionize document workflows across sectors through digitization and process optimization.
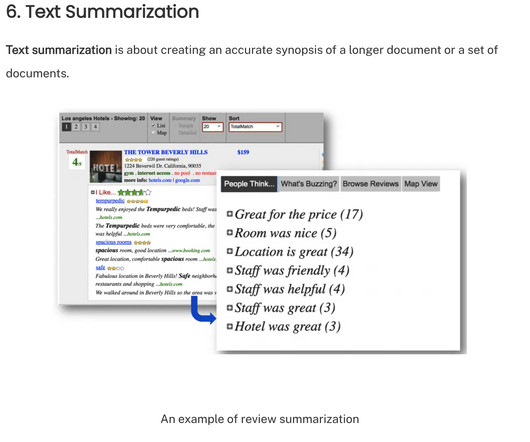
Enter generative AI, a groundbreaking technology that transforms how we approach dataextraction. Entity Recognition : Identify and categorize entities (like names, dates, or locations) within text. Summarization : Condense large documents into concise summaries, making it easier to digest extensive reports or articles quickly.
These are two common methods for text representation: Bag-of-words (BoW): BoW represents text as a collection of unique words in a text document. Term frequency-inverse document frequency (TF-IDF): TF-IDF calculates the importance of each word in a document based on its frequency or rarity across the entire dataset.
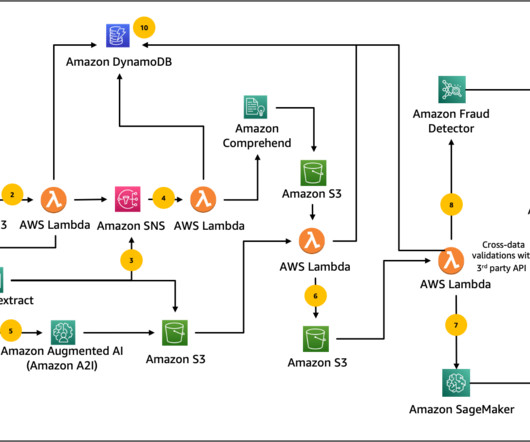
In this three-part series, we present a solution that demonstrates how you can automate detecting document tampering and fraud at scale using AWS AI and machine learning (ML) services for a mortgage underwriting use case. Fraudsters range from blundering novices to near-perfect masters when creating fraudulent loan application documents.
Key Features: Real-time data replication and integration with major data warehouses. Cons: Confusing transformations, lack of pipeline categorization, view sync issues. It also offers EDI management features alongside data governance. Key Features: Cloud-native platform with powerful data migration capabilities.
Healthcare Data Abstraction: The Three Barriers To begin with, each project has its own sets of rules for what, how, and when data should be extracted and normalized. Second, the information is frequently derived from natural language documents or a combination of structured, imaging, and document sources.
Key Features: Real-time data replication and integration with major data warehouses. Cons: Confusing transformations, lack of pipeline categorization, view sync issues. Visit Hevo Data → 7. It also offers EDI management features alongside data governance. Visit SAP Data Services → 10. Visit Boomi → 8.
Text, images, audio, and videos are common examples of unstructured data. Most companies produce and consume unstructured data such as documents, emails, web pages, engagement center phone calls, and social media. Understanding the data, categorizing it, storing it, and extracting insights from it can be challenging.
AI-powered automation systems can handle tedious tasks such as filling out forms, scheduling meetings, and managing documentation. In the accounts payable department, AI can benefit payment processing, invoice capture, dataextraction, invoice workflow automation , and even fraud detection.
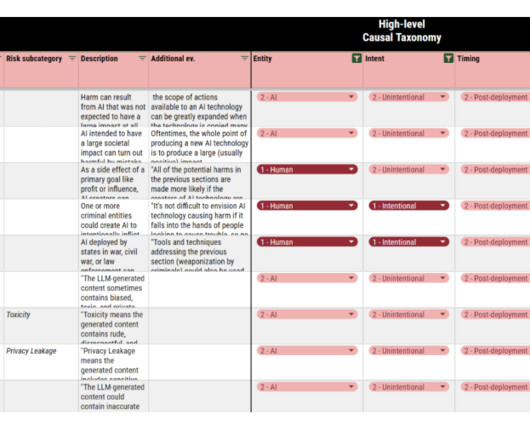
Although substantial research has identified and categorized these risks, a unified framework is needed to be consistent with terminology and clarity. Two taxonomies were developed: the Causal Taxonomy, categorizing risks by responsible entity, intent, and timing, and the Domain Taxonomy, classifying risks into specific domains.
Challenges in document understanding for underwriting Document understanding is a critical and complex aspect of the underwriting process that poses significant challenges for insurers. This is a complex task when faced with unstructured data, varying document formats, and erroneous data.
Biomarker Analysis and Relationship Extraction: Biomarkers play a pivotal role in modern oncology, serving as indicators for diagnosis, prognosis, and treatment response. Relation extraction is used to connect biomarkers to their respective results, enabling a detailed understanding of the role biomarkers play in cancer diagnosis.
Features include real-time OCR dataextraction from invoices, bills, and receipts, automatic transaction categorization, and AI-assisted reconciliation. Documents can be managed in bulk, discrepancies can be found and fixed, and dynamic reports can be generated.
Tasks such as routing support tickets, recognizing customers intents from a chatbot conversation session, extracting key entities from contracts, invoices, and other type of documents, as well as analyzing customer feedback are examples of long-standing needs. In this example, you explicitly set the instance type to ml.g5.48xlarge.
Document Segmentation Problem 13. Keyword Extraction 14. Classification A classification problem is about assigning one or more categories to a document, product, person, or image—essentially anything. One of the goals of information extraction is to fill templates using dataextracted from raw text.
In this article, we will cover the third & fourth sections i.e. DataExtraction, Preprocessing & EDA & Machine Learning Model development Data collection : Automatically download the stock historical prices data in CSV format and save it to the AWS S3 bucket. Please refer to this documentation link.
These documents, which detail a drugs indications, risks, and clinical trial results, are critical but time-consuming to curate, often exceeding 100 pages per drug. The model categorized toxicity using ternary (No, Less, Most) and binary (Yes, No) scales.
Developing a machine learning model requires a big amount of training data. Therefore, the data needs to be properly labeled/categorized for a particular use case. Companies can use high-quality human-powered data annotation services to enhance ML and AI implementations.
These packages allow for text preprocessing, sentiment analysis, topic modeling, and document classification. It allows data scientists to combine code, documentation, and visualizations in a single document, making it easier to share and reproduce analyses.
Dataset For this benchmark, we utilized 48 open-source documents annotated by domain experts from John Snow Labs. Launched in 2024, the service offers three key operations: Tag, Redact, and Surrogate, enabling healthcare organizations to process diverse types of clinical documents securely and efficiently.
Dataset For this benchmark, we utilized 48 open-source documents annotated by domain experts from John Snow Labs. Launched in 2024, the service offers three key operations: Tag, Redact, and Surrogate, enabling healthcare organizations to process diverse types of clinical documents securely and efficiently.
Sounds crazy, but Wei Shao (Data Scientist at Hortifrut) and Martin Stein (Chief Product Officer at G5) both praised the solution. launched an initiative called ‘ AI 4 Good ‘ to make the world a better place with the help of responsible AI.
Machine Learning model training over a decentralized network – Source Secure Data sharing by using Blockchain Data owners can contribute their datasets to the decentralized AI model training without actually moving the data off their premises.
Task 1: Query generation from natural language This task’s objective is to assess a model’s capacity to translate natural language questions into SQL queries, using contextual knowledge of the underlying data schema. We use real incident data from Sophos’s MDR for incident summarization.
Here are these: Data Preprocessing: The first step involves collecting the data (usually scrapped from the internet). Then pre-processing the semi-structured data to transform it into noise-free documents ready for further analysis and knowledge extraction. scientists, artists).
Machine learning (ML) classification models offer improved categorization, but introduce complexity by requiring separate, specialized models for classification, entity extraction, and response generation, each with its own training data and contextual limitations. Built-in conditional logic handles different processing paths.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content