This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Python has become the go-to language for dataanalysis due to its elegant syntax, rich ecosystem, and abundance of powerful libraries. Datascientists and analysts leverage Python to perform tasks ranging from data wrangling to machine learning and data visualization.
For instance, if datascientists were building a model for tornado forecasting, the input variables might include date, location, temperature, wind flow patterns and more, and the output would be the actual tornado activity recorded for those days. the target or outcome variable is known). temperature, salary).
In the domain of reasoning under uncertainty, probabilistic graphical models (PGMs) have long been a prominent tool for dataanalysis. Many graphical models are designed to work exclusively with continuous or categorical variables, limiting their applicability to data that spans different types.
Summary: The Data Science and DataAnalysis life cycles are systematic processes crucial for uncovering insights from raw data. Quality data is foundational for accurate analysis, ensuring businesses stay competitive in the digital landscape. billion INR by 2026, with a CAGR of 27.7%.
Making visualizations is one of the finest ways for datascientists to explain dataanalysis to people outside the business. Exploratory dataanalysis can help you comprehend your data better, which can aid in future data preprocessing. Exploratory DataAnalysis What is EDA?
Figure 3: The required python libraries The problem presented to us is a predictive analysis problem which means that we will be heavily involved in finding patterns and predictions rather than seeking recommendations. One important stage of any dataanalysis/science project is EDA. Exploratory DataAnalysis is a pre-study.
A cheat sheet for DataScientists is a concise reference guide, summarizing key concepts, formulas, and best practices in DataAnalysis, statistics, and Machine Learning. What are Cheat Sheets in Data Science? It includes data collection, data cleaning, dataanalysis, and interpretation.
Intro to Deep Learning with PyTorch and TensorFlow Dr. Jon Krohn | Chief DataScientist | Nebula.io In recent years, Deep Learning has become ubiquitous across a wide range of data-driven applications.
Microsoft Power BI Microsoft Power BI, a powerful business intelligence platform that lets users filter through data and visualize it for insights, is another top AI tool for dataanalysis. Users may import data from practically anywhere into the platform and immediately create reports and dashboards.
Summary: This article explores different types of DataAnalysis, including descriptive, exploratory, inferential, predictive, diagnostic, and prescriptive analysis. Introduction DataAnalysis transforms raw data into valuable insights that drive informed decisions. What is DataAnalysis?
DataScientists are highly in demand across different industries for making use of the large volumes of data for analysisng and interpretation and enabling effective decision making. One of the most effective programming languages used by DataScientists is R, that helps them to conduct dataanalysis and make future predictions.
Data Wrangler simplifies the data preparation and feature engineering process, reducing the time it takes from weeks to minutes by providing a single visual interface for datascientists to select and clean data, create features, and automate data preparation in ML workflows without writing any code.
As a datascientist, we will explore the entire data set to understand each characteristic and identify any patterns existing if any in it. This process is called Exploratory DataAnalysis(EDA). Step III: Data organization and Feature Engineering This is a crucial step to get accurate results.
Information retrieval The first step in the text-mining workflow is information retrieval, which requires datascientists to gather relevant textual data from various sources (e.g., The data collection process should be tailored to the specific objectives of the analysis. positive, negative or neutral).
Monitoring and Compliance Nonprofits can use benchmarking and data science to measure their operations’ effectiveness precisely and customize their workflows for improved outcomes. Real-time tracking during emergencies and optimizing rescue efforts can benefit greatly from dataanalysis and visualization.
Moreover, using sentiment analysis techniques, organizations can gain valuable insights into customer satisfaction, identify trends, and make data-driven improvements. Topic Modeling With text mining, it is possible to identify and categorize topics and themes within large collections of documents. Wrapping it up !!!
Dr. Jon Krohn Chief DataScientist | Nebula.io He also shares his expertise with the data science community at conferences. However, our speakers are also experienced and acclaimed instructors, able to impart their knowledge in a manner that is engaging and effective.
Dataanalysis helps organizations make informed decisions by turning raw data into actionable insights. With businesses increasingly relying on data-driven strategies, the demand for skilled data analysts is rising. You’ll learn the fundamentals of gathering, cleaning, analyzing, and visualizing data.
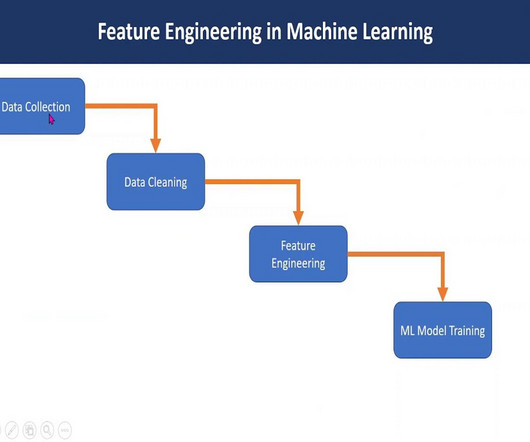
It involves steps like handling missing values, normalizing data, and managing categorical features, ultimately enhancing model performance and ensuring data quality. Introduction Data preprocessing is a critical step in the Machine Learning pipeline, transforming raw data into a clean and usable format.
The company’s H20 Driverless AI streamlines AI development and predictive analytics for professionals and citizen datascientists through open source and customized recipes. The platform makes collaborative data science better for corporate users and simplifies predictive analytics for professional datascientists.
This definition covers everything from the point of acquiring data to the point at which a datascientist exports a model for deployment. For most of machine learning’s history, datascientists treated data as a static resource; it came pre-labeled by business or data collection processes.
This definition covers everything from the point of acquiring data to the point at which a datascientist exports a model for deployment. For most of machine learning’s history, datascientists treated data as a static resource; it came pre-labeled by business or data collection processes.
This definition covers everything from the point of acquiring data to the point at which a datascientist exports a model for deployment. For most of machine learning’s history, datascientists treated data as a static resource; it came pre-labeled by business or data collection processes.
It natively supports only numerical data, so typically an encoding is applied first for converting the categoricaldata into a numerical form. Shallow and Deep Clustering Clustering algorithms can be categorized into two types based on their approach to learning: shallow learning and deep learning. this link ).
Deep Learning with PyTorch and TensorFlow part 1 and 2 Dr. Jon Krohn | Chief DataScientist | Nebula.io Jon Krohn | Chief DataScientist | Nebula.io Intermediate Machine Learning with scikit-learn: Pandas Interoperability, CategoricalData, Parameter Tuning, and Model Evaluation Thomas J.
Supervised learning is a type of machine learning algorithm that learns from a set of training data that has been labeled training data. Evaluate the model: After training, the model evaluation is required to determine how well it performs on new, unlabeled data. What is supervised learning?
Feature engineering in machine learning is a pivotal process that transforms raw data into a format comprehensible to algorithms. Through Exploratory DataAnalysis , imputation, and outlier handling, robust models are crafted. Encoding categorical variables: The language of algorithms Machines comprehend numbers, not labels.
This time, I embarked on a Data Science journey with British Airways (BA). As a datascientist at BA, our job will be to apply our dataanalysis and machine learning skills to derive insights that help BA drive revenue upwards. This is a perfect way to showcase your skills and build up your portfolio!
As a programming language it provides objects, operators and functions allowing you to explore, model and visualise data. The programming language can handle Big Data and perform effective dataanalysis and statistical modelling. R’s workflow support enhances productivity and collaboration among datascientists.
These communities will help you to be updated in the field, because there are some experienced datascientists posting the stuff, or you can talk with them so they will also guide you in your journey. DataAnalysis After learning math now, you are able to talk with your data.
So, for anyone who is looking forward to making a career in Data Science, having mathematical expertise is paramount. Through this blog, we take you through the prerequisites of mathematics for Data science and other skills that will make you a successful Datascientist. Why Data Science?
Jason Goldfarb, senior datascientist at State Farm , gave a presentation entitled “Reusable Data Cleaning Pipelines in Python” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. It has always amazed me how much time the data cleaning portion of my job takes to complete.
Jason Goldfarb, senior datascientist at State Farm , gave a presentation entitled “Reusable Data Cleaning Pipelines in Python” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. It has always amazed me how much time the data cleaning portion of my job takes to complete.
Jason Goldfarb, senior datascientist at State Farm , gave a presentation entitled “Reusable Data Cleaning Pipelines in Python” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. It has always amazed me how much time the data cleaning portion of my job takes to complete.
Introduction Python is the most popularly used programming language by DataScientists that help them in conducting different operations and tasks from simple scripting to complex web application development and dataanalysis. The following blog will help you understand the process of tabulation of data in Python.
At ODSC West’s Mini-Bootcamp , from October 30th to November 2nd, you’ll have the opportunity to explore many different topics, build new skills and connect with datascientists and experts from a wide range of disciplines in just 4 days and for a lower cost. What is included in a Mini-Bootcamp Pass? Discover below.
Here are some reasons highlighting the significance of Data Visualization in Data Science: Data Understanding and Exploration: Data Visualization helps in gaining a deeper understanding of the data by visually representing patterns, trends, and relationships that may not be apparent in raw data.
Participate in Tutorial Kaggle Competitions (Compete with Fellow Kagglers) Kaggle competitions are categorized into different types. Before undertaking an independent data science project, try to complete Knowledge competitions (for knowledge purposes only) and collaborate with fellow datascientists.
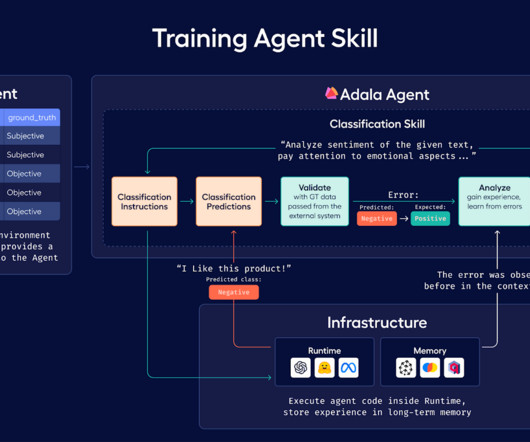
In this guest post, Jimmy Whitaker, DataScientist in Residence at Human Signal, focuses on guiding users in building an agent using the Adala framework. He dives into the integration of Large Language Model-based agents for automating data pipelines, particularly for tasks like data labeling.
Researchers across disciplines will find valuable insights to enhance their DataAnalysis skills and produce credible, impactful findings. Introduction Statistical tools are essential for conducting data-driven research across various fields, from social sciences to healthcare.
Statistics and statistical analysis are integral when it comes to Data Science. It is the underpinning of the successful analysis of any data set. Studying these variables and drawing inferences is the core task of a DataScientists. These variables can be used for analyzing trends, and patterns in data.
Python for Data Science Python has become the go-to programming language for Data Science due to its simplicity, versatility, and powerful libraries. It is widely recognised for its role in Machine Learning, data manipulation, and automation, making it a favourite among DataScientists, developers, and researchers.
Understanding their differences helps datascientists choose the right tool for creating compelling visualisations that effectively communicate insights. Introduction Data visualisation is a crucial aspect of DataAnalysis, enabling researchers and analysts to interpret complex datasets and communicate findings effectively.
Both agglomerative and divisive methods offer unique ways to explore data structure and uncover hidden patterns. Understanding these approaches helps choose the right method for different types of dataanalysis. You can apply it to numeric, categorical, or even a mix of both.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content