This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Discuss with stakeholders how accuracy and datadrift will be monitored. Typical data quality checks and corrections include: Missing data or incomplete records Inconsistent data formatting (e.g., mixture of dollars and euros in a currency field) Inconsistent coding of categoricaldata (e.g.,
Auto DataDrift and Anomaly Detection Photo by Pixabay This article is written by Alparslan Mesri and Eren Kızılırmak. Model performance may change over time due to datadrift and anomalies in upcoming data. This can be prevented using Google’s Tensorflow Data Validation library. which is odd.
If there are features related to network issues, those users are categorized as network issue-based users. The resultant categorization, along with the predicted churn status for each user, is then transmitted for campaign purposes. Datadrift and model drift are also monitored.
For instance, a notebook that monitors for model datadrift should have a pre-step that allows extract, transform, and load (ETL) and processing of new data and a post-step of model refresh and training in case a significant drift is noticed.
Describing the data As mentioned before, we will be using the data provided by Corporación Favorita in Kaggle. Dataset | Source: Author The data is complex as it has different categories of features. After deployment, we will monitor the model performance with the current best model and check for datadrift and model drift.
The following can be included as part of your Data Contract: Feature names Data types Expected distribution of values in each column. It can also include constraints on the data, such as: Minimum and maximum values for numerical columns Allowed values for categorical columns.
Also, in this phase, we clean the outliers, i.e., data points far from the observed distribution. Data Preparation in the form of a CSV file – Source Data transformation refers to aggregating data, dealing with categorical variables, and creating dummies to ensure consistency. from mlxtend.
Not only do you want to know what features are causing this or impacting the performance, but potentially you even want to know what values of this feature or (if it’s a categorical feature) what categories of this feature are having the most impact on performance. Drift is fundamentally a comparison between two datasets.
Not only do you want to know what features are causing this or impacting the performance, but potentially you even want to know what values of this feature or (if it’s a categorical feature) what categories of this feature are having the most impact on performance. Drift is fundamentally a comparison between two datasets.
Not only do you want to know what features are causing this or impacting the performance, but potentially you even want to know what values of this feature or (if it’s a categorical feature) what categories of this feature are having the most impact on performance. Drift is fundamentally a comparison between two datasets.
All of these files have a combination of numeric, categorical, and date features, but remember that DataRobot can also handle images, text and location features. A look at datadrift. A clear picture of the model’s accuracy.
The ELT architecture and its type differ from organization to organization as they have different sets of tech stack, data sources, and business requirements. ETL pipelines can be categorized based on the type of data being processed and how it is being processed. What are the different types of ETL pipelines in ML?
But there needs to be some priority order by which we consider how to build a feature library, how to group features and categorize them, and then how to join features at different scales—maybe at a customer scale or at a process level. How are you looking at model evaluation for cases where data adapts rapidly? I can briefly start.
But there needs to be some priority order by which we consider how to build a feature library, how to group features and categorize them, and then how to join features at different scales—maybe at a customer scale or at a process level. How are you looking at model evaluation for cases where data adapts rapidly? I can briefly start.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



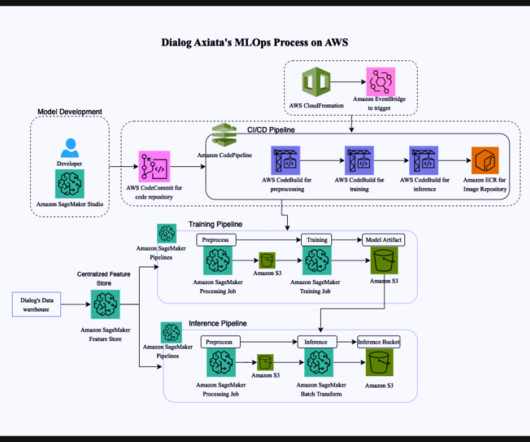






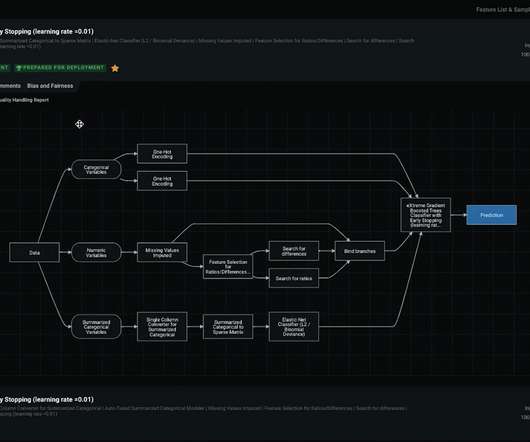









Let's personalize your content