This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Python has become the go-to language for dataanalysis due to its elegant syntax, rich ecosystem, and abundance of powerful libraries. Data scientists and analysts leverage Python to perform tasks ranging from data wrangling to machine learning and data visualization.
In the field of computervision, supervised learning and unsupervised learning are two of the most important concepts. In this guide, we will explore the differences and when to use supervised or unsupervised learning for computervision tasks. We will also discuss which approach is best for specific applications.
Machine learning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computervision , large language models (LLMs), speech recognition, self-driving cars and more. However, the growing influence of ML isn’t without complications.
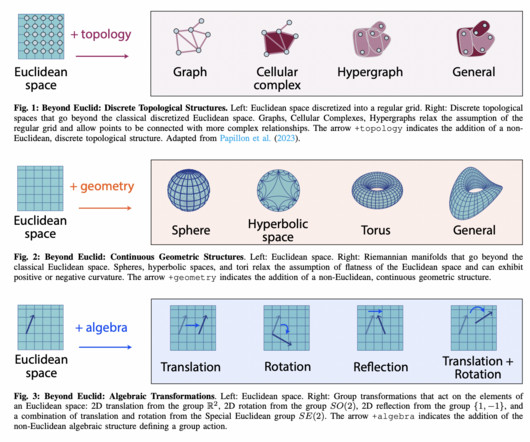
Traditional machine learning methods have been predominantly based on Euclidean geometry, where data lies in flat, straight-lined spaces. These methods work well for many conventional applications but struggle with non-Euclidean data, which is common in fields such as neuroscience, physics, and advanced computervision.
Computervision is a key component of self-driving cars. To obtain this data, a vehicle makes use of cameras and sensors. In this article, we’ll elaborate on how computervision enhances these cars. To accomplish this, they require two key components: machine learning and computervision.
Bias detection in ComputerVision (CV) aims to find and eliminate unfair biases that can lead to inaccurate or discriminatory outputs from computervision systems. Computervision has achieved remarkable results, especially in recent years, outperforming humans in most tasks. Let’s get started.
Blockchain technology can be categorized primarily on the basis of the level of accessibility and control they offer, with Public, Private, and Federated being the three main types of blockchain technologies. Large-scale dataanalysis methods that offer privacy protection by utilizing both blockchain and AI technology.
This article covers everything you need to know about image classification – the computervision task of identifying what an image represents. provides the end-to-end ComputerVision Platform Viso Suite. It’s a powerful all-in-one solution for AI vision. How Does Image Classification Work?
Pattern Recognition in DataAnalysis What is Pattern Recognition? provides Viso Suite , the world’s only end-to-end ComputerVision Platform. The solution enables teams worldwide to develop and deliver custom real-world computervision applications. How does Pattern Recognition Work? What Is a Pattern?
If you are a regular PyImageSearch reader and have even basic knowledge of Deep Learning in ComputerVision, then this tutorial should be easy to understand. But we would still apply data augmentation to ensure the model doesn’t overfit and generalize well on the test dataset. Or requires a degree in computer science?
Manually analyzing and categorizing large volumes of unstructured data, such as reviews, comments, and emails, is a time-consuming process prone to inconsistencies and subjectivity. We provide a prompt example for feedback categorization. For more information, refer to Prompt engineering. No explanation is required.
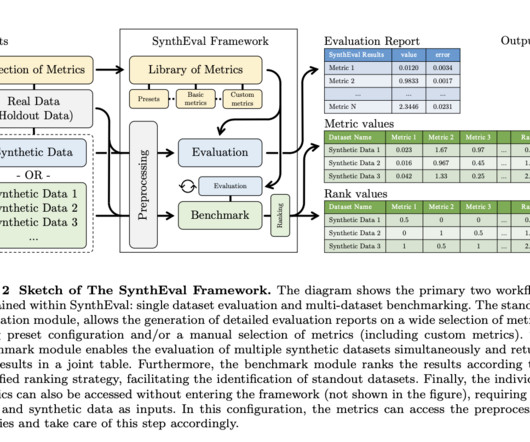
Computervision, machine learning, and dataanalysis across many fields have all seen a surge in the usage of synthetic data in the past few years. Concerning tabular data, one of the biggest obstacles is maintaining consistency when dealing with fluctuating percentages of numerical and categoricaldata.
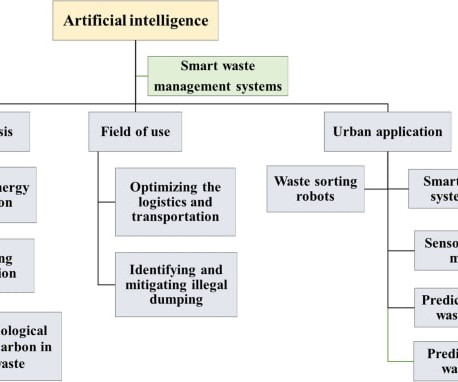
This is where computervision technology can help identify waste, separate it, and ensure its proper disposal. In this article, we will propose computervision as an effective tool for waste management. For truly solving real-world scenarios, organizations require more than just a computervision tool or algorithm.
This article explores Kaggle, a popular platform for learning everything related to Data Science, ComputerVision (CV), and Machine Learning. Learning pre-trained models will save a lot of time and resources when working on computervision tasks. Reproduce already available solutions as well.
In the following, we will explore Convolutional Neural Networks (CNNs), a key element in computervision and image processing. Viso Suite enables the use of neural networks for computervision with no code. Le propose architectures that balance accuracy and computational efficiency. Learn more and request a demo.
Therefore, it mainly deals with unlabelled data. The ability of unsupervised learning to discover similarities and differences in data makes it ideal for conducting exploratory dataanalysis. Acquiring unlabelled data from computer systems is easier than labeled data.
Data Augmentation Generative models can generate additional training examples, improving the performance of other machine learning models. By applying generative models in these areas, researchers and practitioners can unlock new possibilities in various domains, including computervision, natural language processing, and dataanalysis.
Task like building a section of a software or a part of another code can be categorized under Modular Task’s. ComputerVision The golden rule is to balance both. Then there is also Experimental Tasks where the next step is dependent on the previous step and there is no fix flow for the execution of code.
At its core, data science is all about discovering useful patterns in data and presenting them to tell a story or make informed decisions. provides a robust end-to-end no-code computervision solution – Viso Suite. Also, in this phase, we clean the outliers, i.e., data points far from the observed distribution.
Most conventional AI-powered tools only use genre or artist as relevant factors in their training data. This ANN’s training involves understanding and categorizing music based on human perceptions and emotions. Emotional Perception AI Ltd argues that this is going a step beyond conventional categorization.
Characteristics of remote sensing data When it comes to working with remote sensing data and deep learning techniques, several things need to be considered since remotely sensed data is quite different from common images in computervision. Here are some characteristics of remote sensing data: Multiple modalities.
Kaggle: Kaggle is a popular site for data science competitions. The Kaggle tournaments include an extensive variety of disciplines, including picture categorization, text analysis, and time series forecasting, among others. Data Hack: DataHack is a web-based platform that offers data science competitions and hackathons.
By the end of the lesson, readers will have a solid grasp of the underlying principles that enable these applications to make suggestions based on dataanalysis. Do you think learning computervision and deep learning has to be time-consuming, overwhelming, and complicated? Or requires a degree in computer science?
Numerous industries have undergone a revolution because of their quick improvements, which have also greatly improved automation and visual dataanalysis capabilities. IR, also known as computervision, is a field of AR that involves computers’ automatic interpretation and understanding of images.
Anomaly detection ( Figure 2 ) is a critical technique in dataanalysis used to identify data points, events, or observations that deviate significantly from the norm. Figure 4: Categorization of Anomalies based on type, latency, application, and method (source: ScienceDirect ). Or requires a degree in computer science?
Categorical Features (Nominal vs. Ordinal) Categorical features group data into distinct categories or classes, often representing qualitative attributes. Handling categoricaldata appropriately is essential for ensuring accurate interpretations by Machine Learning models.
Key takeaways: In the age of Generative AI, we moved from the focus on perception in vision models (i.e., For 20 years, computervision was focused on benchmark research, which helped to focus on the most prominent problems. The main idea is to use insights from adaptive dataanalysis.
Using deep learning, computers can learn and recognize patterns from data that are considered too complex or subtle for expert-written software. In this workshop, you’ll learn how deep learning works through hands-on exercises in computervision and natural language processing.
In the current Artificial Intelligence and Machine Learning industry, “ Image Recognition ”, and “ ComputerVision ” are two of the hottest trends. Despite some similarities, both computervision and image recognition represent different technologies, concepts, and applications. What is ComputerVision?
This made them ideal for trend analysis, business reporting, and decision support. The development of data warehouses marked a shift in how businesses used data, moving from transactional processing to dataanalysis and decision support. ComputerVision algorithms can be employed for image recognition and analysis.
In this educated example , the aim is to predict home prices at the property level in the city of Madrid and the training dataset contains 5 different data types (numerical, categorical, text, location, and images) and +90 variables that are related to these 5 different groups: Market performance. Property performance.
The following Venn diagram depicts the difference between data science and data analytics clearly: 3. Dataanalysis can not be done on a whole volume of data at a time especially when it involves larger datasets. This is where the importance of having proper and clean data comes into the picture.
It is commonly used in computervision applications, such as object detection, image recognition, and image compression. Biological DataAnalysis: Agglomerative Clustering is widely used in bioinformatics for analyzing gene expression data, protein sequence analysis, and clustering biological samples based on their characteristics.
In this article, we present a comprehensive overview of the most commonly used data visualization functions and tools, with a particular focus on their applications in machine learning projects, especially those involving computervision. What is data visualization? What are popular Python data visualization libraries?
Session 2: Bayesian Analysis of Survey Data: Practical Modeling withPyMC Unlock the power of Bayesian inference for modeling complex categoricaldata using PyMC. As the author of *Hands-On DataAnalysis with Pandas* (now in its second edition), she is a recognized expert in making data actionable.
Professionals known as data analysts enable this by turning complicated raw data into understandable, useful insights that help in decision-making. They navigate the whole dataanalysis cycle, from discovering and collecting pertinent data to getting it ready for analysis, interpreting the findings, and formulating suggestions.
Microsoft Power BI For businesses looking to integrate AI and improve their dataanalysis capabilities, Microsoft Power BI is a crucial tool. Its advanced text analysis features allow users to extract significant phrases and do sentiment analysis, improving the overall caliber of data insights.
They’re the perfect fit for: Image, video, text, data & lidar annotation Audio transcription Sentiment analysis Content moderation Product categorization Image segmentation iMerit also specializes in extraction and enrichment for ComputerVision , NLP , data labeling, and other technologies.
The primary goal of AI is to create computer systems that can perform tasks that would typically require human intelligence, such as reasoning, problem-solving, learning, understanding natural language, and adapting to new situations. This enables applications such as facial recognition, object detection, and image understanding.
Let’s explore its ideal applications and the types of tasks and data it excels at. Key Applications of SVM Text Classification SVM is widely used for categorizing text documents, such as spam email detection or topic classification. SVM works best with well-defined classes, clear decision boundaries, and a moderate amount of data.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content