This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This advancement has spurred the commercial use of generative AI in natural language processing (NLP) and computer vision, enabling automated and intelligent dataextraction. Businesses can now easily convert unstructured data into valuable insights, marking a significant leap forward in technology integration.
Researchers can use HARPA AI for dataextraction and analysis for market research or competitive analysis to gather insights. The way it categorizes incoming emails automatically has also helped me maintain that elusive “inbox zero” I could only dream about.
Next, Amazon Comprehend or custom classifiers categorize them into types such as W2s, bank statements, and closing disclosures, while Amazon Textract extracts key details. Additional processing is needed to standardize formats, manage JSON outputs, and align data fields, often requiring manual integration and multiple API calls.
Enter generative AI, a groundbreaking technology that transforms how we approach dataextraction. For instance, they can: Sentiment Analysis : Determine the sentiment behind customer reviews, social media posts, or any other text-based data. What is Generative AI?
But its important to remember that without a variety of AI strategies and without a strong foundation of data to train and support the AI solutions, personalizing customer experiences with this technology is next to impossible. How does Akeneo optimize product discovery and search functionality using AI?
Researchers can use simple search queries to find what they're looking for and compare responses across different sessions to identify patterns or outliers in the data. Beyond basic tagging and categorization, Speech AI can also help with more nuanced parameters, such as speaker identification, sentiment, and thematic content.
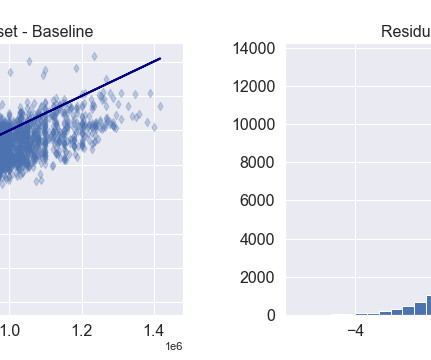
Consequently, in our case, the initial step in performing feature engineering is to group our features into three groups: categorical features, temporal features, and numerical features. Categorical Features Based on our analysis of categorical features, it is evident that ‘flat_type’ and ‘storey_range’ exhibit ordinal characteristics.
It examines how AI can optimize financial workflow processes by automatically summarizing documents, extractingdata, and categorizing information from email attachments. At the same time, the solution must provide data security, such as PII and SOC compliance.
Dataextraction Once you’ve assigned numerical values, you will apply one or more text-mining techniques to the structured data to extract insights from social media data. It also automates tasks like information extraction and content categorization. positive, negative or neutral).
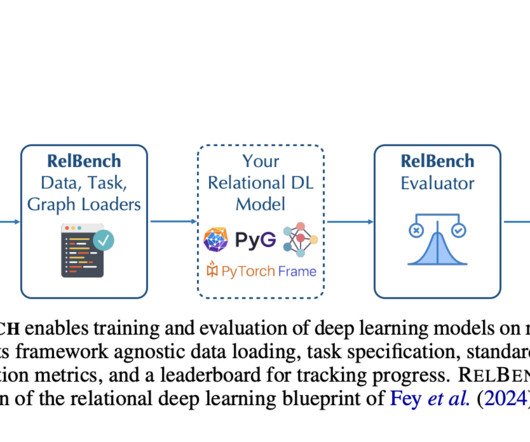
Traditional methods often flatten relational data into simpler formats, typically a single table. While simplifying data structure, this process leads to a substantial loss of predictive information and necessitates the creation of complex dataextraction pipelines.
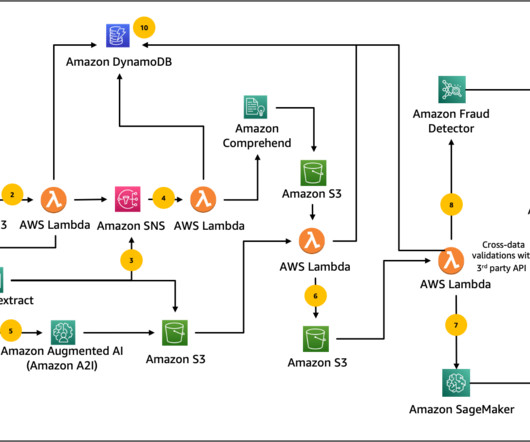
The variety of documents in this patient package demonstrates how a modern intelligent document processing solution must be flexible enough to handle different levels of document structure while maintaining consistency and accuracy in dataextraction. The following diagram illustrates the solution workflow.
Key Features: Real-time data replication and integration with major data warehouses. Cons: Confusing transformations, lack of pipeline categorization, view sync issues. It also offers EDI management features alongside data governance. Pros: Real-time updates, easy-to-use UI, seamless trial experience.
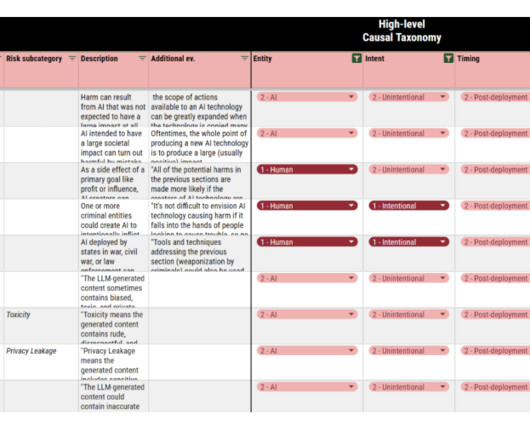
Although substantial research has identified and categorized these risks, a unified framework is needed to be consistent with terminology and clarity. Two taxonomies were developed: the Causal Taxonomy, categorizing risks by responsible entity, intent, and timing, and the Domain Taxonomy, classifying risks into specific domains.
Key Features: Real-time data replication and integration with major data warehouses. Cons: Confusing transformations, lack of pipeline categorization, view sync issues. Visit Hevo Data → 7. It also offers EDI management features alongside data governance. Visit SAP Data Services → 10.
In the accounts payable department, AI can benefit payment processing, invoice capture, dataextraction, invoice workflow automation , and even fraud detection. Data literacy: Data has always been essential in finance, but especially so now that many financial processes have gone fully digital.
Why it’s challenging to process and manage unstructured data Unstructured data makes up a large proportion of the data in the enterprise that can’t be stored in a traditional relational database management systems (RDBMS). Understanding the data, categorizing it, storing it, and extracting insights from it can be challenging.
Features include real-time OCR dataextraction from invoices, bills, and receipts, automatic transaction categorization, and AI-assisted reconciliation. The receipt’s merchant, date, amount, and category can all be automatically extracted using Nanonets Flow.
Our second use case focuses on first identifying the documents which involve mentions of biomarkers by using a text classifier and then extracting biomarker-related information from clinical reports, identifying key markers and their associated results, such as numeric values or categorical outcomes.
In the initialization phase, the system divides tasks into subtasks and assigns them to specialized agents, each with distinct roles like dataextraction, retrieval, and analysis. Marked features like the monitor mechanism and memory categorization contributed significantly to this success.
Provides data security using AI & blockchain technologies. Automates data collection from varied sources using extraction modules. Dataextraction, model training, and storage all served under one roof. Provides data security using AI & blockchain technologies. Strong community and tech support.
Named Entities in Clinical Data Abstraction based on NLP One of the most important tasks in NLP is named-entity recognition. Named entity recognition is a natural language processing technology that automatically scans full documents, extracts fundamental elements from the text, and categorizes them.
In this article, we will cover the third & fourth sections i.e. DataExtraction, Preprocessing & EDA & Machine Learning Model development Data collection : Automatically download the stock historical prices data in CSV format and save it to the AWS S3 bucket. And Deploy the final app on Streamlit Cloud.
Large language models (LLMs) like askFDALabel offer promise by streamlining dataextraction from FDA labels, achieving up to 78% agreement with human evaluations for cardiotoxicity. The model categorized toxicity using ternary (No, Less, Most) and binary (Yes, No) scales.
Sensitive dataextraction and redaction LLMs show promise for extracting sensitive information for redaction. Common applications include classifying the intents of user interactions via channels such as email, chatbots, voice, and others, or categorizing documents to route their requests to downstream systems.
Examples include: Categorizing incoming support tickets by relevant topics Classifying images of silicon wafers as containing defects or no defects Example of support ticket classification 2. Information Extraction (IE) An information extraction problem is about extracting specific information from large volumes of text data.
The core idea behind this phase is automating the categorization or classification using AI. We will specifically focus on the two most common uses: template-based normalized key-value entity extractions and document Q&A, with large language models.
Packages like dplyr and tidyr offer a wide range of functions for filtering, sorting, aggregating, merging, and reshaping data. These tools enable users to clean and preprocess data, extract relevant information, and create derived variables. · Reproducible Research: R promotes reproducible research through literate programming.
Developing a machine learning model requires a big amount of training data. Therefore, the data needs to be properly labeled/categorized for a particular use case. Companies can use high-quality human-powered data annotation services to enhance ML and AI implementations.
With its ability to understand context and relationships between extracted information, Amazon Comprehend Medical offers a robust solution for healthcare professionals and researchers looking to automate dataextraction, improve patient care, and streamline clinical workflows. not_matched : The entity was not detected at all.
In this article, we will explore a Python project called “GitHub Topics Scraper,” which leverages web scraping to extract information from the GitHub topics page and retrieve repository names and details for each topic. It offers a feature called “topics” that allows users to categorize repositories based on specific subjects or themes.
With its ability to understand context and relationships between extracted information, Amazon Comprehend Medical offers a robust solution for healthcare professionals and researchers looking to automate dataextraction, improve patient care, and streamline clinical workflows. not_matched : The entity was not detected at all.
Underwriters must review and analyze a wide range of documents submitted by applicants, and the manual extraction of relevant information is a time-consuming and error-prone task. This is a complex task when faced with unstructured data, varying document formats, and erroneous data.
We provide concrete guidance on addressing this issue with AWS AI and ML services to detect document tampering, identify and categorize patterns for fraudulent scenarios, and integrate with business-defined rules while minimizing human expertise for fraud detection. The status of the document processing job is tracked in Amazon DynamoDB.
For instance, tasks involving dataextraction, transfer, or essential decision-making based on predefined rules might not require complex algorithms and custom AI software. Companies also risk breaches, non-compliance, and potential reputational damage if they fail to develop a tailored approach to data handling.
For instance, tasks involving dataextraction, transfer, or essential decision-making based on predefined rules might not require complex algorithms and custom AI software. Companies also risk breaches, non-compliance, and potential reputational damage if they fail to develop a tailored approach to data handling.
When the network completes several transactions, a large amount of data is gathered, which may be processed and categorized using AI algorithms. Because AI is superior at pattern recognition and anomaly detection in massive volumes of data, Telcoin creators combined the capabilities of blockchain and AI.
Sounds crazy, but Wei Shao (Data Scientist at Hortifrut) and Martin Stein (Chief Product Officer at G5) both praised the solution. launched an initiative called ‘ AI 4 Good ‘ to make the world a better place with the help of responsible AI.
Task 1: Query generation from natural language This task’s objective is to assess a model’s capacity to translate natural language questions into SQL queries, using contextual knowledge of the underlying data schema. We use real incident data from Sophos’s MDR for incident summarization.
Entity Typing (ET): Categorizes entities into more fine-grained types (e.g., Great for researchers, data analysts, and anyone needing to visualize and explore the structure of large networks and knowledge graphs. scientists, artists).
Machine learning (ML) classification models offer improved categorization, but introduce complexity by requiring separate, specialized models for classification, entity extraction, and response generation, each with its own training data and contextual limitations. Built-in conditional logic handles different processing paths.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content