This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the ever-evolving field of computervision, a pressing concern is the imperative to ensure fairness. They commence by making DINOv2, an advanced computervision model forged through the crucible of self-supervised learning, accessible to a broader audience under the open-source Apache 2.0
Specifically, we cover the computervision and artificial intelligence (AI) techniques used to combine datasets into a list of prioritized tasks for field teams to investigate and mitigate. The workforce created a bounding box around stay wires and insulators and the output was subsequently used to train an ML model.
This system, the first Gym environment for ML tasks, facilitates the study of RL techniques for training AI agents. The benchmark, MLGym-Bench, includes 13 open-ended tasks spanning computervision, NLP, RL, and game theory, requiring real-world research skills. Check out the Paper and GitHub Page.
This article covers an extensive list of novel, valuable computervision applications across all industries. Find the best computervision projects, computervision ideas, and high-value use cases in the market right now. provides Viso Suite , the world’s only end-to-end ComputerVision Platform.
Are you overwhelmed by the recent progress in machine learning and computervision as a practitioner in academia or in the industry? Motivation Recent updates in machine learning (ML) and computervision (CV) are a mouthful, from Stable Diffusion for generative artificial intelligence (AI) to Segment Anything as foundation models.
As an Edge AI implementation, TensorFlow Lite greatly reduces the barriers to introducing large-scale computervision with on-device machine learning, making it possible to run machine learning everywhere. About us: At viso.ai, we power the most comprehensive computervision platform Viso Suite. What is TensorFlow?
Machine learning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computervision , large language models (LLMs), speech recognition, self-driving cars and more. What is machine learning? temperature, salary).
In the field of computervision, supervised learning and unsupervised learning are two of the most important concepts. In this guide, we will explore the differences and when to use supervised or unsupervised learning for computervision tasks. We will also discuss which approach is best for specific applications.
The researchers used computervision to facilitate this process. Classical computervision systems need to be retrained every time a new variety is delivered. Meet the PseudoAugment ComputerVision Approach appeared first on MarkTechPost. If you like our work, you will love our newsletter.
It often requires managing multiple machine learning (ML) models, designing complex workflows, and integrating diverse data sources into production-ready formats. Next, Amazon Comprehend or custom classifiers categorize them into types such as W2s, bank statements, and closing disclosures, while Amazon Textract extracts key details.
Intuitivo, a pioneer in retail innovation, is revolutionizing shopping with its cloud-based AI and machine learning (AI/ML) transactional processing system. At Intuitivo, we believe that the future of retail lies in creating highly personalized, AI-powered, and computervision-driven autonomous points of purchase (A-POP).
According to IBM, Object detection is a computervision task that looks for items in digital images. In this sense, it is an example of artificial intelligence that is, teaching computers to see in the same way as people do, namely by identifying and categorizing objects based on semantic categories.
This tagging structure categorizes costs and allows assessment of usage against budgets. ListTagsForResource : Fetches the tags associated with a specific Bedrock resource, helping users understand how their resources are categorized. He focuses on Deep learning including NLP and ComputerVision domains.
Addressing this challenge, researchers from Eindhoven University of Technology have introduced a novel method that leverages the power of pre-trained Transformer models, a proven success in various domains such as ComputerVision and Natural Language Processing. If you like our work, you will love our newsletter.
PEFT’s applicability extends beyond Natural Language Processing (NLP) to computervision (CV), garnering interest in fine-tuning large-parameter vision models like Vision Transformers (ViT) and diffusion models, as well as interdisciplinary vision-language models. Also, don’t forget to follow us on Twitter.
In computervision, convolutional networks acquire a semantic understanding of images through extensive labeling provided by experts, such as delineating object boundaries in datasets like COCO or categorizing images in ImageNet. Join our 37k+ ML SubReddit , 41k+ Facebook Community, Discord Channel , and LinkedIn Gr oup.
Computervision (CV) is a rapidly evolving area in artificial intelligence (AI), allowing machines to process complex real-world visual data in different domains like healthcare, transportation, agriculture, and manufacturing. Future trends and challenges Viso Suite is an end-to-end computervision platform.
Recently, the fields of computervision and machine learning have been gaining traction in agriculture. ComputerVision (CV) technology is changing the way agriculture operates by allowing for non-contact and scalable sensing solutions. provides the leading end-to-end ComputerVision Platform Viso Suite.
Bias detection in ComputerVision (CV) aims to find and eliminate unfair biases that can lead to inaccurate or discriminatory outputs from computervision systems. Computervision has achieved remarkable results, especially in recent years, outperforming humans in most tasks. Let’s get started.
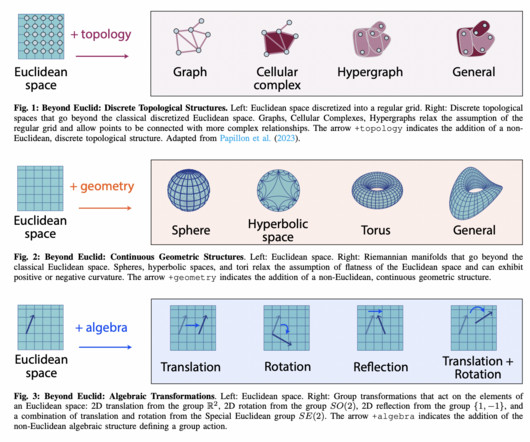
These methods work well for many conventional applications but struggle with non-Euclidean data, which is common in fields such as neuroscience, physics, and advanced computervision. Traditional machine learning methods have been predominantly based on Euclidean geometry, where data lies in flat, straight-lined spaces.
Machine learning (ML) projects are inherently complex, involving multiple intricate steps—from data collection and preprocessing to model building, deployment, and maintenance. To start our ML project predicting the probability of readmission for diabetes patients, you need to download the Diabetes 130-US hospitals dataset.
Machine learning (ML) and deep learning (DL) form the foundation of conversational AI development. ML algorithms understand language in the NLU subprocesses and generate human language within the NLG subprocesses. DL, a subset of ML, excels at understanding context and generating human-like responses.
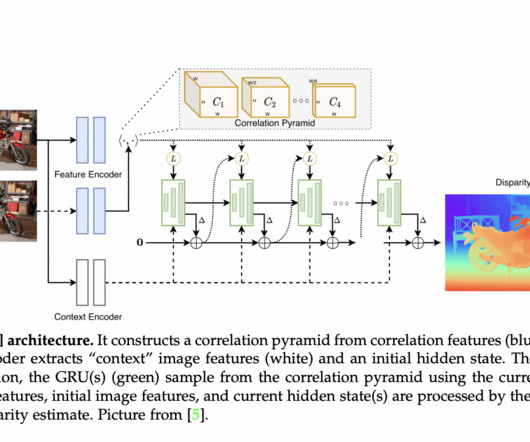
A fundamental topic in computervision for nearly half a century, stereo matching involves calculating dense disparity maps from two corrected pictures. According to their cost-volume computation and optimization methodologies, existing surveys categorize end-to-end architectures into 2D and 3D classes.
Power Sector Priorities to Increase Renewable Energy Production – Source Computervision methods have great potential for gathering useful data from digital images and videos. How is ComputerVision Used in Renewables? Thus, both energy providers and customers need better short-term production, demand, and forecasting.
In recent years, computervision and generative modeling have witnessed remarkable progress, leading to advancements in text-to-image generation. These diffusion models, categorized as pixel-level and latent-level, excel in image generation, surpassing GANs in fidelity and diversity. Check out the Paper and Github.
From surveillance systems that safeguard our cities to autonomous vehicles navigating our roads, object tracking has emerged as a fundamental technology in computervision. Object tracking is an essential application of deep learning extensively used in computervision. What is Object Tracking?
This article covers everything you need to know about image classification – the computervision task of identifying what an image represents. provides the end-to-end ComputerVision Platform Viso Suite. It’s a powerful all-in-one solution for AI vision. How Does Image Classification Work?
ComputerVision for Cultural Heritage Preservation: Unlocking the Past with Advanced Imaging Technology Image Source: Technology Innovators Preserving our cultural legacy is critical because it allows us to remain in touch with our past, learn our roots, and appreciate humanity's rich history.
Traditional computer programs couldn’t do this well. Researchers also categorized the type of spine curve just by looking at one picture. This problem statement fell under the class of ComputerVision and was a classification approach. Check out the Paper. If you like our work, you will love our newsletter.
Machine learning (ML)—the artificial intelligence (AI) subfield in which machines learn from datasets and past experiences by recognizing patterns and generating predictions—is a $21 billion global industry projected to become a $209 billion industry by 2029. At Facebook Messenger, ML powers customer service chatbots.
For instance, in ecommerce, image-to-text can automate product categorization based on images, enhancing search efficiency and accuracy. In a previous post, we proposed a content moderation solution based on the BLIP model that addressed multiple challenges using computervision unimodal ML approaches.
Image annotation is the process of labeling or categorizing an image with descriptive data that helps identify and classify objects, people, and situations included within the image. Since it helps robots understand and interpret visual input, image annotation is vital in computervision, robotics, and autonomous driving.
Not only Language processing, these models have also gained success in the field of Computervision. The team has shared how Semantic-SAM tackles the problem of semantic awareness by using a decoupled categorization strategy for parts and objects. Check out the Paper and GitHub link.
Manually analyzing and categorizing large volumes of unstructured data, such as reviews, comments, and emails, is a time-consuming process prone to inconsistencies and subjectivity. The following table compares the generative approach (generative AI) with the discriminative approach (traditional ML) across multiple aspects.
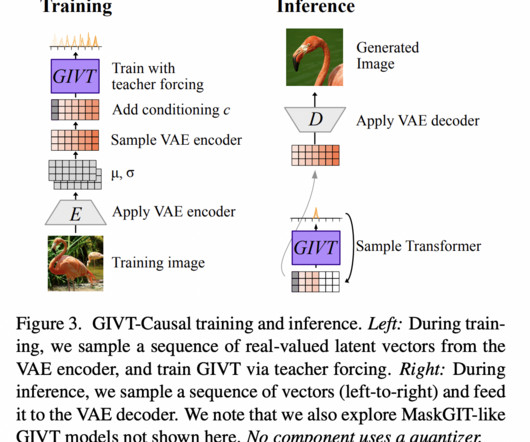
More lately, they have gained immense popularity in computervision as well. Instead of predicting a categorical distribution over a finite vocabulary, GIVT predicts the parameters of a continuous distribution over real-valued vectors at the output. Dosovitskiy et al. As seen in Fig. Check out the Paper.
It is known that, similar to the human brain, AI systems employ strategies for analyzing and categorizing images. The study was also presented at the esteemed ComputerVision and Pattern Recognition Conference, 2023, held in Canada. the team strongly believes that these systems hold the promise to transform numerous fields.
Many computervision problems fall into two basic categories: discriminative or generative. Recent research has made significant strides by performing well in generation and categorization, both with and without supervision. Their categorization potential is, however, mostly untapped and unstudied. Check out the Paper.
However, despite the innumerable sensors, plethora of cameras, and expensive computervision techniques, this integration poses a few critical questions. Currently, this CNN is trained on a COCO dataset that categorizes around 80 objects. If you like our work, you will love our newsletter. Let’s collaborate!
Source: [link] Computervision is an interesting field in machine learning as it helps computers understand what they see. Computervision has various sub-topics like segmentation, object detection, image synthesis, etc. Image classifiers are considered the basis of other computervision problems.
provides Viso Suite , the world’s only end-to-end ComputerVision Platform. The solution enables teams worldwide to develop and deliver custom real-world computervision applications. Hence, pattern recognition is broader compared to computervision which focuses on image recognition.
Posted by Shaina Mehta, Program Manager, Google This week marks the beginning of the premier annual ComputerVision and Pattern Recognition conference (CVPR 2023), held in-person in Vancouver, BC (with additional virtual content).
Research has highlighted the potential of KANs in various fields, like computervision, time series analysis, and quantum architecture search. A standardized preprocessing method is applied across all datasets, which includes categorical feature encoding, missing value imputation, and instance randomization.
These services use advanced machine learning (ML) algorithms and computervision techniques to perform functions like object detection and tracking, activity recognition, and text and audio recognition. The following graphic is a simple example of Windows Server Console activity that could be captured in a video recording.
Computervision tasks like autonomous driving, object segmentation, and scene analysis can negatively impact this effect, which blurs or stretches the image’s object contours, diminishing their clarity and detail. The researchers present a categorization system that uses backbone networks to organize these methods.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content